Downloaded 89 times










![ChapterI GettingStarted
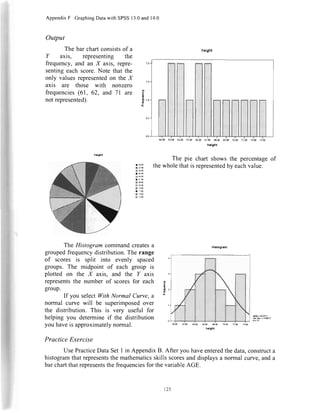
We want to compute the mean for the
variable called GRADE. Thus, we need to select
the variablename in the left window (by clicking
on it). To transferit to the right window, click on
the right arrow between the two windows. The
arrow always points to the window oppositethe
highlighted item and can be used to transfer
l:rt.Ij
in
m ;F* |
-t:g.J
-!tJ
PR:lf- Smdadr{rdvdarvai&
selectedvariablesin either direction.Note that double-clickingon the variablenamewill
also transfer the variable to the opposite window. StandardWindows conventionsof
"Shift" clickingor "Ctrl" clickingto selectmultiplevariablescanbe usedaswell.
When we click on the OK button,the analysiswill be conducted,and we will be
readyto examineour output.
Section1.6 ExaminingandPrintingOutputFiles
After an analysis is performed, the output is
placedin the output window, and the output window
becomesthe active window. If this is the first analysis
you have conductedsince starting SPSS,then a new
output window will be created.If you haverun previous
outputisaddedto theendof yourpreviousoutput.
To switchbackandforthbetweenthedatawindowandtheoutput window,select
thedesiredwindowfromtheWindowmenubar(seearrow,below).
Theoutputwindowis splitintotwo sections.Theleftsectionis anoutlineof the
output(SPSSreferstothisasthe"outlineview").Therightsectionis theoutputitself.
irllliliirrillliirrrI -d
* lnl-Xj
H. Ee lbw A*t lra'dorm
-qg*g!r*!e!|ro_
Craphr,Ufr!3 Uhdo'N Udp
slsl*glelsl*letssJsl#_#rl+l*l +l-l&hjl :lqlel,
* Descrlptlves
f]aiagarll l: lrrs datcra&ple.lav
o
lle*crhlurr Sl.*liilca
N Mlnlmum Hadmum Xsrn Std.Dwiation
ufinuc
valldN(|lstrylsa)
I
2
83.00 85.00 81,0000 1.41421
ffiffi?iffi rr---*.* r*4
The sectionon the left of the output window providesan outline of the entireout-
put window. All of the analysesarelistedin theorderin which they wereconducted.Note
that this outline can be usedto quickly locatea sectionof the output.Simply click on the
sectionyou would like to see,andtheright window will jump to the appropriateplace.
analysesandsavedthem,your
ornt
El Pccc**tvs*
r'fi Trb
6r**
lS Adi€D*ard
ffi Dcscrtfhcsdkdics](https://image.slidesharecdn.com/howtousespss-140707154912-phpapp02/85/How-to-use-spss-12-320.jpg)



![Chapter2
EnteringandModifying Data
In Chapter 1, we learnedhow to createa simpledatafile, saveit, perform a basic
analysis,and examinethe output.In this section,we will go into more detail aboutvari-
ablesanddata.
Section2.1 VariablesandDataRepresentation
In SPSS,variablesarerepresentedascolumnsin the datafile. Participantsarerep-
resentedasrows.Thus,if we collect4 piecesof informationfrom 100participants,we will
havea datafile with 4 columnsand 100rows.
Measurement Scales
Therearefour typesof measurementscales:nominal, ordinal, interval, andratio.
While themeasurementscalewill determinewhich statisticaltechniqueis appropriatefor a
given set of data,SPSSgenerallydoesnot discriminate.Thus, we startthis sectionwith
this warning: If you ask it to, SPSSmay conductan analysisthat is not appropriatefor
your data.For a morecompletedescriptionof thesefour measurementscales,consultyour
statisticstext or the glossaryin AppendixC.
Newer versionsof SPSSallow you to indicatewhich types of
data you have when you define your variable.You do this using the
Measurecolumn.You can indicateNominal,Ordinal,or Scale(SPSS
doesnot distinguishbetweeninterval andratio scales).
Look at the sampledatafile we createdin Chapterl. We calcu-
lateda mean for the variableGRADE. GRADE wasmeasuredon a ra-
tio scale,andthemeanis anacceptablesummarystatistic(assumingthatthedistribution
isnormal).
We could havehad SPSScalculatea mean for the variableTIME insteadof
GRADE.If wedid,wewouldgettheoutputpresentedhere.
