Downloaded 26 times



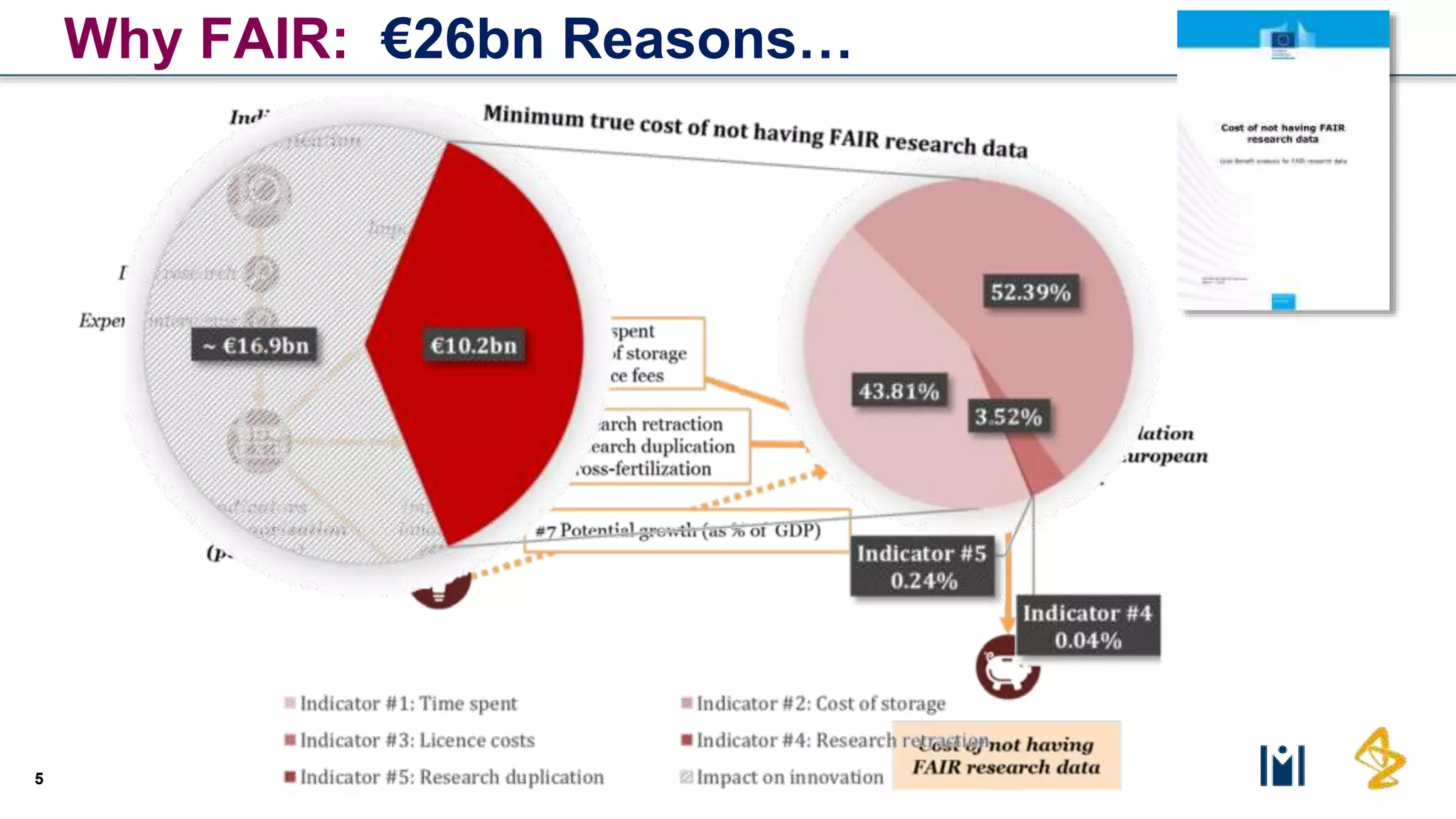

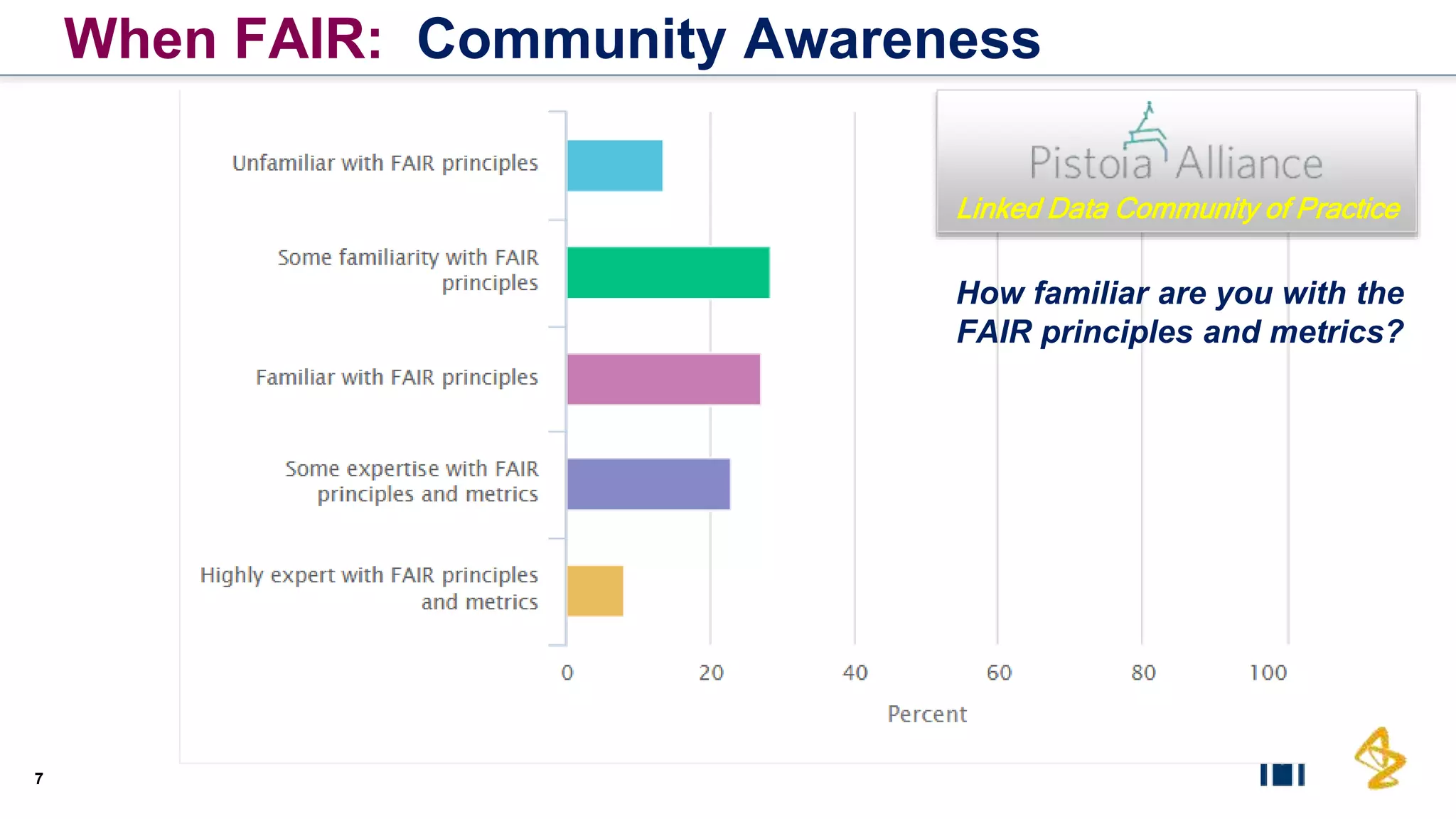
