Downloaded 192 times
















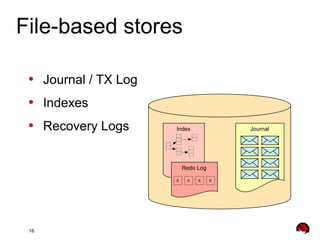








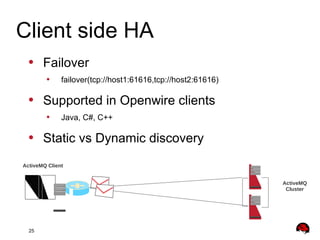
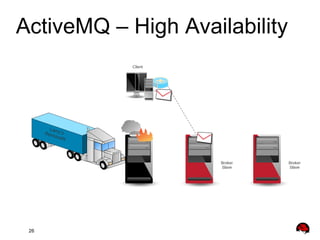
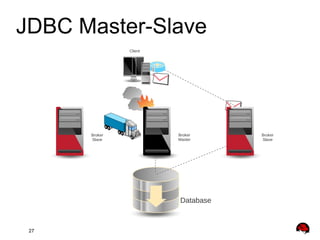

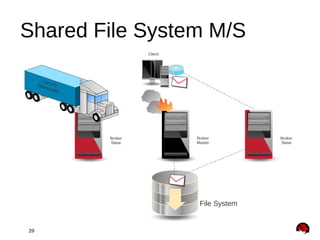

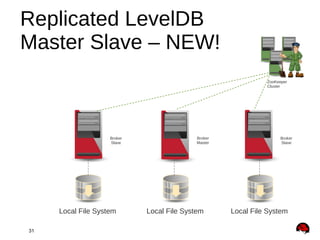
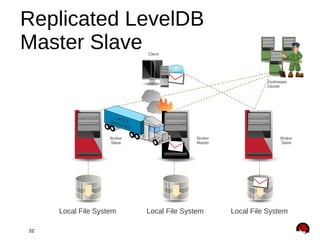



















This document provides an overview and agenda for a presentation on Apache ActiveMQ 5.9.x and Apache Apollo. The presentation will cover new features in ActiveMQ 5.9.x including AMQP 1.0 support, REST management, a new default file-based store using LevelDB, and high availability replication of the store. It will also introduce Apache Apollo and allow for a question and discussion period.

























































![Jms deep dive [con4864]](https://cdn.slidesharecdn.com/ss_thumbnails/jmsdeepdivecon4864-160927041349-thumbnail.jpg?width=640&height=640&fit=bounds)

















































