Download as PDF, PPTX


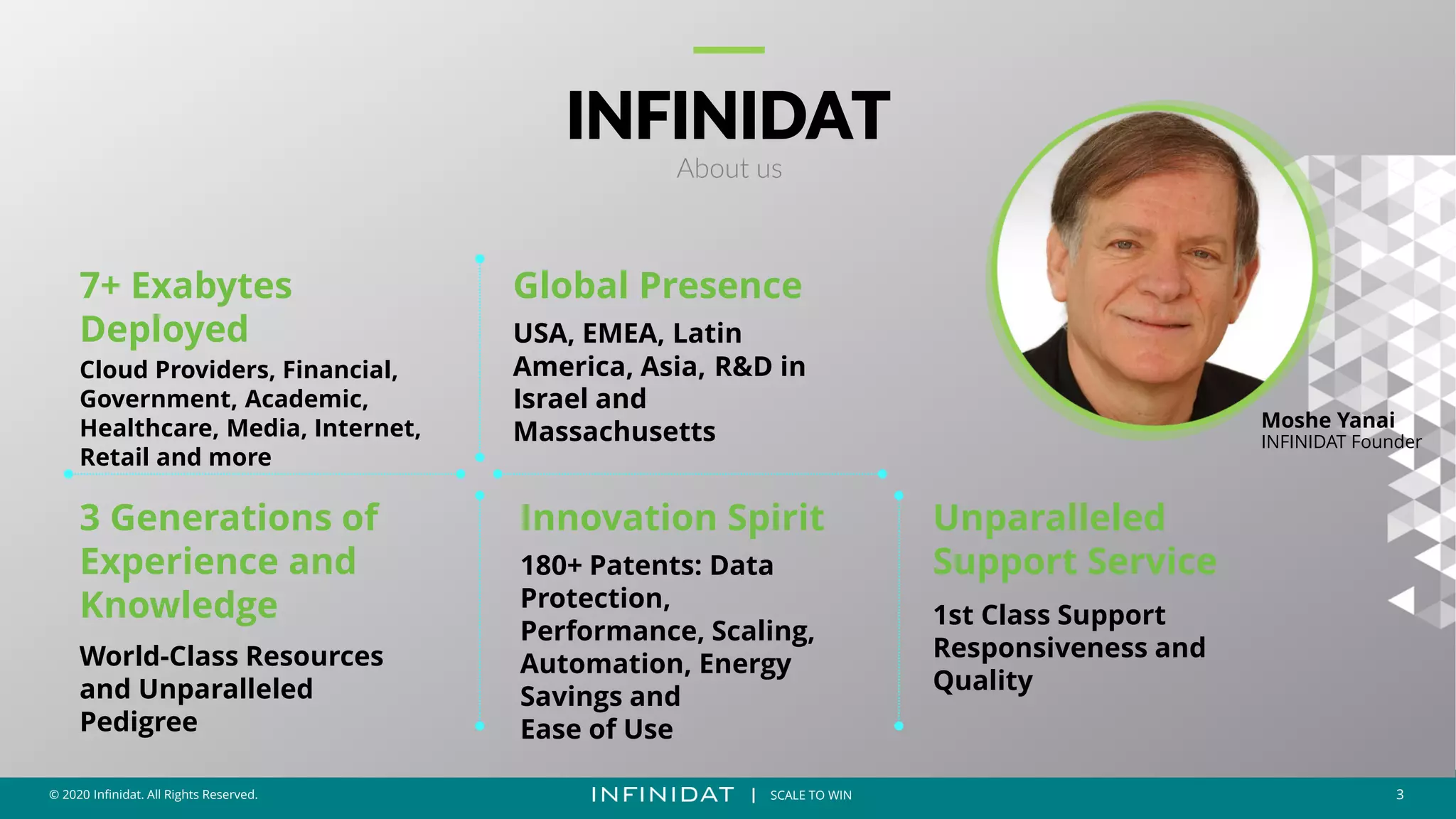
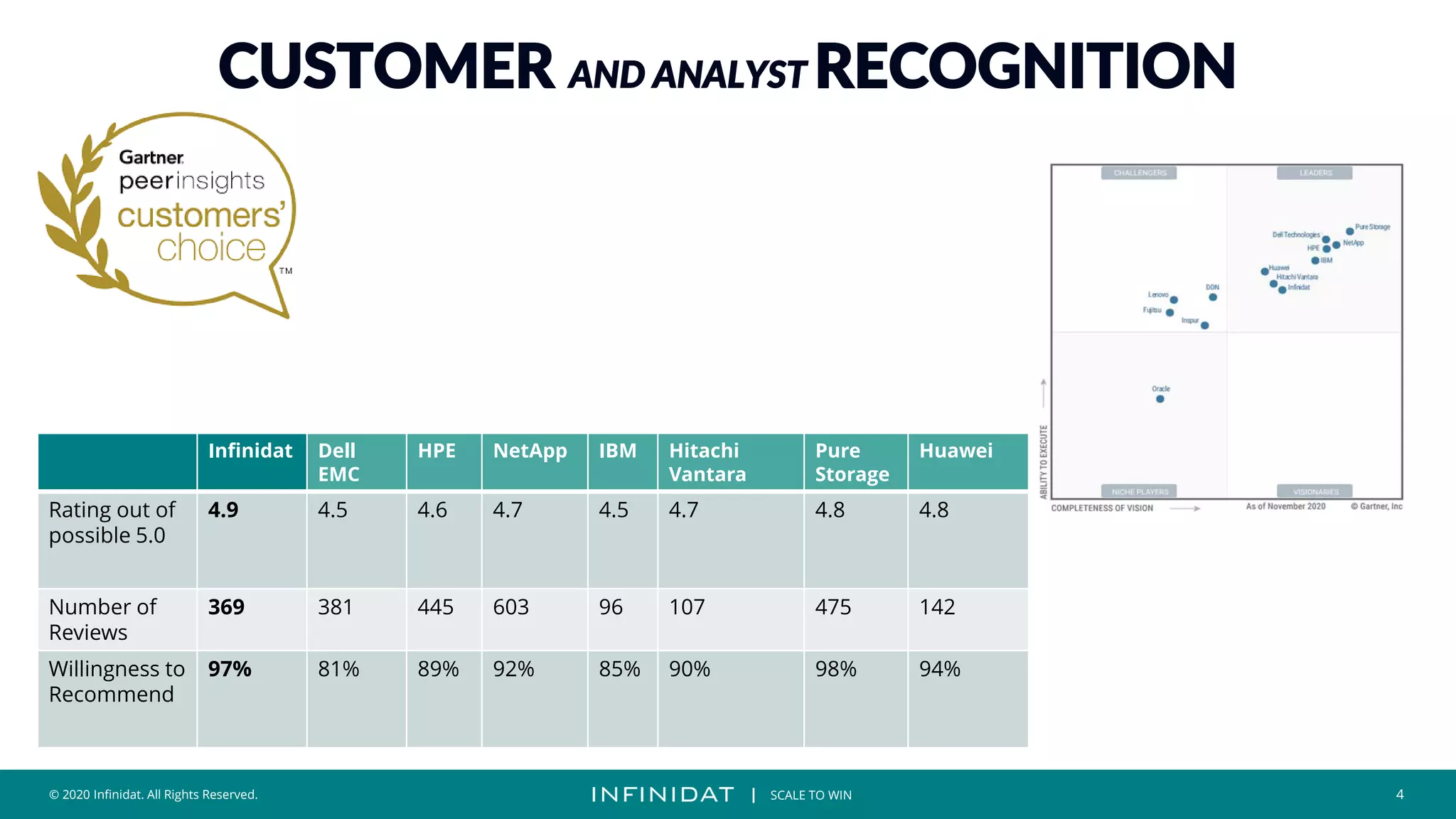

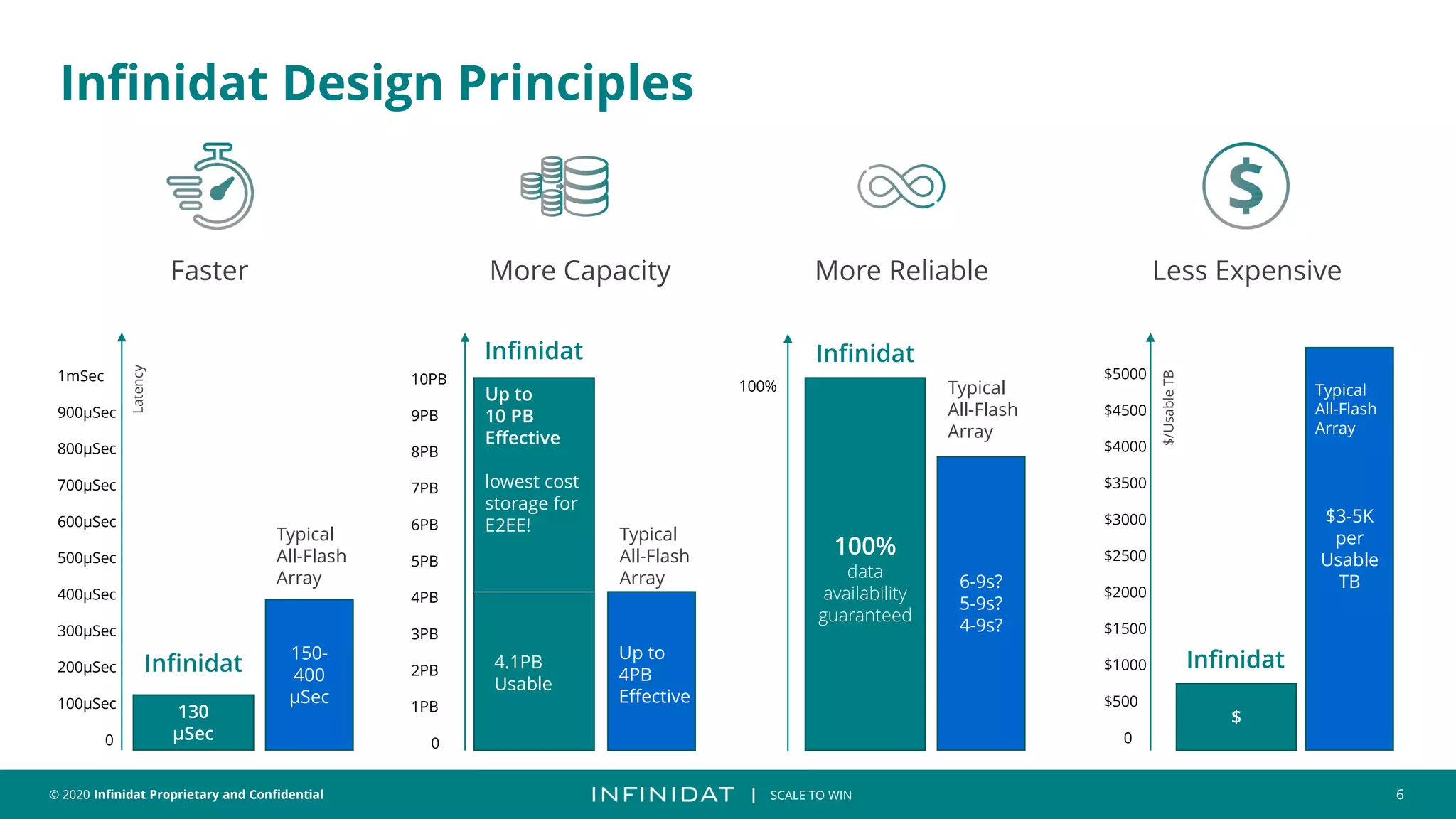


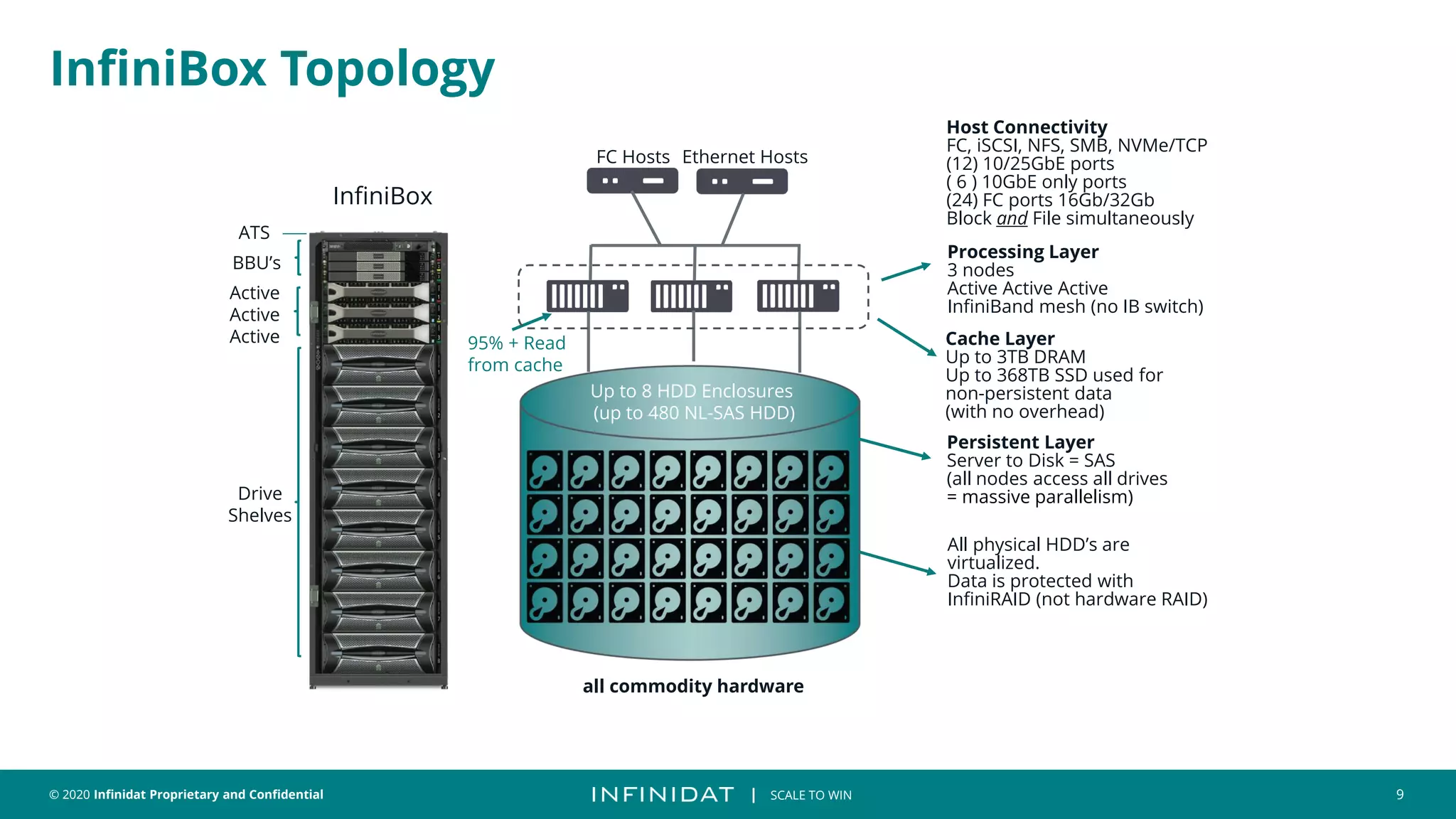