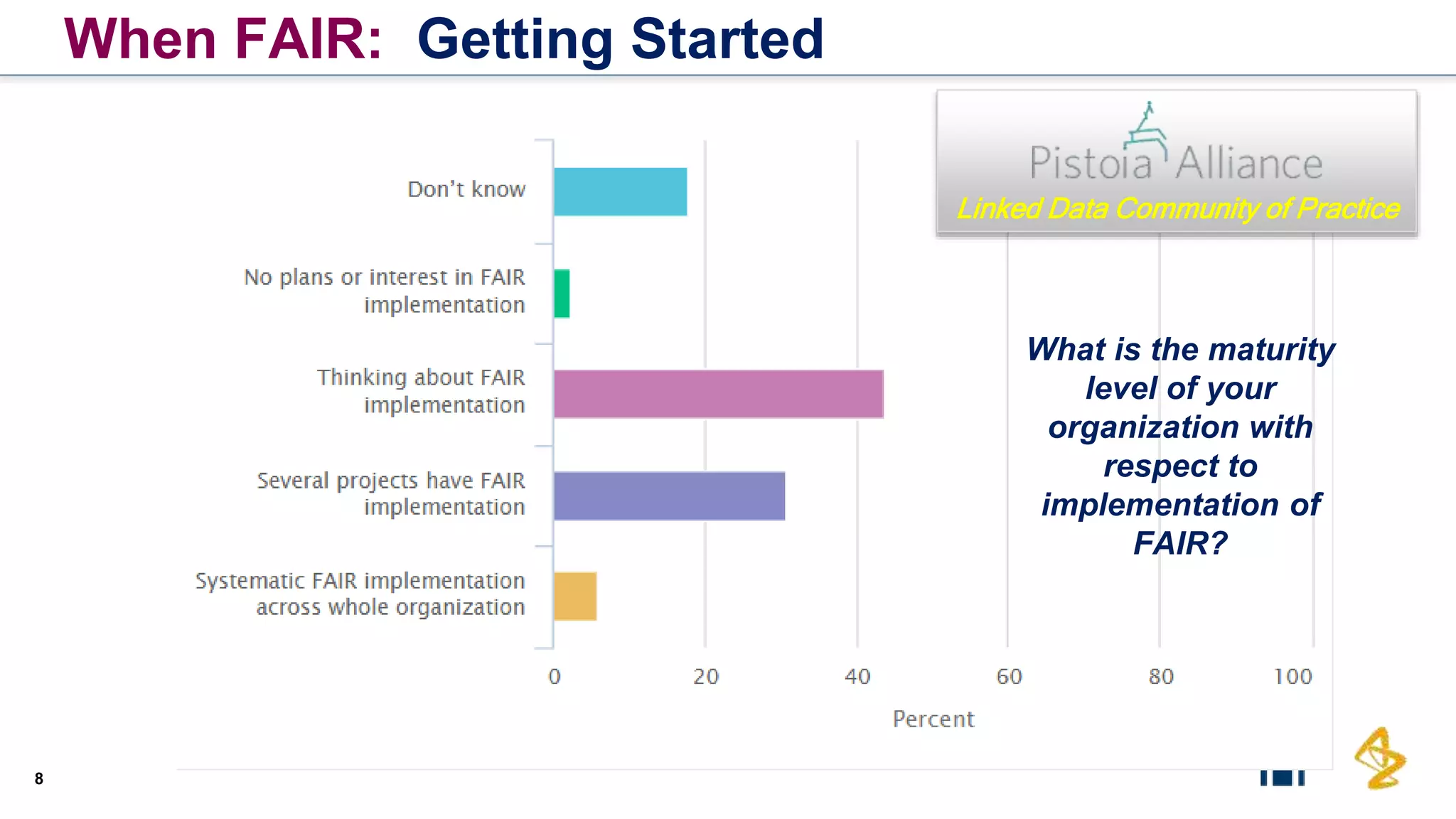

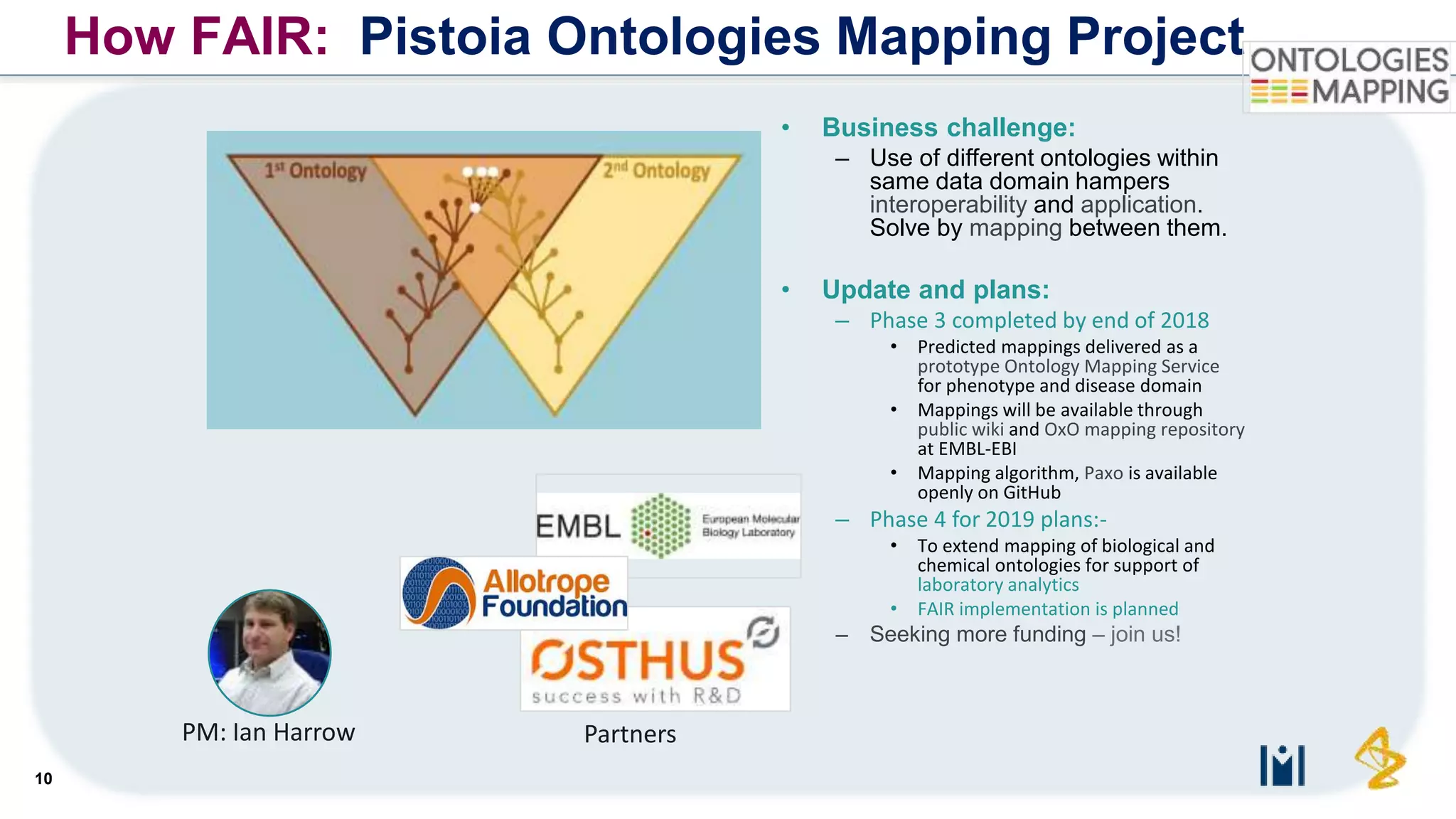
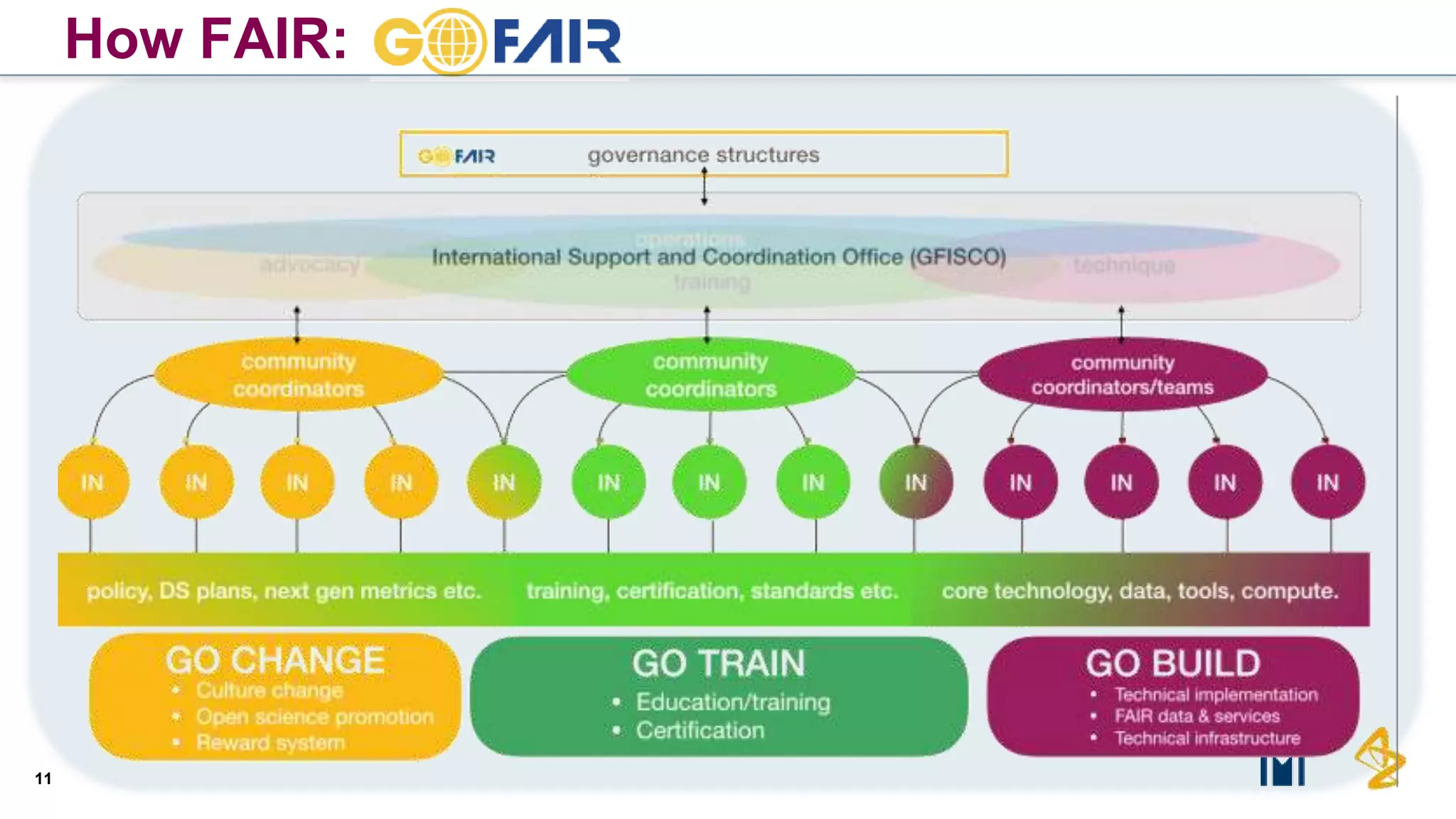


