Downloaded 29 times





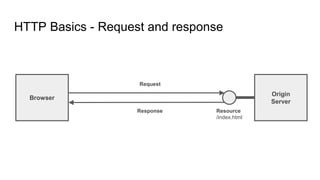
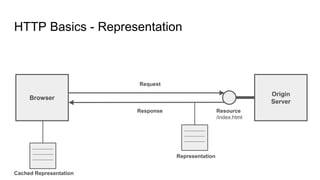
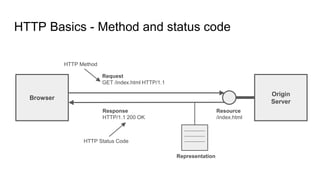
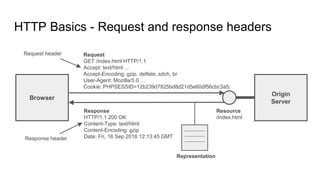
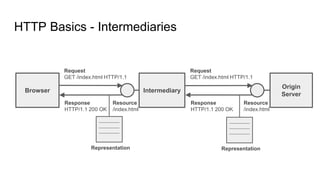

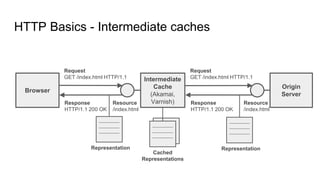



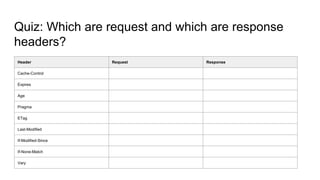


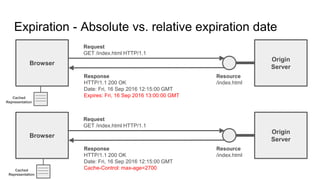

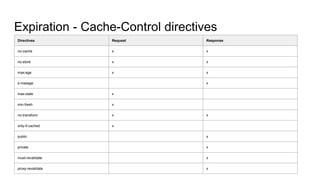
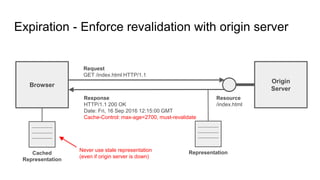
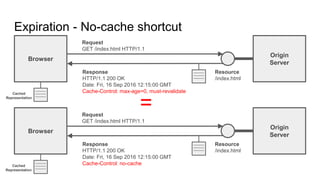
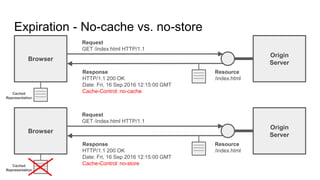
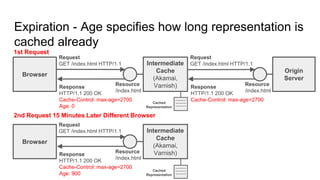

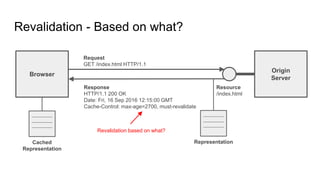
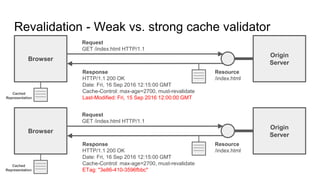
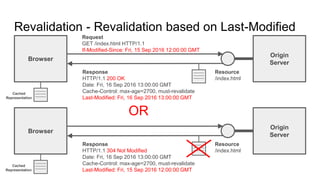
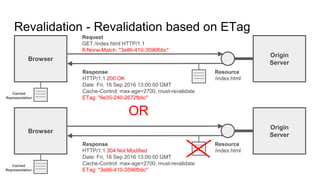

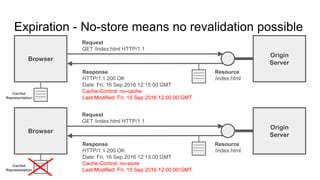

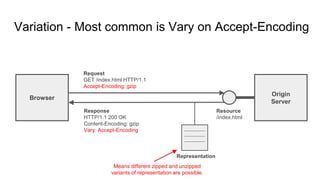
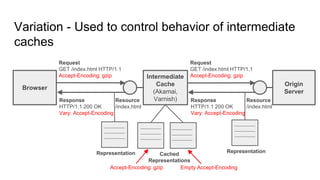
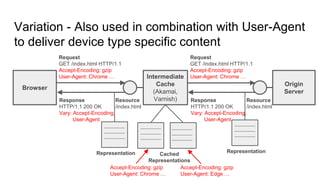

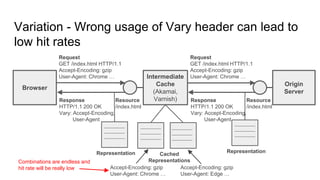
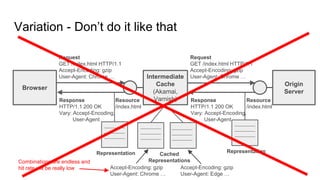
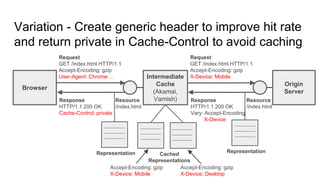




The document provides an overview of HTTP caching fundamentals, detailing how caching works between browsers and origin servers. It covers important HTTP headers related to caching, expiration, revalidation, and the usage of intermediaries, along with various caching directives and best practices. Additionally, it discusses the implications of using the Vary header and how to optimize caching behavior.




















































