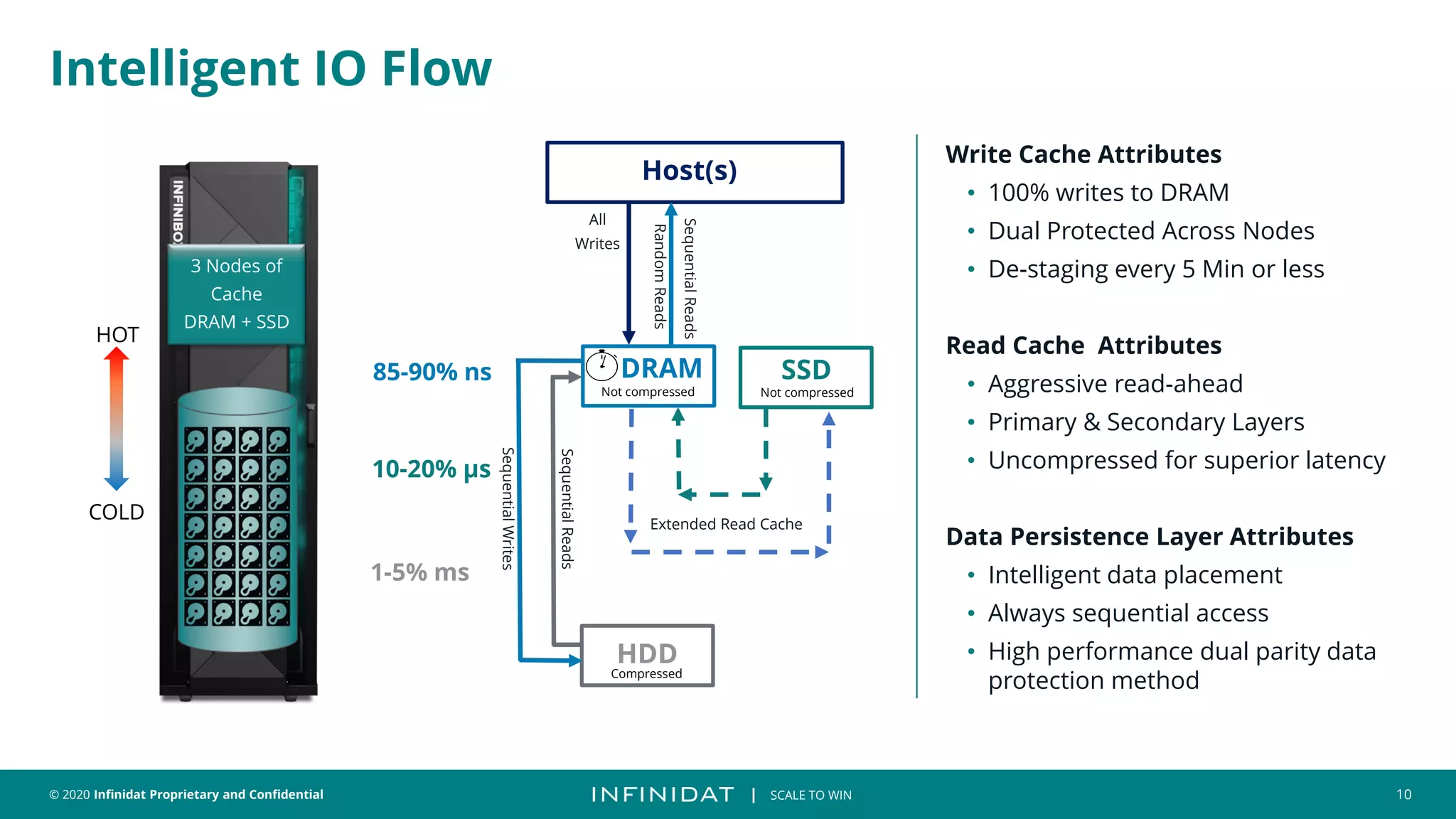
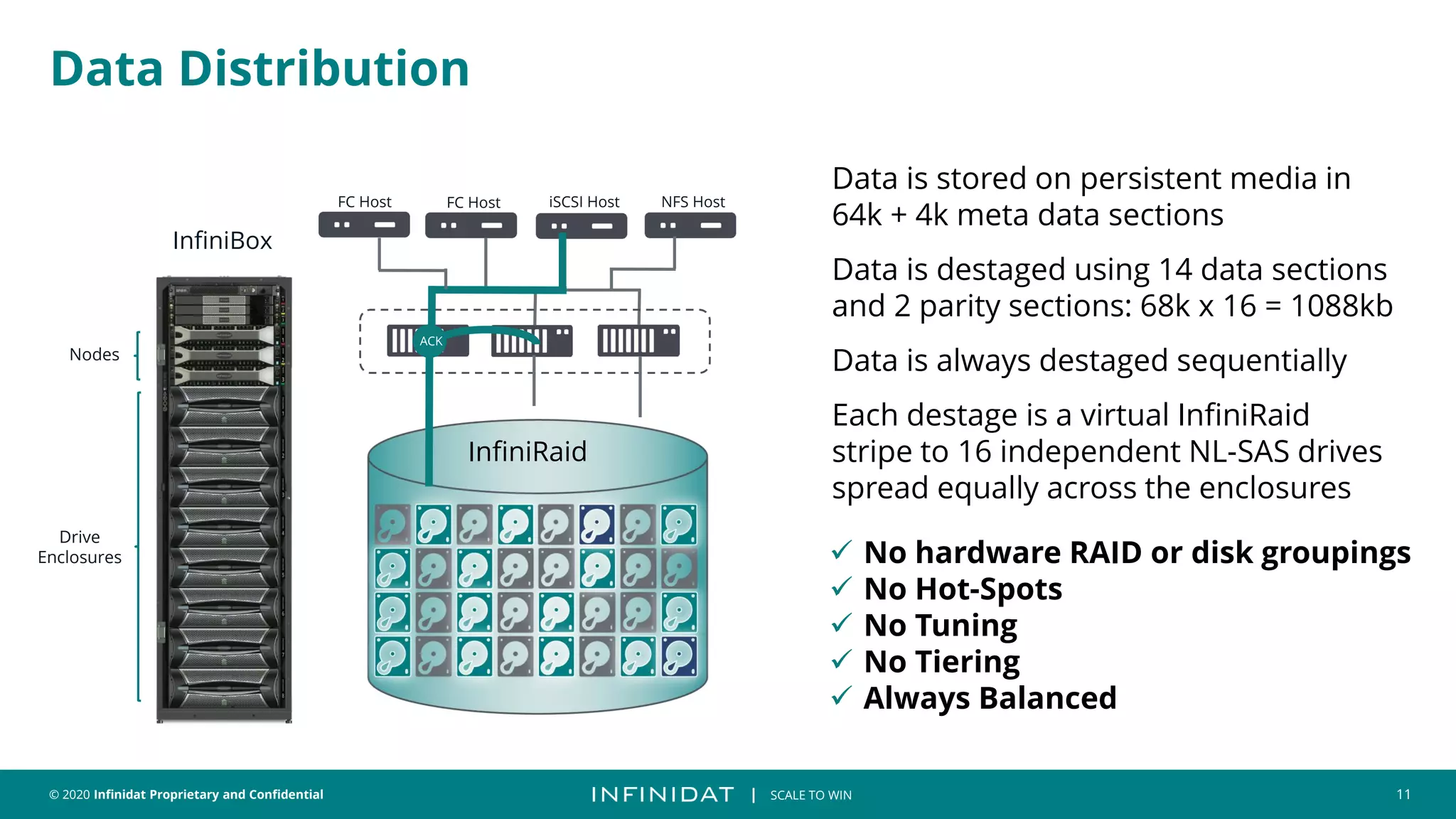
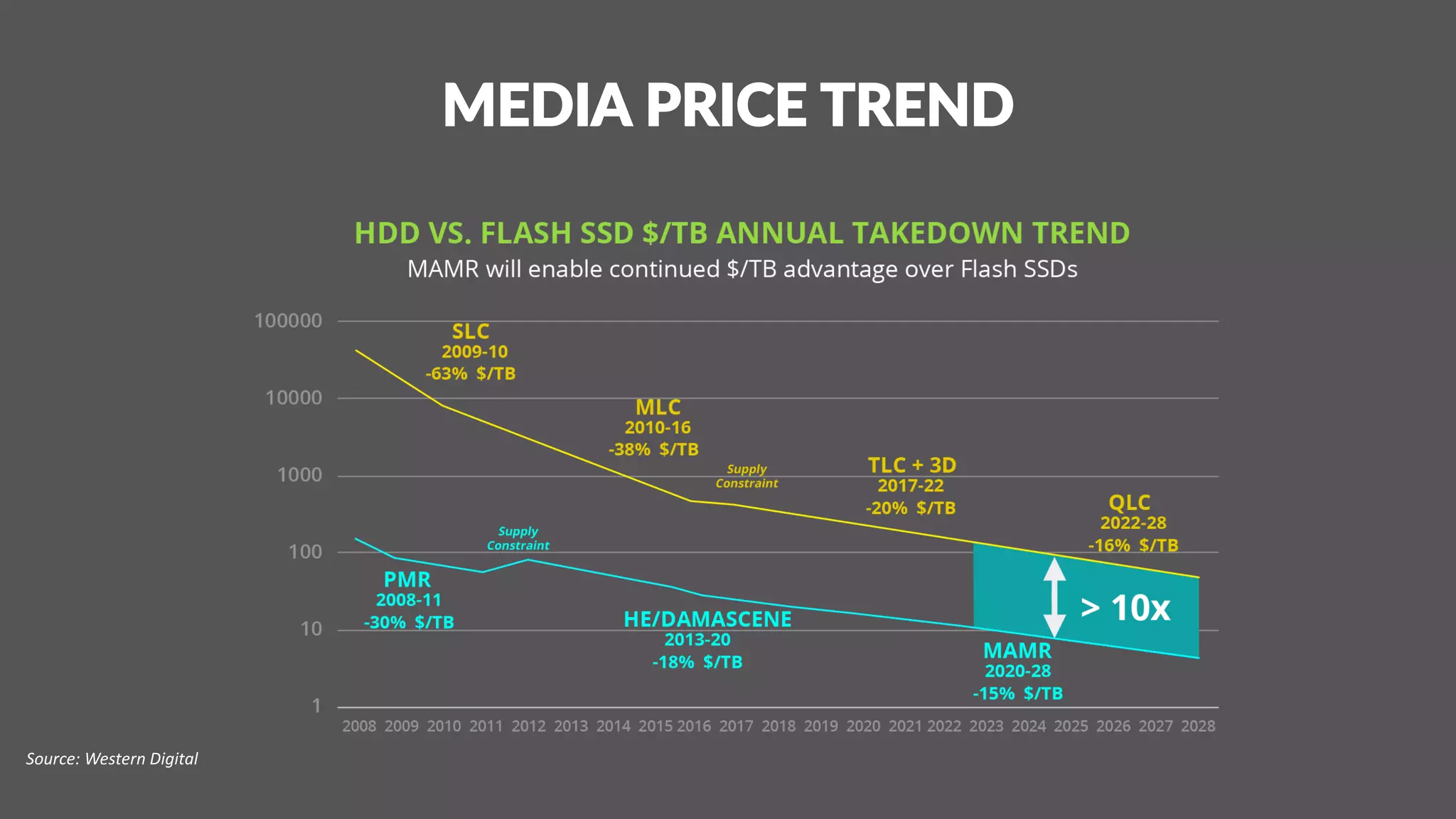
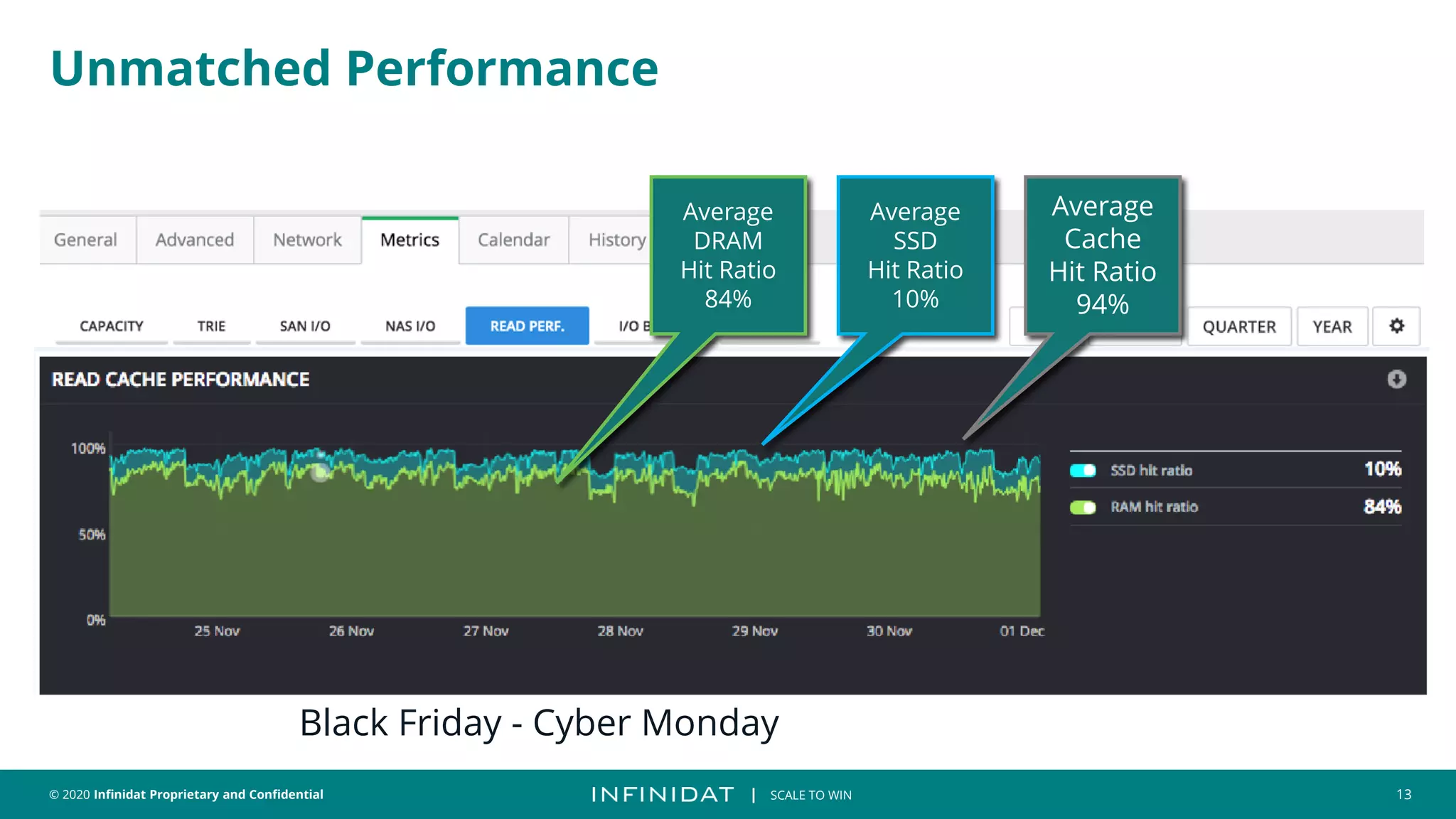


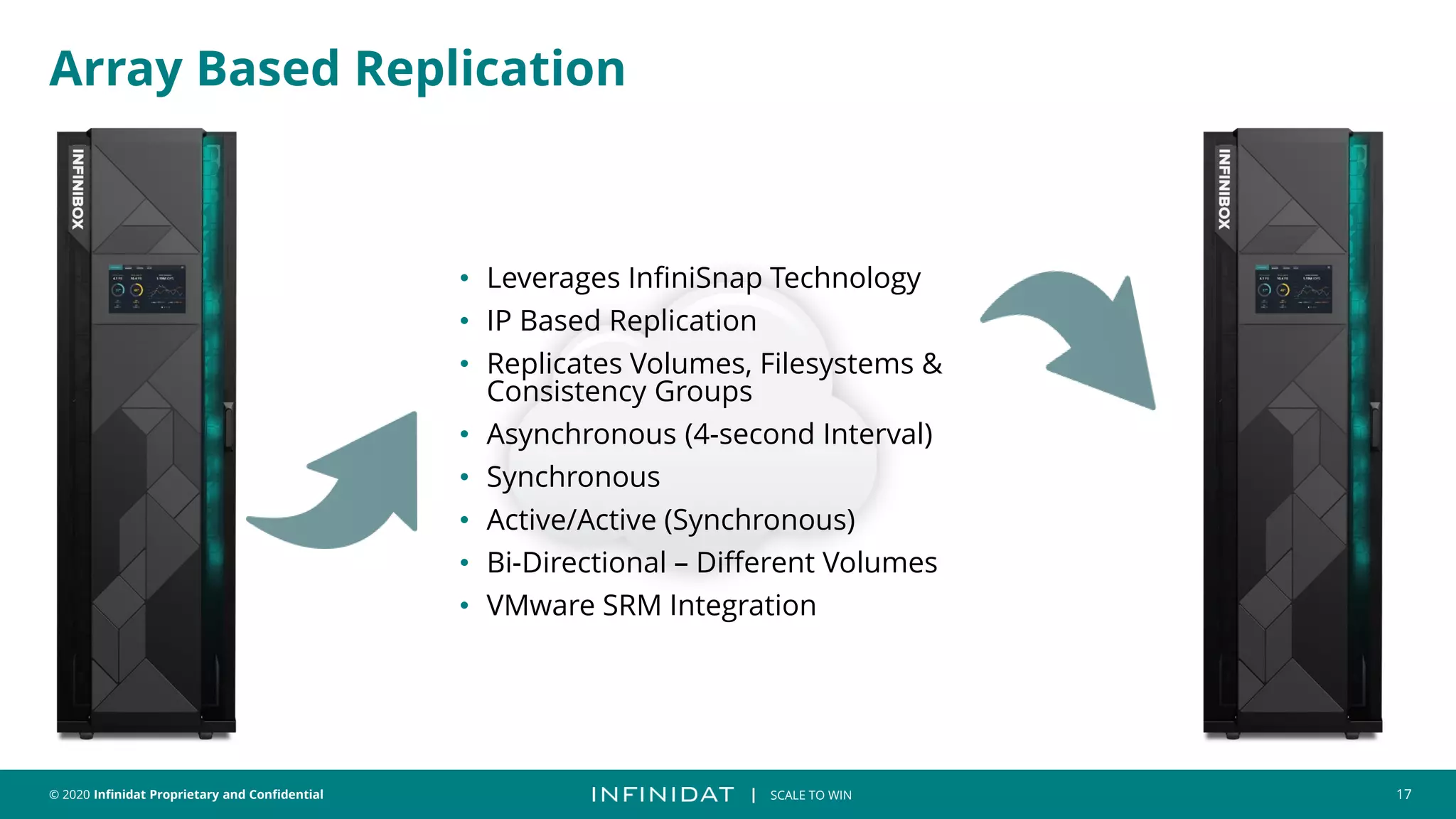