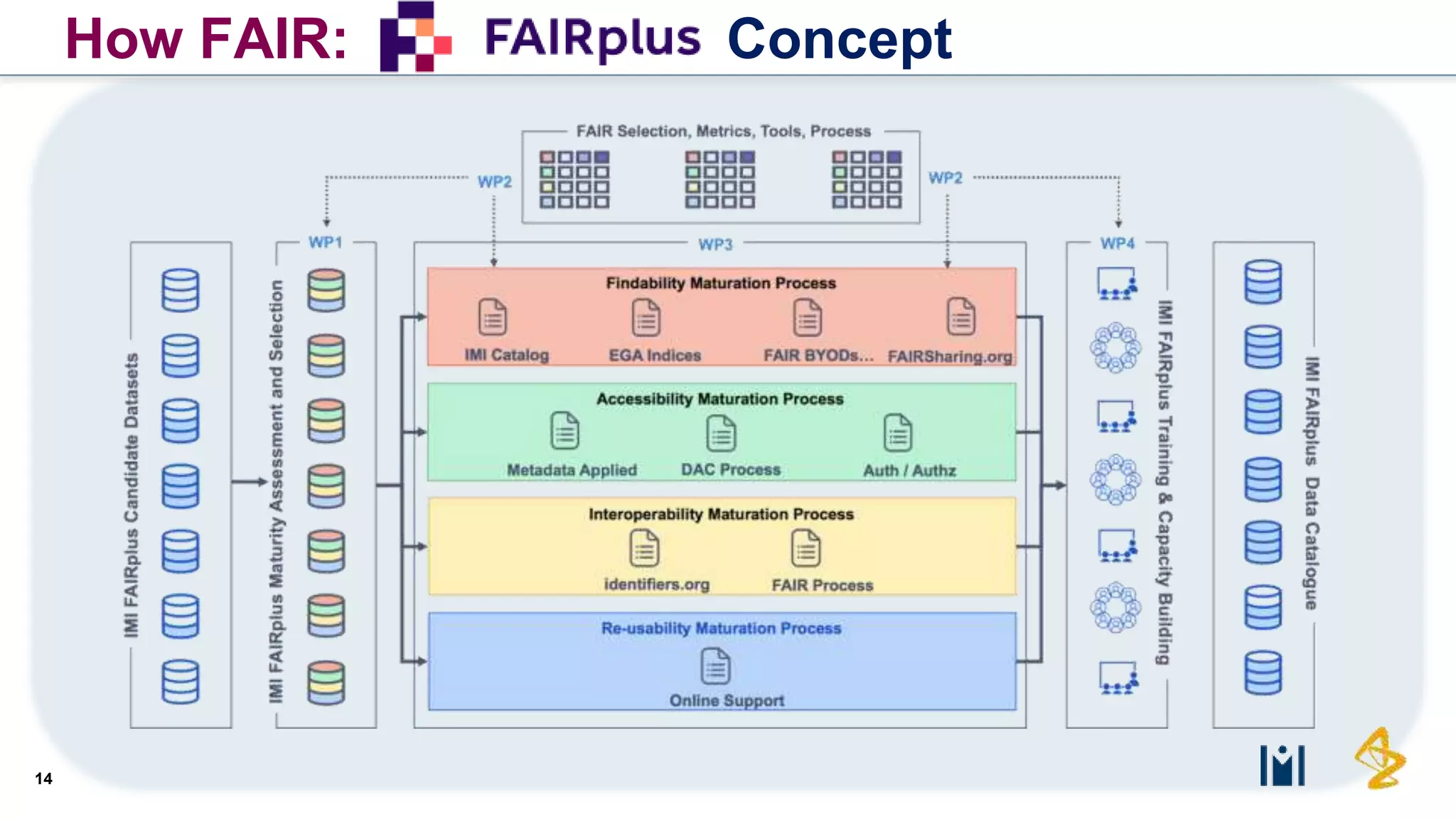
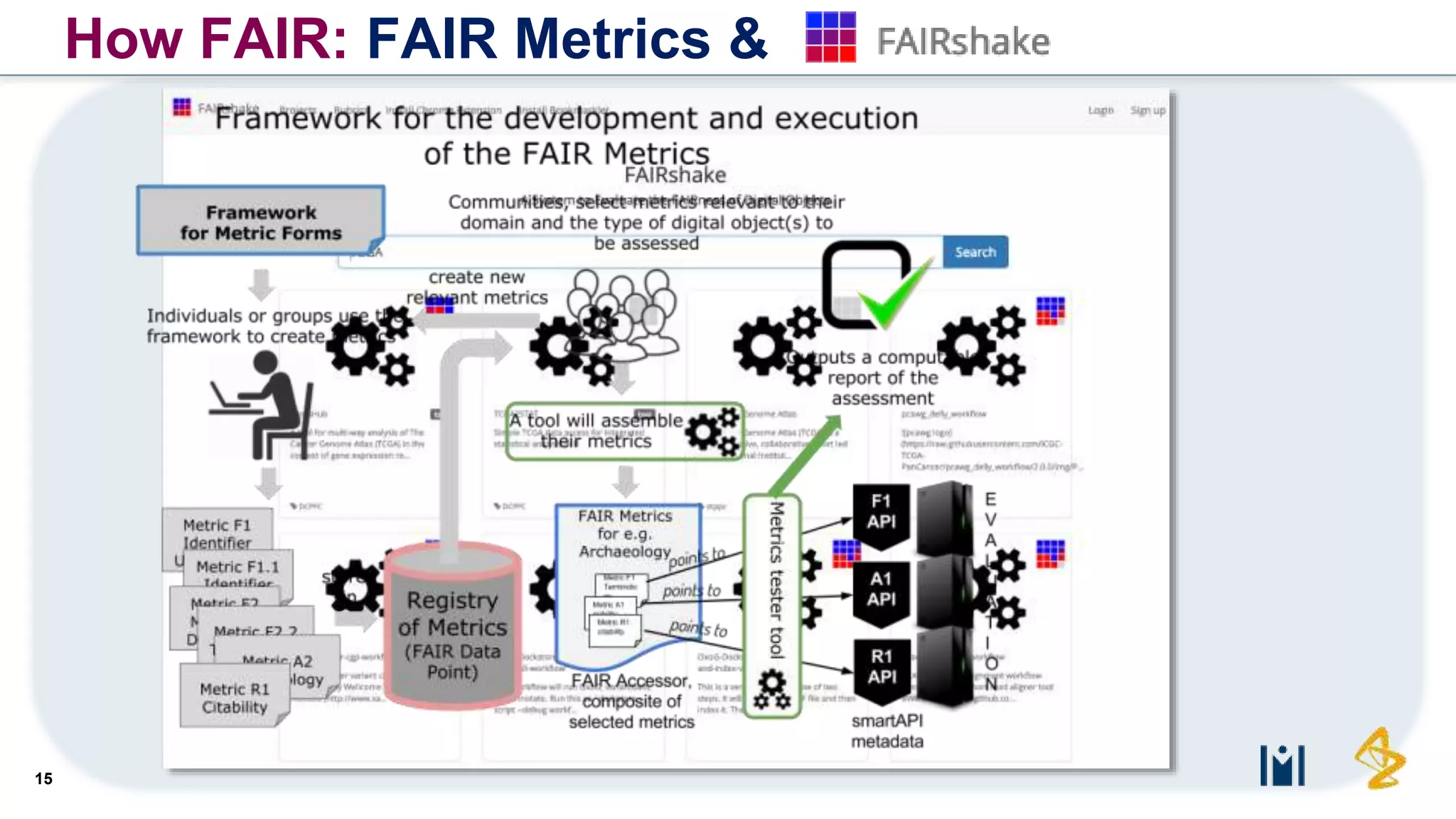
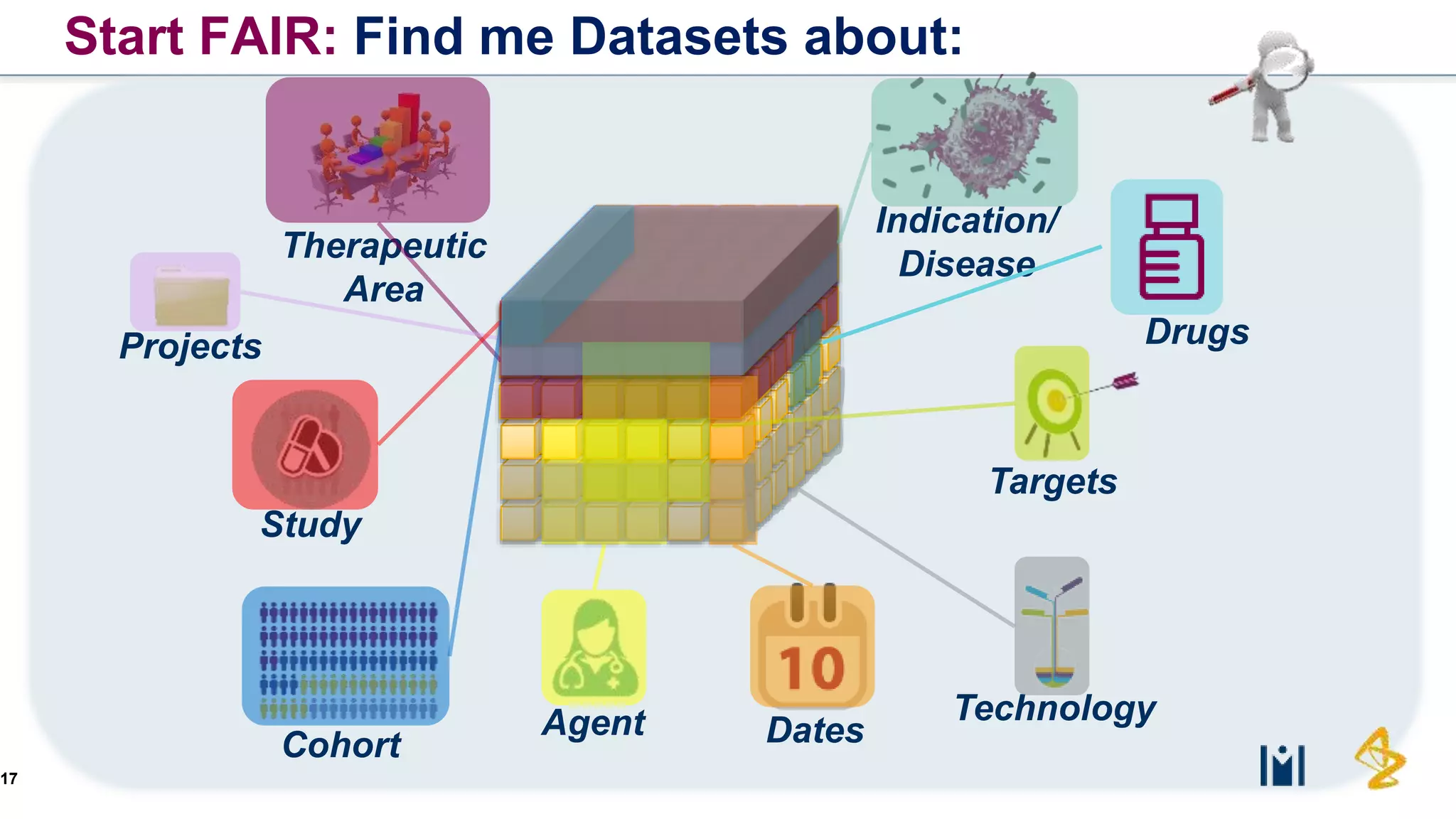