TheoutputindicatesthattheaverageTIME was 1.25.RememberthatTIME was
coded as an ordinal variable (I =
morningclass,2-afternoon
class).Thus, the mean is not an
appropriatestatisticfor an ordinal
scale,but SPSScalculatedit any-
way. The importanceof consider-
ing the type of data cannot be
overemphasized. Just because
SPSSwill compute a statistic for
you doesnot meanthatyou should
Measure
@Nv
f $cale
.sriltr
r Nominal
ll
*lq]eH"N-ql*l trlllql eilr $l-g
:* Sl astts
.l.:D
gtb
:$sh
.6M6.ffi
$arlrba"t S#(|
ht6x0tMn a
LS 2.qg Lt@](https://image.slidesharecdn.com/howtousespss-140707154912-phpapp02/85/How-to-use-spss-16-320.jpg)
![ql total
2.00 2.Bn 4.00
3.00 1.00 4.00
4.00 3.00 7.00
2.00
1.00 2.UB 3.00
Chapter2 EnteringandModifying Data
useit. Later in the text,when specificstatisticalproceduresarediscussed,the conditions
underwhich they areappropriatewill be addressed.
Missing Data
Often,participantsdo not providecompletedata.For somestudents,you may have
a pretestscorebut not a posttestscore.Perhapsone studentleft one questionblank on a
survey,or perhapsshedid not stateher age.Missing datacanweakenany analysis.Often,
a singlemissingquestioncaneliminatea sub-
ject from all analyses.
If you havemissingdatain your data
set, leave that cell blank. In the exampleto
the left, the fourth subjectdid not complete
Question2. Note thatthetotal score(which is
calculatedfrom both questions)is alsoblank
becauseof the missing data for Question2.
SPSSrepresentsmissing data in the data
window with a period(althoughyou should
not entera period-just leaveit blank).
Section2.2 TransformationandSelectionof Data
Weoftenhavemoredatain a datafile thanwewantto includein a specificanaly-
sis.For example,our sampledatafile containsdatafrom four participants,two of whom
receivedspecialtrainingandtwo of whomdid not.If we wantedto conductananalysis
usingonlythetwo participantswhodidnotreceivethetraining,we wouldneedto specify
theappropriatesubset.
Selectinga Subset
F|! Ed vl6{ , O*. lr{lrfum An*/& e+hr (
We canusethe SelectCasescommandto specify
a subset of our data. The Select Cases command is
located under the Data menu. When you select this
command,the dialog box below will appear.
t'llitl&JE
il :id
O*fFV{ldrr PrS!tU6.,.
CoptO.tafropc,tir3,..
l,j.l,/r,:irrlrr! lif l ll:L*s,,.
Hh.o*rr,.,
Dsfti fi*blc Rc*pon$5ct5,,,
ConyD*S
sd.rt Csat
You can specify which cases(partici-
pants)you want to selectby using the selec-
tion criteria,which appearon the right sideof
theSelectCasesdialogbox.
q*d-:-"-- "-"""-*--*--**-""*-^*l
6 Alce
a llgdinlctidod
,rl
r irCmu*dcaa ]
i*np* | i{^ lccdotincoarrpr
:
;.,* |
-:--J
c llaffrvci*lc
l0&t
C6ttSldrDonoan!.ffi
foKl aar I c-"rl x* |
t2](https://image.slidesharecdn.com/howtousespss-140707154912-phpapp02/85/How-to-use-spss-17-320.jpg)
![Chapter2 EnteringandModifying Data
By default,All caseswill be selected.The most commonway to selecta subsetis
to click If condition is satisfied,thenclick on the button labeledfi This will bring up a
newdialogbox thatallowsyou to indicatewhichcasesyou would like to use.
You can enter the logic
used to select the subsetin the
upper section. If the logical
statement is true for a given
case, then that case will be
selected.If the logical statement
is false. that case will not be
selected.For example, you can
selectall casesthat were coded
as Mon/Wed/Fri by enteringthe
formula DAY = I in the upper-
?Ais"I c'-t I Ht I
rightpartof thewindow.If DAY is l, thenthestatementwill betrue,andSPSSwill select
the case.If DAY is anythingotherthan l, the statementwill be false,andthe casewill not
be selected.Once you have enteredthe logical statement,click Continueto return to the
SelectCasesdialogbox. Then,click OK to returnto thedata window.
After you haveselectedthecases,thedata window will changeslightly.
The casesthat werenot selectedwill be markedwith a diagonalline throughthe
casenumber.For example,for our sampledata,the first and third casesarenot
selected.only the secondandfourthcasesareselectedfor this subset.
U;J;J:.1-glL1 E{''di',*tI
, 'J-e.l-,'JlJ.!J-El[aasi"-Eo,t----i
ilqex4q lffiIl,?,l*;*"'=
,Jl _!JlJ 0 U IAFTAN(r"nasl
sl"J=tx-s*t"lBi!?Blt1trb:r
1
I
,
I
I
l
i{
1
,1
'l
1
I
1
:
t
'l
1
'l
EffEN'EEEgl''EEE'o ,.,:r. rt lnl vl
!k_l**
-#gdd.i.&lFlib'-
ID TIME MORNING ERADE WORK TRAINING
/,-< 4533.m Tueffhui affsrnoon No ffi.m Na Yes NotSelected
2 1901.m-
6h4lto*-
ieifrfft
MpnMed/i mornino. -..- ^,-.-.*.*..,-- J.- . - .-..,..".*-....- ':
Yss 83,U1Fad-Jime Yes Splacled
-'4
TuElThu. morning No m.m No No NotSelected
4 MonA/Ved/1morning Yes ru.mPart-Time No
s
!LJii. vbryJv,itayss7 I . *-J *]fsPssProcaesaFrcady I i ,1,
An additionalvariablewill also be createdin your data file. The new variableis
calledFILTER_$ andindicateswhethera casewasselectedor not.