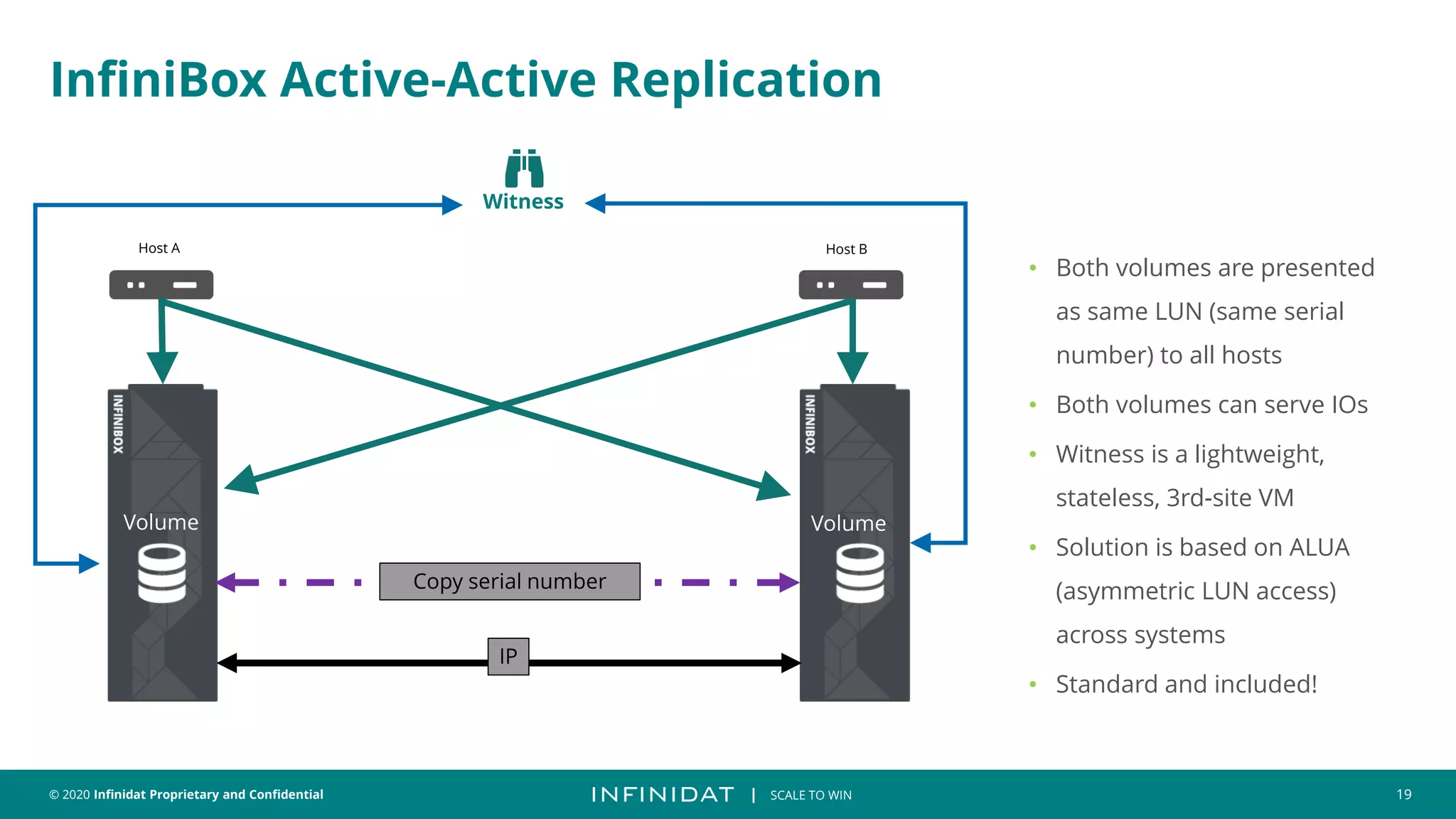
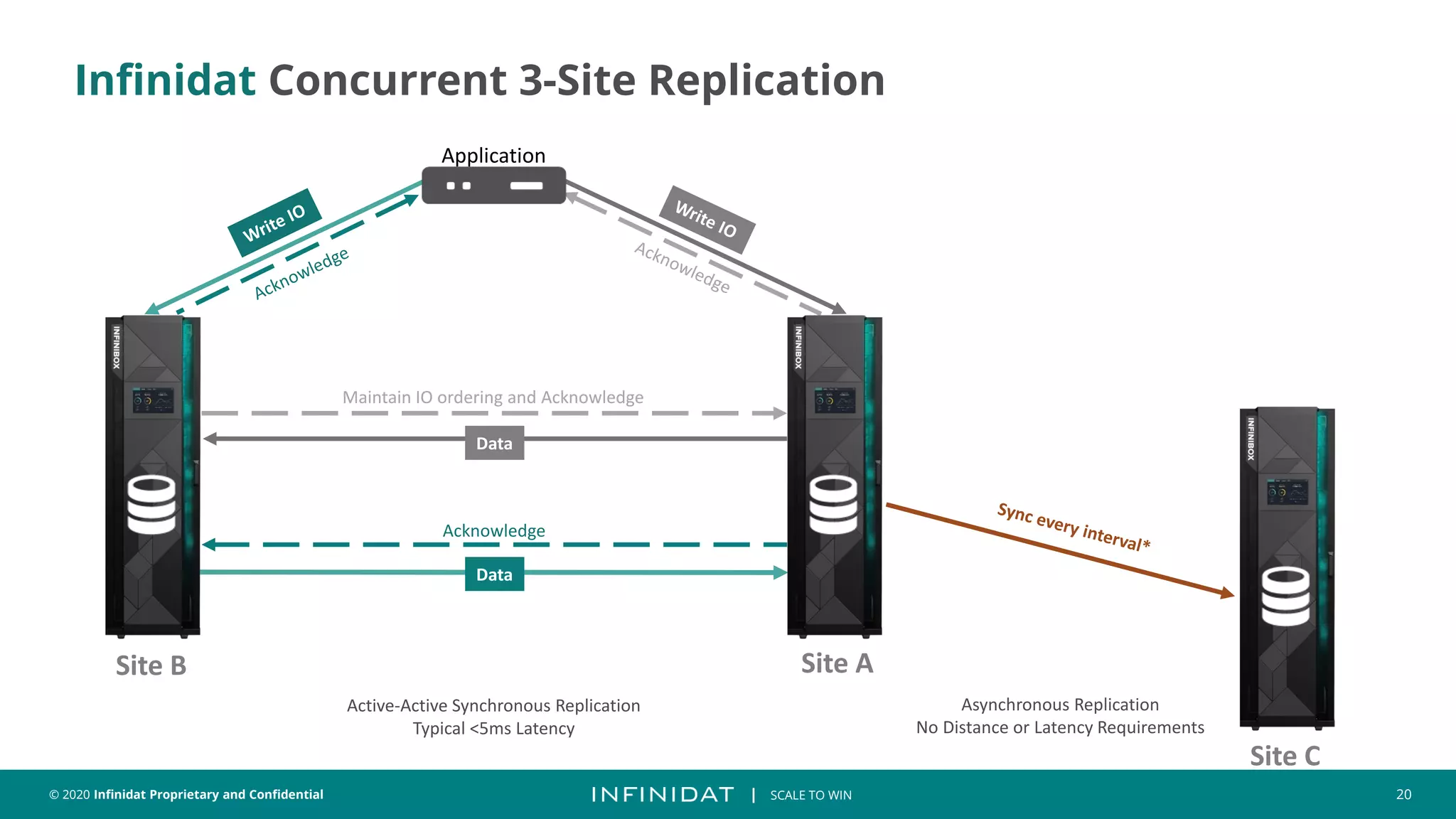
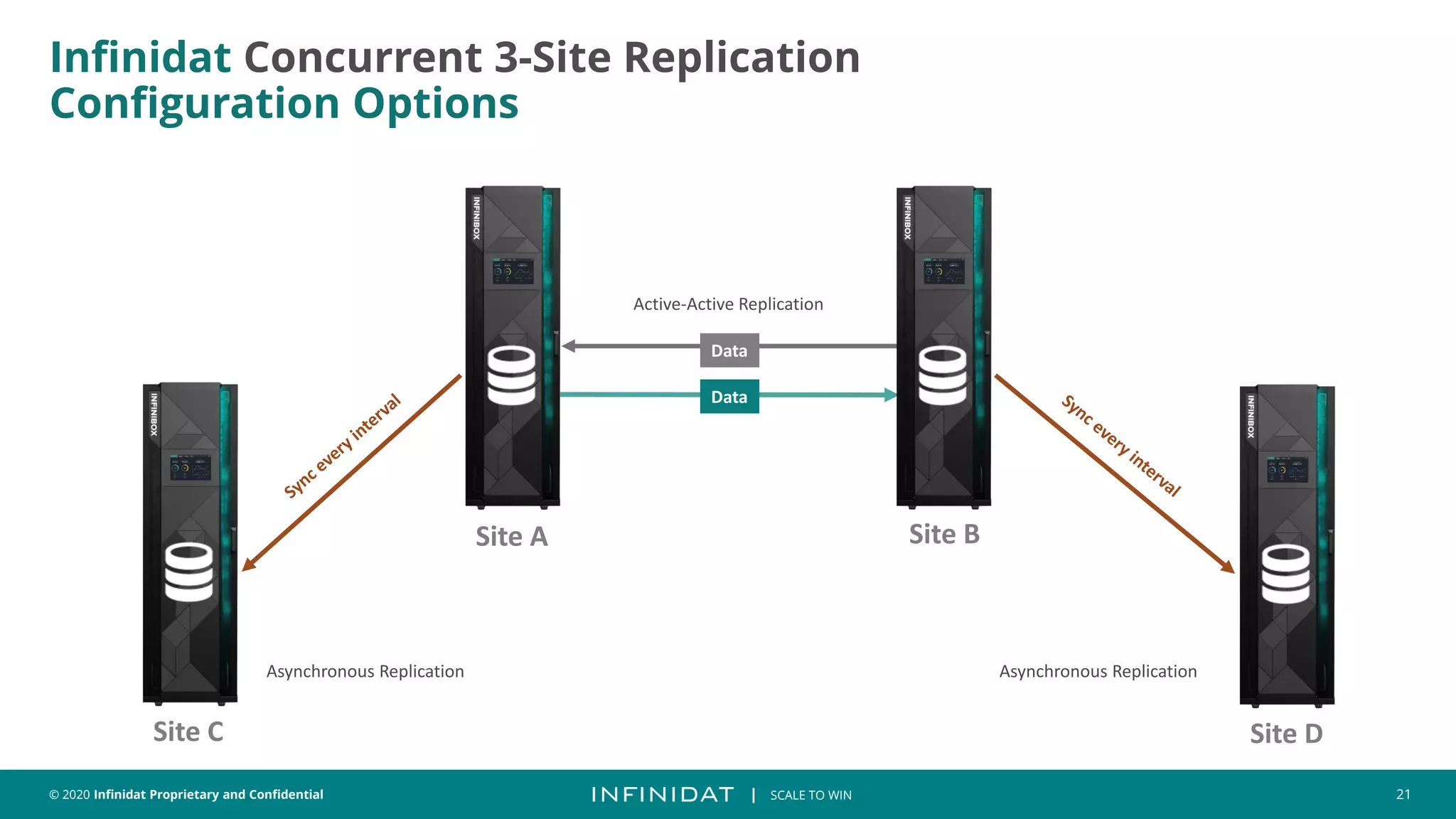

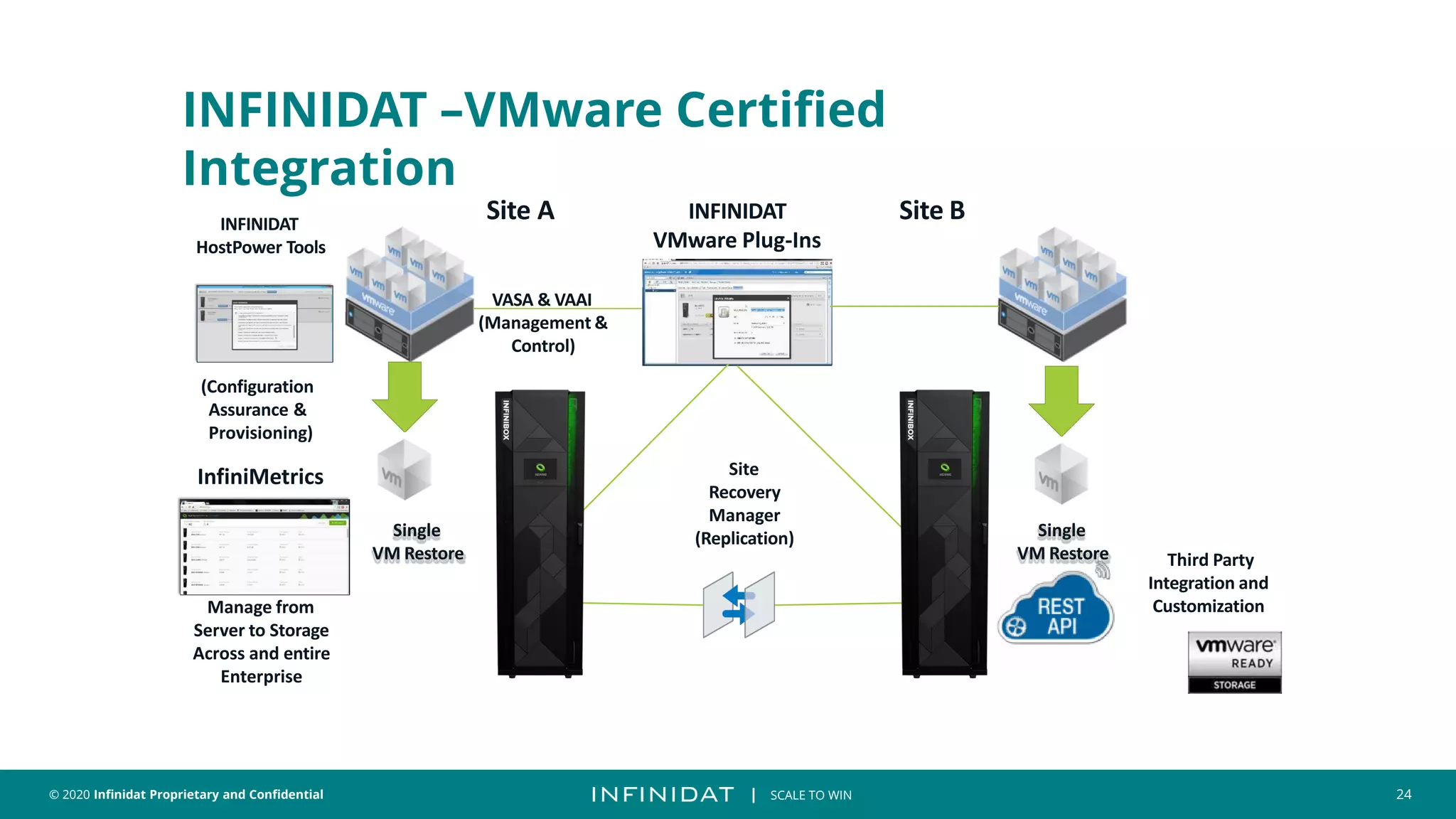
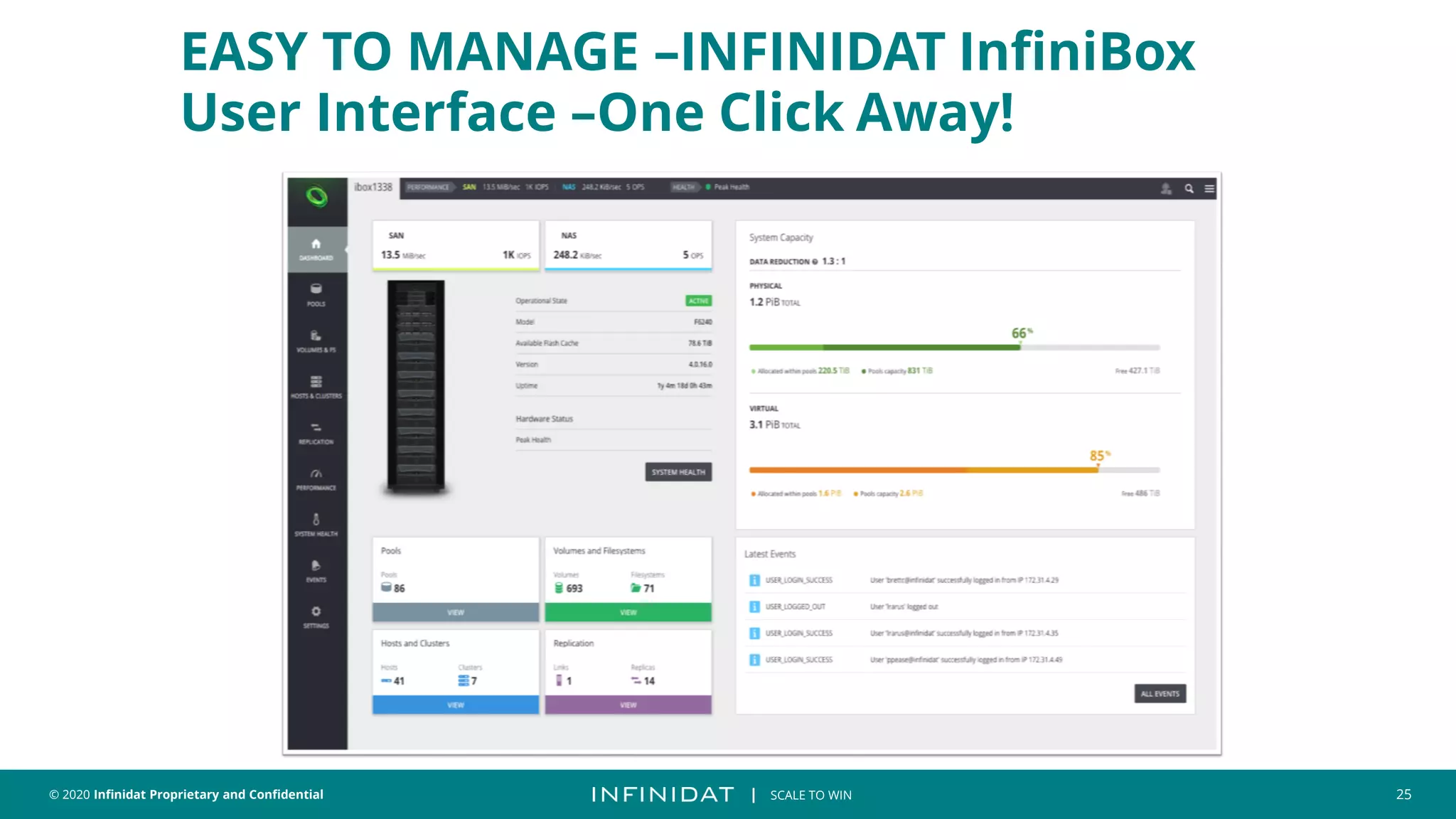