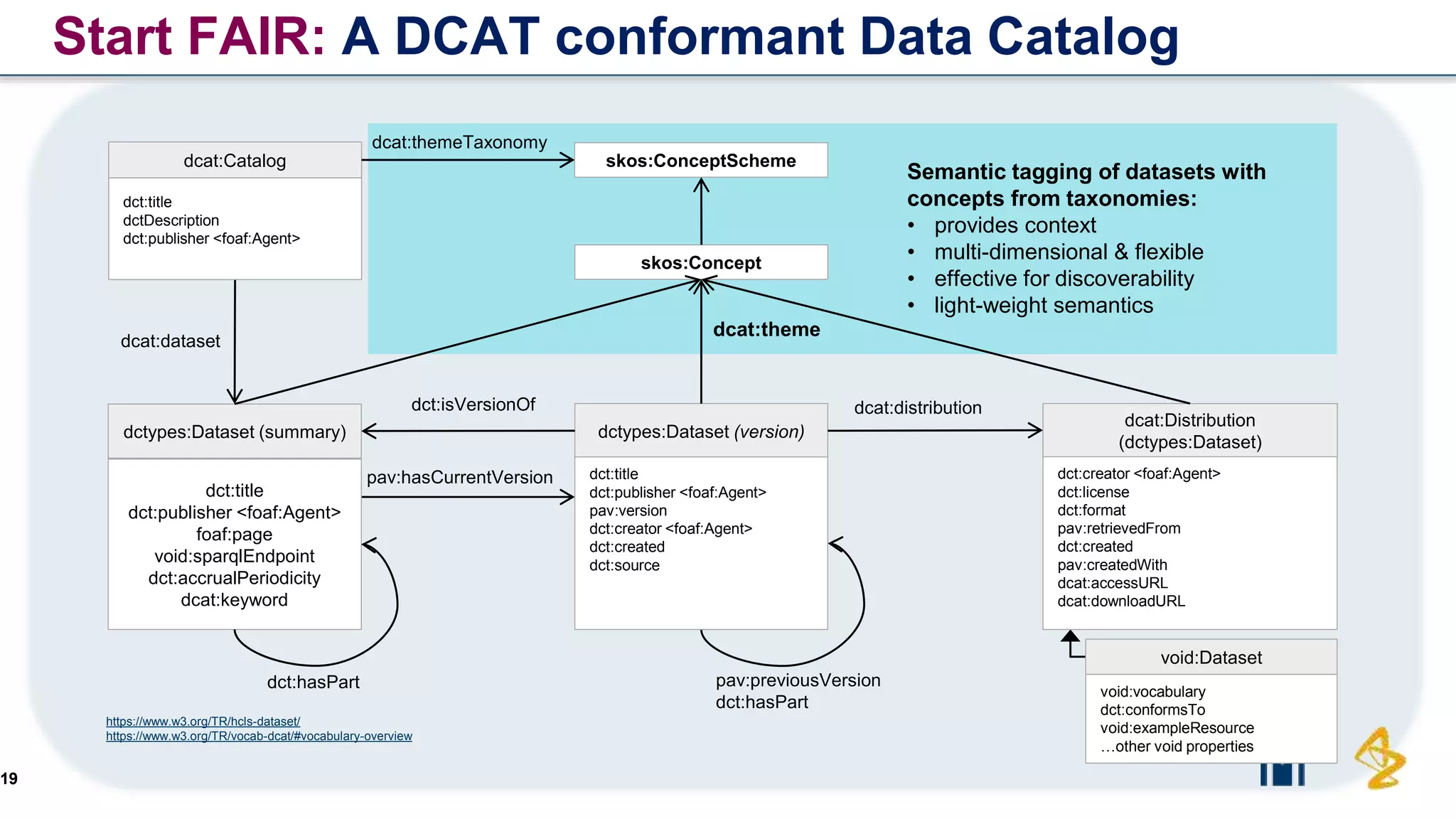
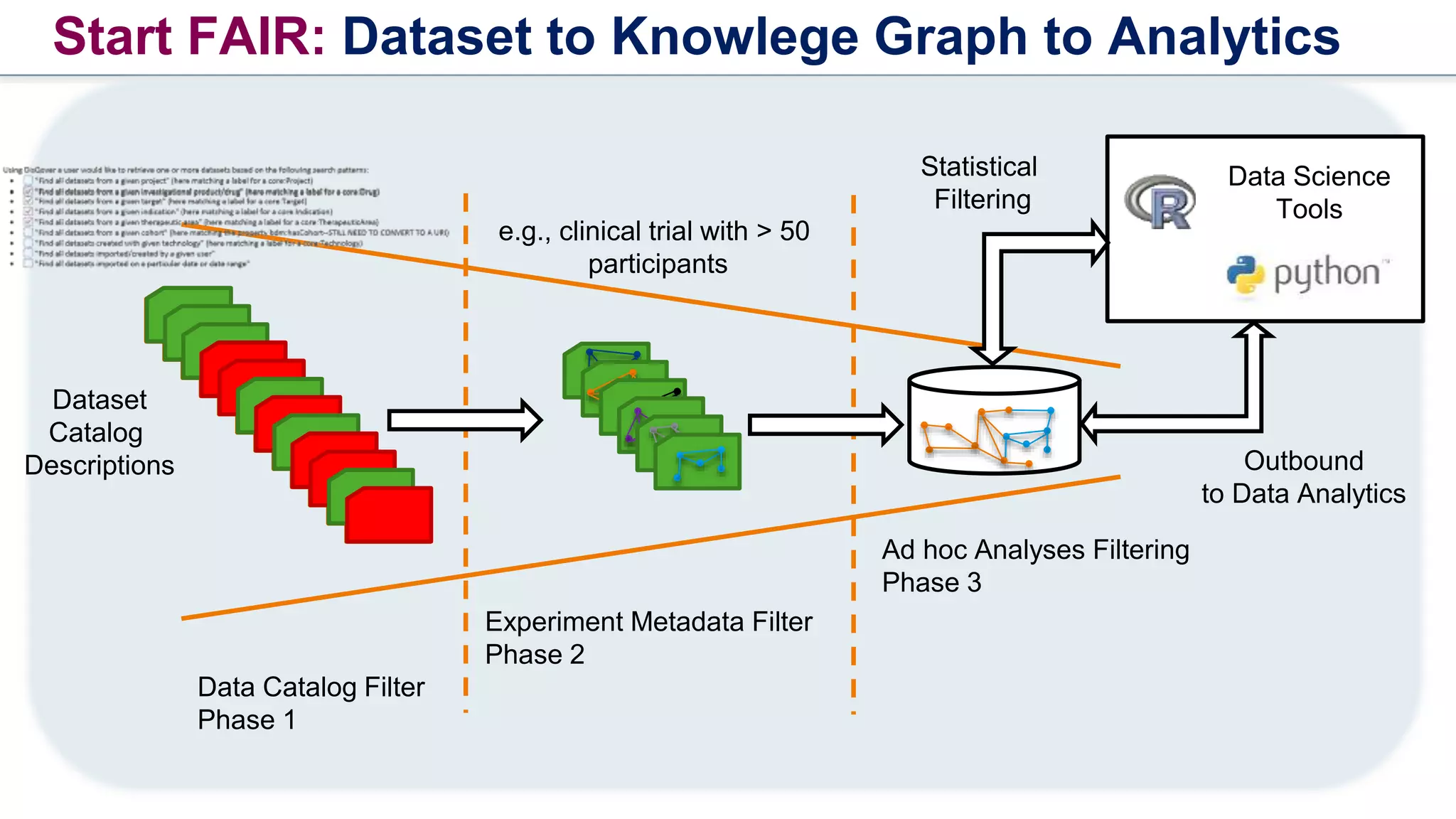



The document outlines the FAIR principles for scientific data management, emphasizing that data should be Findable, Accessible, Interoperable, and Reusable. It discusses the importance of implementing these principles within the life sciences to foster collaboration, improve patient care, and enhance data reproducibility. The document also highlights ongoing efforts and workshops aimed at integrating FAIR practices into research and industry workflows.





































