If we calculatea mean
GRADE using the subsetwe
just selected,we will receive
the output at right. Notice that
we now havea mean of 78.00
with a samplesize(M) of 2 in-
steadof 4.
DescripthreStailstics
N Minimum Maximum Mean
std.
Deviation
UKAUE
ValidN
IliclwisP'l
2
2
73.00 83.00 78.0000 7.0711
l3](https://image.slidesharecdn.com/howtousespss-140707154912-phpapp02/85/How-to-use-spss-18-320.jpg)







![Chapter3 DescriptiveStatistics
percentagesand other information to be generatedfor
eachcombinationof values.Click Cells,andyou will get
thebox at right.
For the example presentedhere, check Row,
Column, and Total percentages.Then click Continue.
This will return you to the Crosstabsdialog box. Click
OK to run theanalvsis.
TRAINING'WURKCross|nl)tilntlo|l
WORK
TolalNO Parl-Time
TRAINING Yes Count
%withinTRAININO
%withinwoRK
%ofTolal
I
50.0%
50.0%
25.0%
1
50.0%
50.0%
25.0%
100.0%
50.0%
50.0%
No Count
%withinTRAINING
%withinWORK
%ofTolal
1
50.0%
50.0%
25.0%
1
50.0%
50.0%
25.0%
?
1000%
50.0%
50.0%
Total Count
%withinTRA|NtNo
%wilhinWORK
%ofTolal
50.0%
100.0%
50.0%
a
500%
100.0%
50.0%
4
r00.0%
100.0%
100.0%
Interpreting Crosstabs Output
The output consistsof a
contingencytable.Each level of
WORK is given a column.Each
level of TRAINING is given a
row. In addition, a row is added
for total, and a column is added
for total.
The Cells button allows you to specify W:
t C",ti* |
t*"1
,"1
Eachcell containsthe numberof participants(e.g.,one participantreceivedno
traininganddoesnot work; two participantsreceivedno training,regardlessof employ-
mentstatus).
Thepercentagesfor eachcell arealsoshown.Row percentagesaddup to 100%
horizontally.Columnpercentagesaddupto 100%vertically.Forexample,of all theindi-
vidualswhohadno training, 50ohdid notworkand50o%workedpart-time(usingthe"o/o
withinTRAINING" row).Of theindividualswhodid notwork,50o/ohadno trainingand
50%hadtraining(usingthe"o/owithinwork"row).
Practice Exercise
UsingPracticeDataSet I in AppendixB, createa contingencytableusingthe
Crosstabscommand.Determinethe numberof participantsin eachcombinationof the
variablesSEXandMARITAL. Whatpercentageof participantsis married?Whatpercent-
ageof participantsis maleandmarried?
Section3.3 Measuresof Central Tendencyand Measuresof Dispersion
for a SingleGroup
Description
Measuresof centraltendencyarevaluesthat representa typicalmemberof the
sampleor population.Thethreeprimarytypesarethemean,median,andmode.Measures
of dispersiontell you thevariabilityof yourscores.Theprimarytypesaretherangeand
thestandarddeviation.Together,a measureof centraltendencyanda measureof disper-
sionprovideagreatdealof informationabouttheentiredataset.
''Pd€rl.!p. - r-Bait*"
;F Bu : ,l- U]dadr&ad
F corm if- sragatrd
"1'"1--_rry-ys___ .
2l](https://image.slidesharecdn.com/howtousespss-140707154912-phpapp02/85/How-to-use-spss-26-320.jpg)
![Chapter,l DescriptiveStatistics
We will discussthesemeasuresof central
tendencyandmeasuresof dispersionin the con-
text of the Descriplives command. Note that
many of thesestatisticscan also be calculated
with several other commands (e.g., the
Frequenciesor CompareMeans commandsare
requiredto computethe mode or median-the
Statisticsoption for theFrequenciescommandis
shownhere).
iffi{ltl*::l'.,xl
Fac*Vd*c-----:":'-'-"-" "-
|7 Arruer
|* O*pai*furjF tqLteiotpr
F rac$*['*
r.-I 16-k'I
':'I I+l
lcer**r**nc*r1 !*{* |
f- rlm Cr* |
, f u"g.t -:.-i
i0hx*ioo*".'*-'
lf Sld.dr',iitbnl* lli*nn
]fV"iro
f.H**ntrn
lfnxrgo f.5.t.ncr
: T Modt
:-^t5m
l- Vdsm$apn&bcirr
oidrlatin-- --
r5tcffi:
; f Kutu{b
i
Assumptions
Eachmeasureof centraltendencyandmeasureof dispersionhasdifferent assump-
tionsassociatedwith it. The mean is the mostpowerfulmeasureof centraltendency,andit
hasthe mostassumptions.For example,to calculatea mean,the datamustbe measuredon
an interval or ratio scale.In addition,thedistributionshouldbe normally distributedor, at
least,not highly skewed.The median requiresat leastordinal data.Becausethe median
indicatesonly the middle score(when scoresarearrangedin order),thereareno assump-
tions aboutthe shapeof the distribution.The mode is the weakestmeasureof centralten-
dency.Thereareno assumptionsfor the mode.