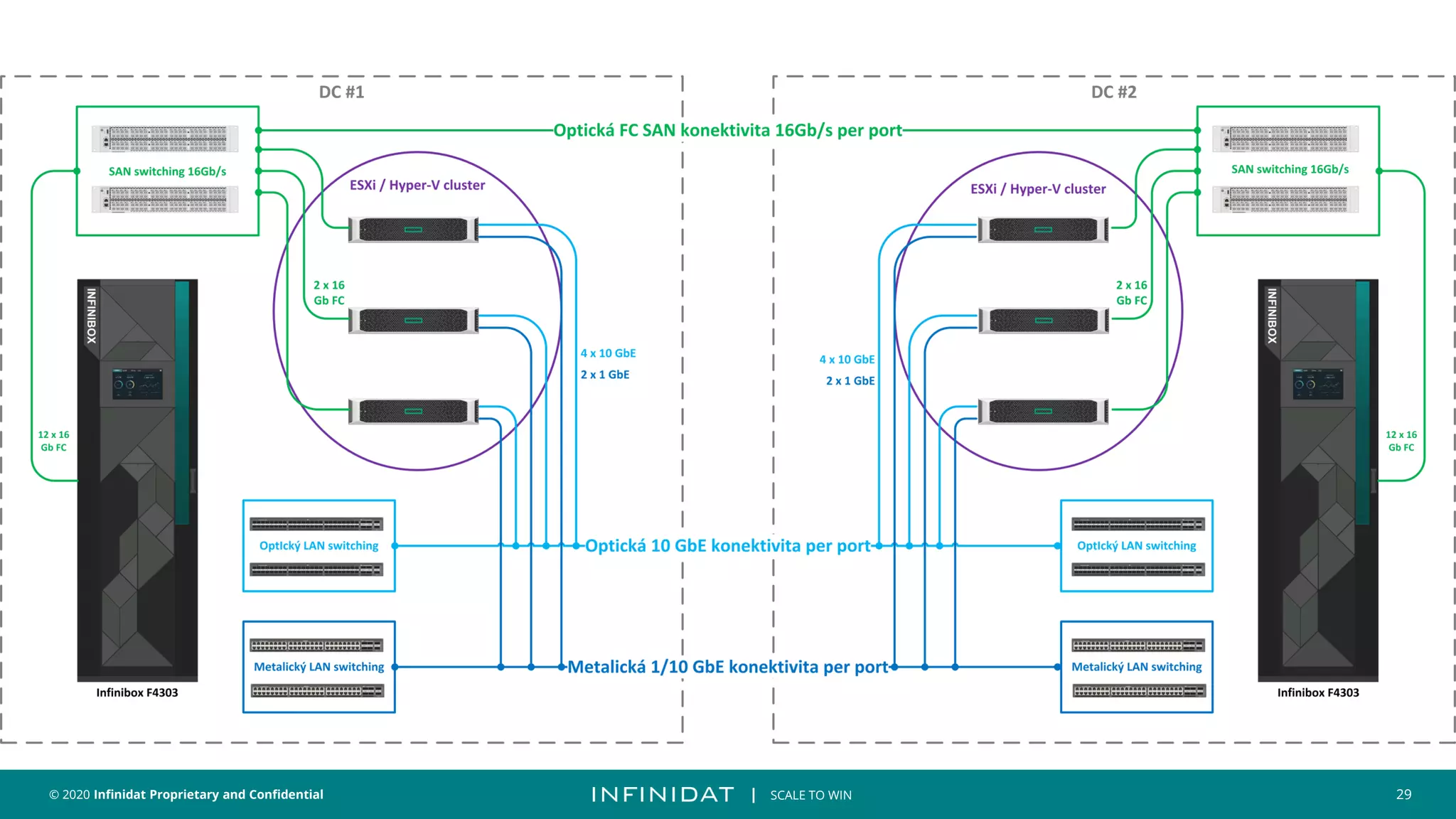
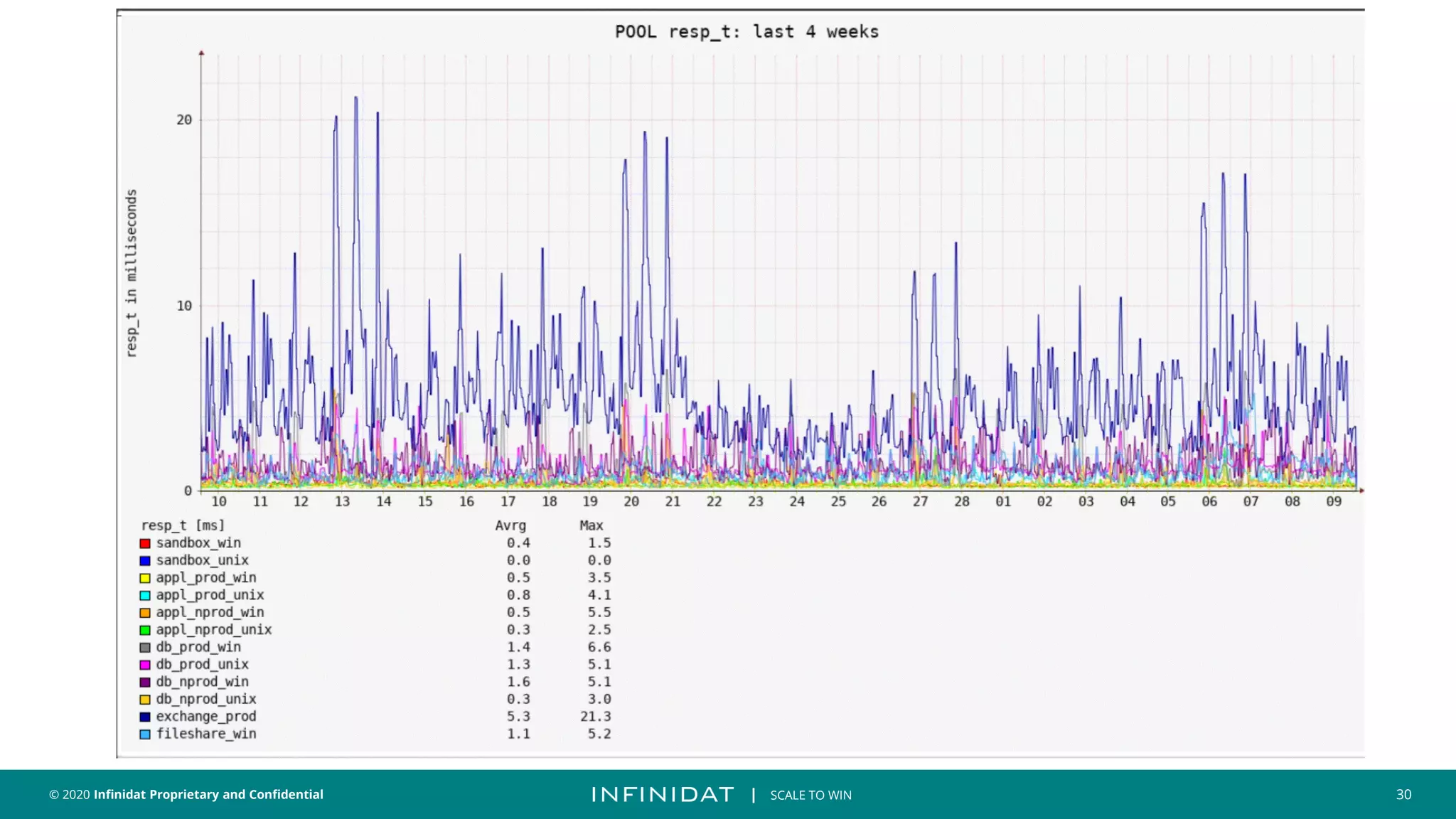



This document discusses Infinidat's scale-out storage solutions. It highlights Infinidat's unique software-driven architecture with over 100 patents. Infinidat systems can scale to over 7 exabytes deployed globally across various industries. Analyst reviews show Infinidat receiving higher ratings than Dell EMC, HPE, NetApp, and others. The InfiniBox systems offer multi-petabyte scale in a single rack with high performance, reliability, and efficiency.







![[234] toast cloud open stack sdn 전략-박성우](https://cdn.slidesharecdn.com/ss_thumbnails/234toastcloud-openstacksdn-161025025504-thumbnail.jpg?width=640&height=640&fit=bounds)



















![[OpenStack Days Korea 2016] Track1 - 카카오는 오픈스택 기반으로 어떻게 5000VM을 운영하고 있을까?](https://cdn.slidesharecdn.com/ss_thumbnails/16kakao-160226171853-thumbnail.jpg?width=640&height=640&fit=bounds)



























































