Download as PDF, PPTX




![Copyright © 2020, Oracle and/or its affiliates. All rights reserved.
7
DATA – The world’s most valuable resource like Water
DATA
Unique
Data cannot be substituted by other
data, because each carries different
information.
[Less Transformation is Better]
Always There
Data can be consumed over and over
again by different parties.
[Easy and Repeatable Access is a Must]
Experience
Data can be accurately evaluated only
after data have been experienced.
[Time to Experience is Important]
THE
OPPORTUNITY
$430B
advantage for
data driven
organizations
- IDC
19X
likely to be
more profitable
- McKinsey
10%
increase in data
accessibility
translates into
$65.7M in net
income
- Baseline](https://image.slidesharecdn.com/dbconsolidationforcustomersjan2022-220123193333/85/Oracle-databaze-Konsolidovana-Data-Management-Platforma-7-320.jpg)



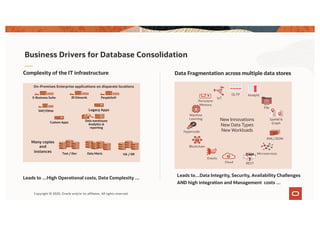



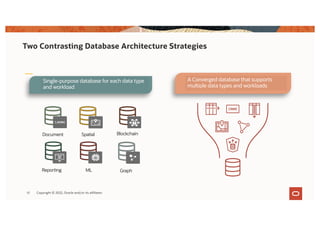

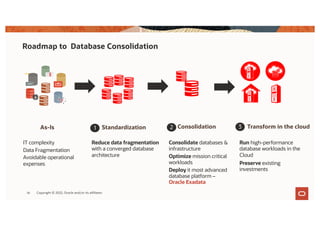





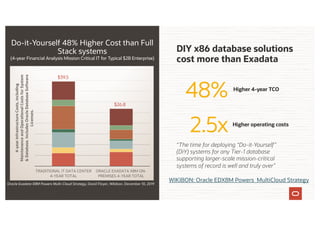
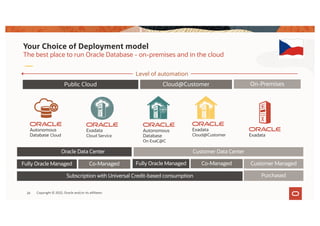


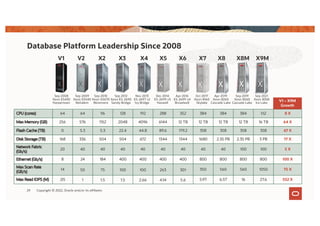
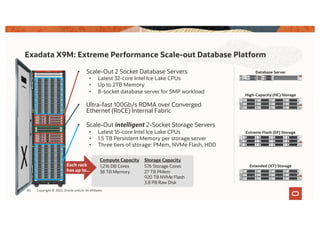
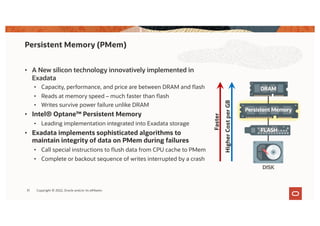
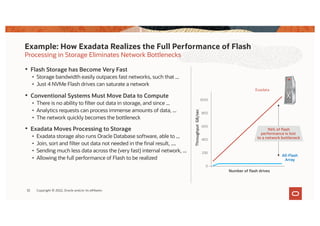

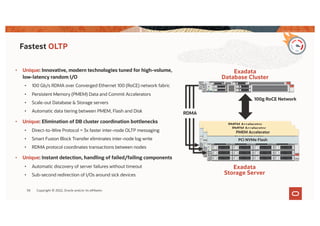
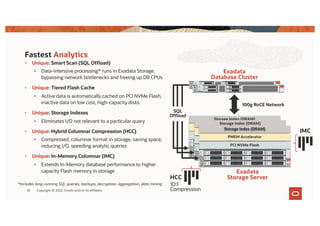












The document discusses the importance of consolidating and modernizing databases, highlighting the complexities and costs associated with using multiple single-purpose databases. It emphasizes the benefits of a converged database architecture, particularly with Oracle's Exadata platform, for improving data management efficiency, performance, and security. The roadmap for database consolidation includes reducing fragmentation, optimizing workloads, and leveraging advanced systems to enhance operational agility and lower overall costs.























































