The standard deviation is themostpowerful measureof dispersion,but it, too, has
severalrequirements.It is a mathematicaltransformationof the variance (the standard
deviationis the squareroot of thevariance).Thus,if oneis appropriate,theotheris also.
The standard deviation requiresdatameasuredon an interval or ratio scale.In addition,
the distributionshouldbe normal.The range is the weakestmeasureof dispersion.To cal-
culatea range, the variablemustbe at leastordinal. For nominal scaledata,the entire
frequencydistributionshouldbe presentedasa measureof dispersion.
Drawing Conclusions
A measureof centraltendencyshouldbe accompaniedby a measureof dispersion,
Thus, when reporting a mean, you shouldalso report a standard deviation. When pre-
sentinga median, you shouldalsostatetherange or interquartilerange.
.SPSSData Format
Only onevariableis required.
22](https://image.slidesharecdn.com/howtousespss-140707154912-phpapp02/85/How-to-use-spss-27-320.jpg)















![Chapter4 GraphingData
Section4.6 EditingSPSSGraphs
Whatever command you
use to createyour graph,you will
probably want to do some editing
to make it appearexactly as you
want it to look. In SPSS,you do
this in much the sameway thatyou
edit graphs in other software
programs(e.g.,Excel).After your
graph is made, in the output
window, select your graph (this
will createhandlesaroundthe out-
sideof the entireobject)and right-
click. Then. click SPSS Chart
Object, and click Open. Alter-
natively,you can double-clickon
the graphto openit for editing.
Whenyou openthe graph,theChartEditor window andthe correspondingProper-
lies window will appear.
qb li. lin.tlla. *rll..!!lflE.!l
,, ;l 61f L:lr!.H;gb.tct-]pu1 ri
IE :,- r--."1
Ittttr
tlttIr
tllrwel
w&&$!{!rJ
JJJJ-JJ
JJJJJJ
.nlqrlcnl,f,,!sl
r 9-,I rt
fil mlryl
OnceChart Editor is open,you caneasilyedit eachelementof the graph.To select
an element,just click on the relevantspoton the graph.For example,if you haveaddeda
title to your graph("Histogram" in the examplethat follows), you may selectthe element
representingthetitle of the graphby clicking anywhereon the title.
FFF,FfuFF|*"'4F&'E'
cFtA$-qli*LBul0l al ll rI
q
*.
$r
;l Jxr F4*.it.r":!..*
ltliL&{ il.dk'nl
39](https://image.slidesharecdn.com/howtousespss-140707154912-phpapp02/85/How-to-use-spss-44-320.jpg)












![Chapter5 PredictionandAssociation
A multiple linear regressionwas calculatedto predict participants'weight
basedon their height and sex.A significantregressionequationwas found
(F(2,13): 981.202,p < .001),with an R' of .993.Participants'predicted
weightis equalto 47.138- 39.133(SEX)+ 2.10l(HEIGHT),whereSEX is
coded as I = Male, 2 : Female,and HEIGHT is measuredin inches.
Participantsincreased2.101 pounds for each inch of height, and males
weighed 39.133 pounds more than females.Both sex and height were
significantpredictors.
The conclusionstatesthe direction(increase),strength(.993),value(981.20),de-
greesof freedom(2,13),and significancelevel (< .001)of the regression.In addition,a
statementof the equationitself is included.Becausetherearemultiple independent vari-
ables,we havenotedwhetheror noteachis significant.
Phrasing ResultsThat Are Not Significant
If the ANOVA does not find a
significantrelationship,the Srg section
of the output will be greaterthan .05,
and the regressionequationis not sig-
nificant. A resultssectionfor the output
at right might include the following
statement:
A multiple linear regressionwas
calculated predicting partici-
pants'ACT scoresbasedon their
height and sex. The regression
equation was not significant
(F(2,13): 2.511,p > .05)withan
R" of .279. Neither height nor
weight is a significantpredictor
of lC7" scores.
llorlel Surrrwy
XodBl x R Souare
AdtuslBd
R Souare
Std Eror of
528. t68 3 07525
a Prsdlclors:(ConslanD.se4hel9ht
a Pr€dictors:(ConslanD,se( hsight
o.OoDendBnlVaiabloracl
Coetllclst 3r
Yodel
Unstandardizsd
Cosilcisnls
Standardized
Coeilcionts
stdSld E.rol Beia
I (Constan0
h€l9hl
s€x
oJttl
- 576
-t o??
19.88{
.266
2011
-.668
- 296
3.102
2.168
- s62
007
019
35{
Notethatforresultsthatare
"o,
,ir";;;;ilJlovA resultsandR2resultsare
given,buttheregressionequationisnot.
Practice Exercise
UsePracticeDataSet2 in AppendixB. Determinethepredictionequationfor pre-
dictingsalarybasedoneducation,yearsof service,andsex.Whichvariablesaresignificant
predictors?If you believethatmenwerepaidmorethanwomenwere,whatwouldyou
concludeafterconductingthisanalysis?
