Downloaded 22 times











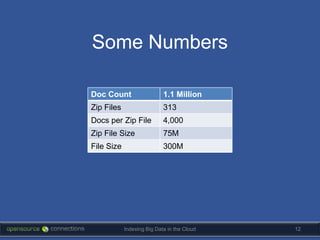

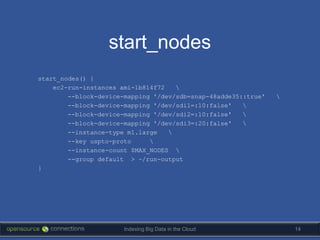






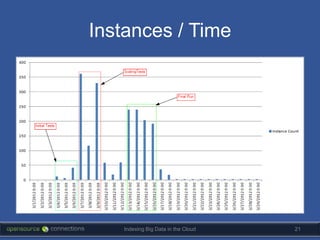


The document discusses strategies for indexing big data in the cloud, highlighting the importance of agility, minimalism, and effective use of tools like Solr. It outlines a real project approach, emphasizing the need for quick prototypes and thorough testing while managing large datasets. Key technical details on server setup and scaling methods are also included, along with the potential alternatives for managing cloud resources.




















































































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)








