Downloaded 156 times
















![Common Issues
• Issue: Users from another domain cannot access data even after plain AD is configured successfully.
• How to debug this issue:
• If data is inaccessible, the first thing you need to check is if the user that is trying to access it has sufficient ACLs. If not, provide
the ACLs and try again. Make sure that users from the other domain are added in the format “DOMAIN_NAMEusername” so
that it is resolved successfully.
• If ACLs are sufficient, and data is still inaccessible, check if the UID and GID for that user is resolvable. Use the following
command to check if the user or group has a UID or GID assigned.
Run the command:
# mmadquery list uids --filter=<username>
UIDS from server 9.122.122.27 (domain NASDOMAIN.COM)
#
• Check that the UID/GID are in the range specified. If not, correct the same in case of RFC2307 or LDAP ID mapping.
• If command throws an error then check for the trust direction between the said Domain and configured domain.
• Conclusion:
• Winbind internally uses the machine account for user or group attribute lookup. If 'machine account' has insufficient privileges to
read these attributes, IBM Spectrum Scale will not be able to read user and group information and hence will be unable to create
the UID and GID that is essential to access the system.
• This will require explicit read permissions for the IBM Spectrum Scale system machine account to read the user attributes.
• How to correct this issue:
• To rectify this issue, you need to 'Delegate Control' for the IBM Spectrum Scale computer account[object type] - to 'Read all user
information‘
• To do this, delegate control for the machine account to read user attributes as follows:
• In the Active Directory console tree, right-click the domain, select Delegate Control, click Next, click Add, and select the object
type Computers. In the object name field, enter the IBM Spectrum Scale system's machine account (the account created with
the netBIOS name under the Computers container). Click Next, and select Delegate the following common tasks. From the
displayed list, select Read all user information. Click Next, and then click Finish. If you have multiple IBM Spectrum Scale™
systems, you can create a group in Active Directory, add each IBM Spectrum Scale system machine account to that group, and
delegate control to that group.
• Best practice that should be followed:
• It is recommended that you check and confirm that the IBM Spectrum Scale computer account can read all user information.
Provide explicit permissions to read the user attributes by delegating control for the IBM Spectrum Scale™ computer account to
read all user information if not already set.
Problem Determination Guide](https://image.slidesharecdn.com/spectrumscaleauthentication-usergroupv2-170519002154/85/IBM-Spectrum-Scale-Authentication-for-Protocols-23-320.jpg)







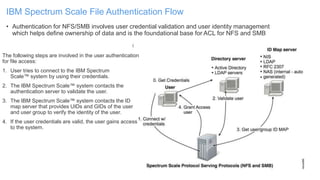
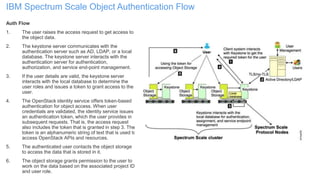
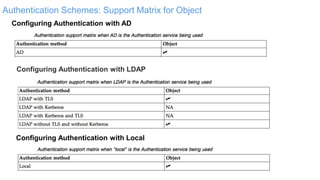
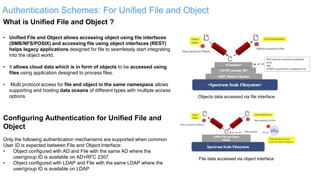
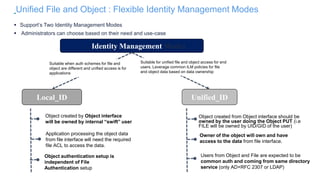
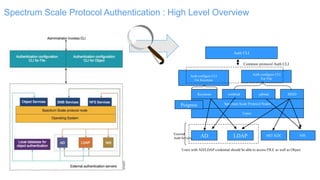
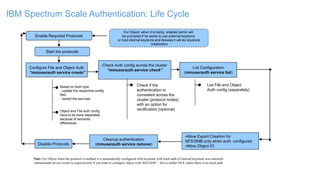
The document discusses IBM Spectrum Scale protocol authentication. It provides an overview of configuring file protocol authentication with Active Directory using RFC2307 ID mapping. It also discusses configuring object protocol authentication with a local user database. The authentication configuration is managed using the mmuserauth service command, which allows creating, listing, checking, and removing authentication configurations for file and object access protocols.

























































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)