ANI]VIP
gumof
dt qin
I Reoressron
Rssidual
Total
1t.191
122.9a1
't70.t38
l3
't5
23.717
9.a57
2.5rI i tn.
52](https://image.slidesharecdn.com/howtousespss-140707154912-phpapp02/85/How-to-use-spss-57-320.jpg)



![Chapter6 ParametricInferentialStatistics
term value (e.g.,comparingthe curent year's temperaturesto a historical averageto de-
termineif globalwanning is occuning).
Assumptions
The distributionsfrom which the scoresare takenshouldbe normally distributed.
However,the t testis robust andcanhandleviolationsof the assumptionof a normal dis-
tribution. Thedependentvariablemustbemeasuredon aninterval or ratio scale.
.SP,SSData Format
The SPSSdatafile for the single-sample/ testrequiresa singlevariablein SPSS.
That variablerepresentsthe setof scoresin the samplethatwe will compareto the popula-
tion mean.
Running the Command
The single-sample/ testis locatedin the CompareMeanssubmenu,under theAna-
lyzemenu.The dialog box for the single-sample/ testrequiresthat we transferthevariable
representingthe currentsetofscores ry
to the Test Variable(s) section. We i ArdvzeGraphswllties
must also enterthe populationaver-
agein the TestValueblank.The ex-
ample presentedhere is testing the
variableLENGTH againsta popula-
tion meanof 35 (thisexampleusesa
hypotheticaldataset).
Reports )
I SescripliveStati*icr ]
GenerallinearModel )
' CorrElata )
' Regrossion )
Clasdfy )
Indegrdant-SrmplCsT
Paired-SamplesTTert.,,
0ne-WeyANOVA,..
ReadingtheOutput
The output for the single-samplet test consistsof two sections.The first section
lists the samplevariableand somebasicdescriptive statistics(N, mean, standard devia-
tion, andstandarderror).
Wiidnrunrb
Mcrns.,,
56](https://image.slidesharecdn.com/howtousespss-140707154912-phpapp02/85/How-to-use-spss-61-320.jpg)









![Chapter6 ParametricInferentialStatistics
To conducta one-wayANOVA, click Ana-
lyze, then CompareMeans, then One-I7ayANOVA.
This will bring up the main dialog box for theOne-
lltayANOVA command.
xrded
f *wm
dtin"t
S instt.,ct
/ rcqulad
miqq|4^__
l':lirl:.,.
:J
f,'',I
R*gI
c*"d I
HdpI
i An$tea &ryhr l.{lith;
R;pa*tr )
DrrsFfivsft#l|' I
Csnalda
R!E'l'd6al
cl#y
lhcd friodd ] orn-5dtFh f f64...
I l|1|J46tddg.5arylarT16t,.,
) P*G+tunpbs I IcJt..,
rffillEil
wr$|f $alp
!qt5,l fqiryt,,,lodiors"'I
pela$t
/n*Jterm
d
'cqfuda
mrffi,.*-
-rl
ToKl
Ro"t I
c*ll
H&l
"?s'qt,.,l
Pqyg*-I odi"*.'.I
Click on the Options box to
get the Options dialog box. Click
Descriptive. This will give you
meansfor thedependentvariableat
eachlevel of the independentvari-
able. Checkingthis box preventsus
from having to run a separatemeans
command.Click Continueto return
to the main dialog box. Next, click
Post Hoc to bring up the Post Hoc
Multiple Comparisonsdialog box.
Click Tukev.thenContinue.
, Eqiolvdirnccs NotfudfiEd
.
r TY's,T2
l,?."*:,_: _l6{''6:+l.'od
t or*ol:: j
Sigflber! h,v!t tffi-
rc"'*i.'I r"ry{-l" H* |
Post-hoctestsare necessaryin the event of a significant ANOVA. The ANOVA
only indicatesif any groupis differentfrom any othergroup.If it is significant,we needto
determinewhich groupsaredifferent from which othergroups.We could do I teststo de-
terminethat,but we would havethe sameproblemasbeforewith inflating the Type I er-
ror rate.
Thereare a variety of post-hoccomparisonsthat correctfor the multiple compari-
sons.The most widely usedis Tukey's HSD. SPSSwill calculatea varietyof post-hoc
testsfor you. Consultanadvancedstatisticstext for a discussionof the differencesbetween
thesevarioustests.Now click OK to run the analvsis.
You shouldplacethe independ-
ent variable in the Factor box. For our
example, INSTRUCT representsthree
different instructors.and it will be used
asour independentvariable.
Our dependentvariable will be
FINAL. This test will allow us to de-
termine if the instructorhas any effect
on final sradesin thecourse.
f- Fncdrdr*dcndlscls
l* Honroga&olvairre,* j *_It J
66](https://image.slidesharecdn.com/howtousespss-140707154912-phpapp02/85/How-to-use-spss-71-320.jpg)
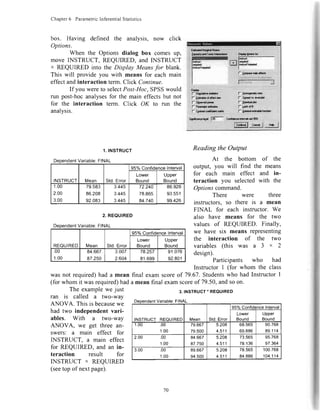
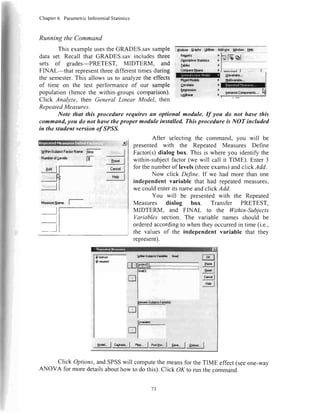
![Chapter6 ParametricInferentialStatistics
ReadingtheOutput
Descriptivestatisticswill begivenfor eachinstructor(i.e.,levelof theindepend-
entvariable)andthetotal.Forexample,in hisftrerclass,InstructorI hadanaveragefinal
examscoreof 79.57.
Descriptives
final
N Mean Std.Deviation Std.Enor
95%ConfidenceIntervalfor
Mean
Minimum MaximumLowerBound UooerBound
UU
2.00
3.00
Total
7
7
2'l
79.5714
86.4286
92.4286
86.1429
7.95523
10.92180
5.50325
9.63476
3.00680
4.12805
2.08003
2.10248
72.2',t41
76.3276
87.3389
81.7572
86 9288
96.5296
97.5182
90.5285
tiv.uu
69.00
83.00
69.00
6Y.UU
100.00
100.00
100.00
The next sectionof
the output is the ANOVA
sourcetable.This is where
the various componentsof
the variance have been
listed,alongwith their rela-
tive sizes.For a one-wayANOVA, thereare two componentsto the variance:Between
Groups(which representsthe differencesdue to our independentvariable) and Within
Groups(whichrepresentsdifferenceswithin eachlevelof our independentvariable).For
our example,the BetweenGroupsvariancerepresentsdifferencesdue to different instruc-
tors.The Within Groupsvariancerepresentsindividualdifferencesin students.
The primaryansweris F. F is a ratio of explainedvariance to unexplainedvari-
ance.Consulta statisticstext for moreinformationon how it is determined.The F hastwo
differentdegreesof freedom,onefor BetweenGroups(in this case,2is the numberof lev-
elsof our independentvariable [3 - l]), andanotherfor Within Groups(18 is thenumber
of participantsminusthenumberof levelsof our independentvariable [2] - 3]).
The next part of the output consistsof the resultsof our Tukey's ^EISDpost-hoc
comparison.
This tablepresentsus with everypossible
ent variable. The first row representsInstructor
structor I compared to
Instructor 3. Next is In- Dooendenrvariabre:F,NAL
structor 2 compared to
Instructor l. (Note that
this is redundantwith the
first row.) Next is Instruc-
tor 2 comparedto Instruc-
tor 3, andsoon.
The column la-
beled Sig. representsthe
Type I error (p) rate for
the simple(2-level)com-
parisonin that row. In our
combinationof levelsof our independ-
I comparedto Instructor2. Next is In-
Multlple Comparlsons
579.429
1277.143
1856.571
HSD
(t) (J)
INSTRUCT INSTRUCT
Mean
Difference
Il-.tl Sld. Enor Sia
95% Confidence
Lower
Bound
Upper
R6r rn.l
1.00 2.OU
3.00
€.8571
-12.8571'
4.502
4.502
JU4
.027
-16.J462
-24.3482
4.6339
-1.3661
2.00 1.00
3.00
6.8571
-6.0000
4.502
4.502
.304
.396
-4.6339
-17.4911
18.3482
5,4911
3.00 1.00
2.00
12.8571'
6.0000
4.502
4.502
.027
.396
1.3661
-5.4911
24.3482
17.4911
'. The meandiffer€nceis significantat the .05 level.
67](https://image.slidesharecdn.com/howtousespss-140707154912-phpapp02/85/How-to-use-spss-72-320.jpg)












![Chapter6 ParametricInferentialStatistics
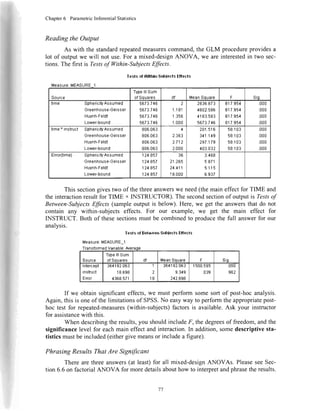
Phrasing ResultsThatAre Significant
If we had received
the following output instead,
we would have had a
significant MANOVA, and
we could statethe following:
a Exatlslalistic
b.Thestausticis anuppsrboundonFhalyisldsa lffisr boundonthesiqnitcancBlml
c.Desi0n:Intercepl+0roup
Ieir oaSrtrocs|alEl. Effoda
Sourca OsoandahlVa.i
Typelllgum
dl xean si0
corected todet sat
gf8
62017.tt8'
963tt att!
2
2
31038.889
13'1t2.222
t.250
9.r65
006
002
htorc€pt Sat
ue
5859605.556
5997338.889
5859605.556
5997338.8S9
I 368.711
I 314.885
000
000
gfoup sal
ore
620tt.t78
863arala
2 31038.089
431t2.222
|.250
9.t65
006
002
Erol sat
0rs
61216 667
6S||6 667
15
15
4281.11',l
1561.,|'rr
T0lal
ote
5985900.000
6152r00000
18
Cor€cled Tolal sal
0re
126291.444
1517611|1 l7
A one-wayMANOVA wascalculatedexaminingtheeffectof training(none,
short-term,long-term)onMZand GREscores.A significanteffectwasfound
(Lambda(4,28)= ,423,p: .014).Follow-upunivariateANOVAs indicated
thatSATscoresweresignificantlyimprovedby training(F(2,15): 7.250,p :
.006).GREscoreswerealsosignificantlyimprovedby training(F(2,15):
9'465,P = '002).
Phrasing ResultsThatAre Not Significant
Theactualexamplepresentedwasnotsignificant.Therefore,wecouldstatethefol-
lowingin theresultssection:
A one-wayMANOVA wascalculatedexaminingtheeffectof training(none,
short-term,or long-term)onSIZ andGREscores.No significanteffectwas
found(Lambda(4,28)= .828,p > .05).NeitherSATnor GREscoreswere
significantlyinfluencedbytraining.
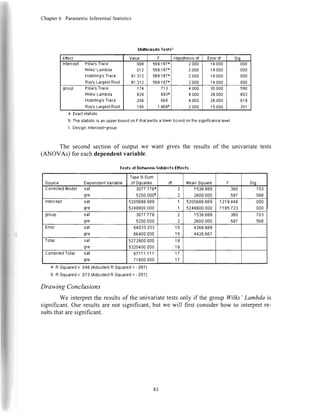
llldbl.Ielrc
Ertscl value d] Frr6t dl Srd
Inlercepl PillaIsTrace
Wilks'Lambda
Holsllln0'sT€cs
RoYsLargsslRoot
.989
.0tI
91.912
91.912
613.592.
6a3.592.
6t3.592.
613.592.
2.000
2.000
2000
2.000
t.000
r.000
1.000
{.000
.000
.000
.000
.000
group piilai's Trec€
Wllks'Lambda
HolellingbTrace
Roy's Largsst Rool
.579
.123
t .350
1 n{o
3.157.
1.t01
't0.t25r
| 000
I 000
I 000
2.000
30.000
28.000
26.000
I 5.000
032
011
008
002
84](https://image.slidesharecdn.com/howtousespss-140707154912-phpapp02/85/How-to-use-spss-90-320.jpg)






![Chapter7 NonparametricInferentialStatistics
,SPS,SData Format
Thiscommandrequiresa singlevariablerepresentingthedependentvariableand
asecondvariableindicatinggroupmembership.
Running the Command
This examplewill use a new data
file. It representsl2 participantsin a series
of races.There were long races,medium
races, and short races. Participantseither
had a lot of experience (2), some
experience(l), or no experience(0).
Enter the data from the figure at
right in a new file, and savethe datafile as
RACE.sav. The values for LONG.
MEDIUM, and SHORT represent the
resultsof the race,with I being first place
and12beinglast.
To run the command,click Analyze,thenNon-
parametric Tests, then 2 Independent Samples. This
willbring up themaindialogbox.
Enterthe dependentvariable (LONG, for this
example)in the TestVariableList blank. Enterthe in-
dependentvariable (EXPERIENCE)as the Grouping
Variable.Make surethatMann-WhitneyU is checked.
Click DefineGroupsto selectwhich two groups
you will compare.For this example,we will compare
thoserunnerswith no experience(0) to those runners
with a lot of experience(2). Click OK to run the
analvsis.
iTod Tiryc**-
il7 Mxn.dWn6yu I_ Ko&nonsov'SrnirnovZ
I
l- Mosasa<tcnproactkmc l- W#.Wdrowfrznnrg
I Andy* qaphr U*lx
i R.po.ti ,
I Doroht*o1raru.r ,
Cd||olaaMcrfE t
| 6onralthccl'lodd I
j C*ru|*c )
r Rooa!33hn
'
i cta*iry )
j DatrRoddton )
' Sada )
:@e@J llrsSarfr t
I Q.s*y Cr*rd t
I BOCCuv.,,,
O$squr.,..
thd|*rl...
Rur...
1-sdTpbX-5,..
rl@ttsstpht,.,
eRlnand5{ndnr,,,
KRdetcdsrmplo*.,,
nl 3
nl
'
ei--'
---
n]' rf
bl 2:
liiiriil',,,-5J
IKJ
],TYTI
fry* |
l*J
WMw lbb
[6 gl*l
| &r*!r*l
C.,"* |
ryl
GnuphgVadadr:
fffii0?r-*
l ; ..' ,''r 1,
9l](https://image.slidesharecdn.com/howtousespss-140707154912-phpapp02/85/How-to-use-spss-98-320.jpg)

























![r{
ril
AppendixE
Informationfor Users
of EarlierVersionsof SPSS
Therearea numberof differencesbetweenSPSS15.0andearlierversionsof the
software.Fortunately,mostof themhavevery little impacton usersof thistext.In fact,
mostusersof earlierversionswill beableto successfullyusethistextwithoutneedingto
referencethisappendix.
Variable nameswere limited to eight characters.
Versionsof SPSSolderthan12.0arelimitedto eight-charactervariablenames.The
othervariablenamerulesstillapply.If youareusinganolderversionof SPSS,youneedto
makesureyouuseeightor fewerlettersforyourvariablenames.
The Data menu will look different.
The screenshotsin the text where the Data
menuis shownwill look slightly differentif you are
using an older versionof SPSS.Thesemissingor
renamedcommandsdo not have any effect on this
text,but themenusmay look slightly different.
If you are using a versionof SPSSearlier
than 10.0,theAnalyzemenuwill be calledStatistics
instead.
Graphing functions.
Priorto SPSS12.0,thegraphingfunctionsof SPSSwerevery limited.If youare
using a versionof SPSSolder than version12.0,third-partysoftwarelike Excel or
SigmaPlotis recommendedfor theconstructionof graphs.If youareusingVersion14.0of
thesoftware,useAppendixF asanalternativeto Chapter4,whichdiscussesgraphing.
Dsta TlrBfqm rn4aa€ getu t
oe&reoacs,.,
r hertYffd,e
l|]lrffl Clsl*t
GobCse",,
l19](https://image.slidesharecdn.com/howtousespss-140707154912-phpapp02/85/How-to-use-spss-124-320.jpg)
![Appendix E Informationfor Usersof EarlierVersionsof SPSS
Variableiconsindicatemeasurementtype.
In versionsof SPSSearlier
than 14.0,variableswererepresented
in dialog boxes with their variable
label and an icon that represented
whether the variable was string or
numeric(the examplehereshowsall
variablesthatwerenumeric).
Starting with Version 14.0,
SPSSshows additional information
about eachvariable.Icons now rep-
resentnot only whethera variableis
numericor not, but alsowhat type of
measurementscale it is. Nominal
variablesare representedby the &
icon. Ordinal variables are repre-
sentedby the dfl i.on. Interval and
ratio variables(SPSSrefersto them
as scale variables) are represented
bv the d i"on.
It liqtq'ftc$/droyte
sqFr*u.,|4*r.-r-lqql{.,I
SeveralSPSSdatafilescannowbeopenat once.
Versionsof SPSSolder than 14.0could haveonly one datafile open at a time.
Copying data from one file to another entailed a tedious processof copying/opening
files/pastingletc.Startingwith version 14.0,multiple data files can be open at the same
time. When multiple files areopen,you canselecttheoneyou want to work with usingthe
Windowcommand.
md* Heb
t|sr
$$imlzeA[Whdows
f Mlcrpafr&nlm
/srsinoPtrplecnft
/ itsscpawei[hura
/v*tctaweir**&r
/TimanAccAolao
$ Cur*ryUOrlgin1c I
ClNrmlcnu clrnaaJ
dq$oc.t l"ylo.:J
lCas,sav [Dda*z] - S55 DctoEdtry
t20](https://image.slidesharecdn.com/howtousespss-140707154912-phpapp02/85/How-to-use-spss-125-320.jpg)







![]1
AppendixF GraphingDatawithSPSS13.0and14.0
Runningthe Command
Click Graphs,thenBar for eithertypeof barchart.
Thiswill opentheBarChartsdialogbox.If youhaveone
independentvariable, selectSimple.If you havemore
thanone,selectClustered.
If you areusinga between-subjectsdesign,select
Summariesfor groups of cases.If you are using a re-
peated-measuresdesign, select Summariesof separate
variables.
If you arecreatinga repeatedmeasuresgraph,you
will seethedialogboxbelow.Moveeachvariableoverto
theBarsRepresentarea,andSPSSwill placeit insidepa-
renthesesfollowingMean.Thiswill giveyoua graphlike
the onebelowat right. Note that this exampleusesthe
GRADES.savdataenteredin Section6.4(Chapter6).
lr#
I t*ls
o rhd
Practice Exercise
UsePracticeDataSetI in AppendixB. Constructa bargraphexaminingtherela-
tionshipbetweenmathematicsskillsscoresandmaritalstatus.Hint: In theBarsRepresent
area.enterSKILL asthevariable.
t29](https://image.slidesharecdn.com/howtousespss-140707154912-phpapp02/85/How-to-use-spss-134-320.jpg)

This document provides an overview of starting SPSS and entering data. It discusses starting SPSS, defining variables, entering data for sample students, saving data files, and loading data files. Key steps include defining variables in the Variable View window by naming them and adding value labels, entering data horizontally in the Data View window, and saving files with a .sav extension so they can be opened later in SPSS.











































![SPSS Lecture_1 [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/spsslecture1autosaved-231105165336-b29c7b18-thumbnail.jpg?width=640&height=640&fit=bounds)



















