Download as PDF, PPTX


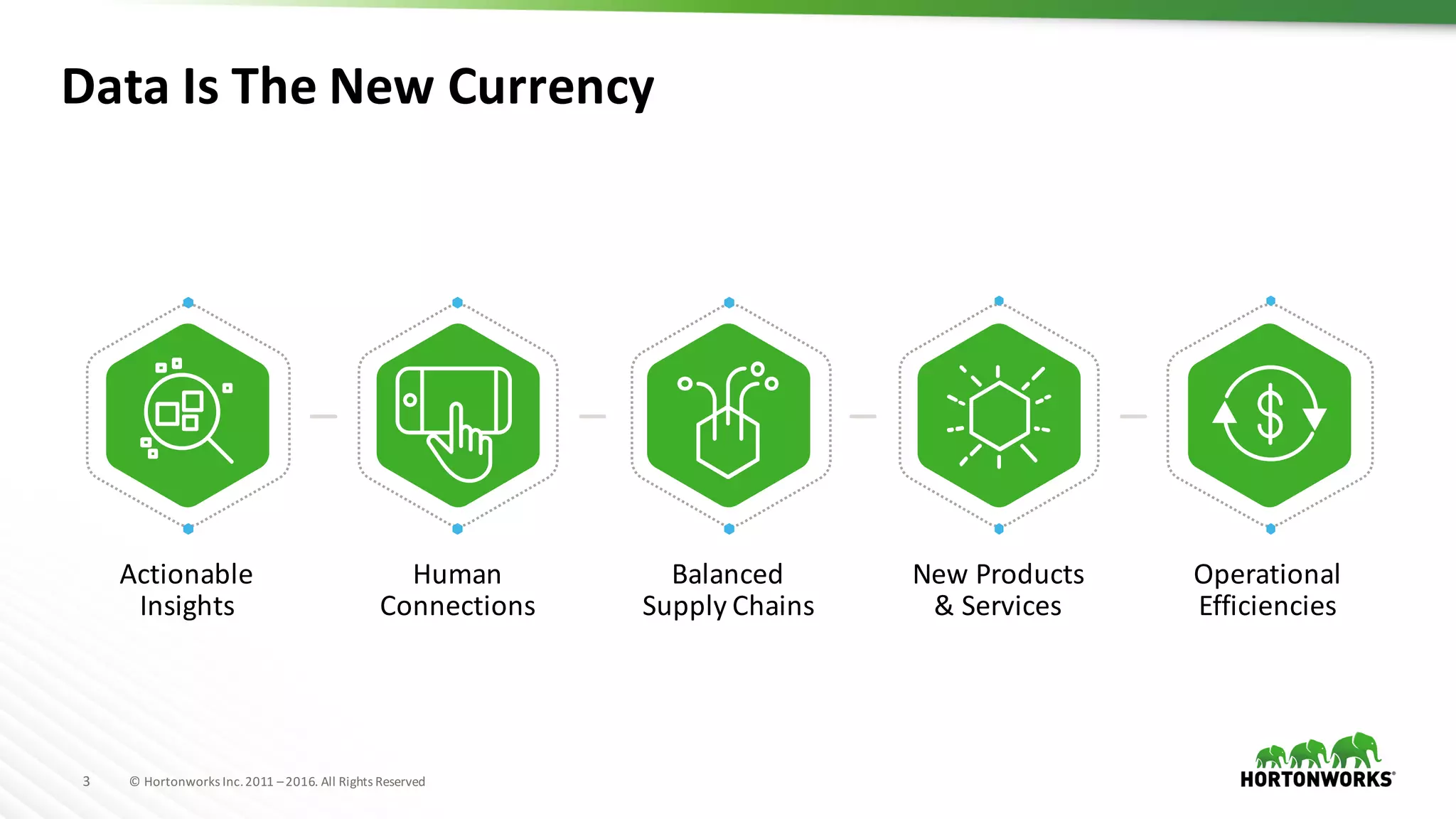
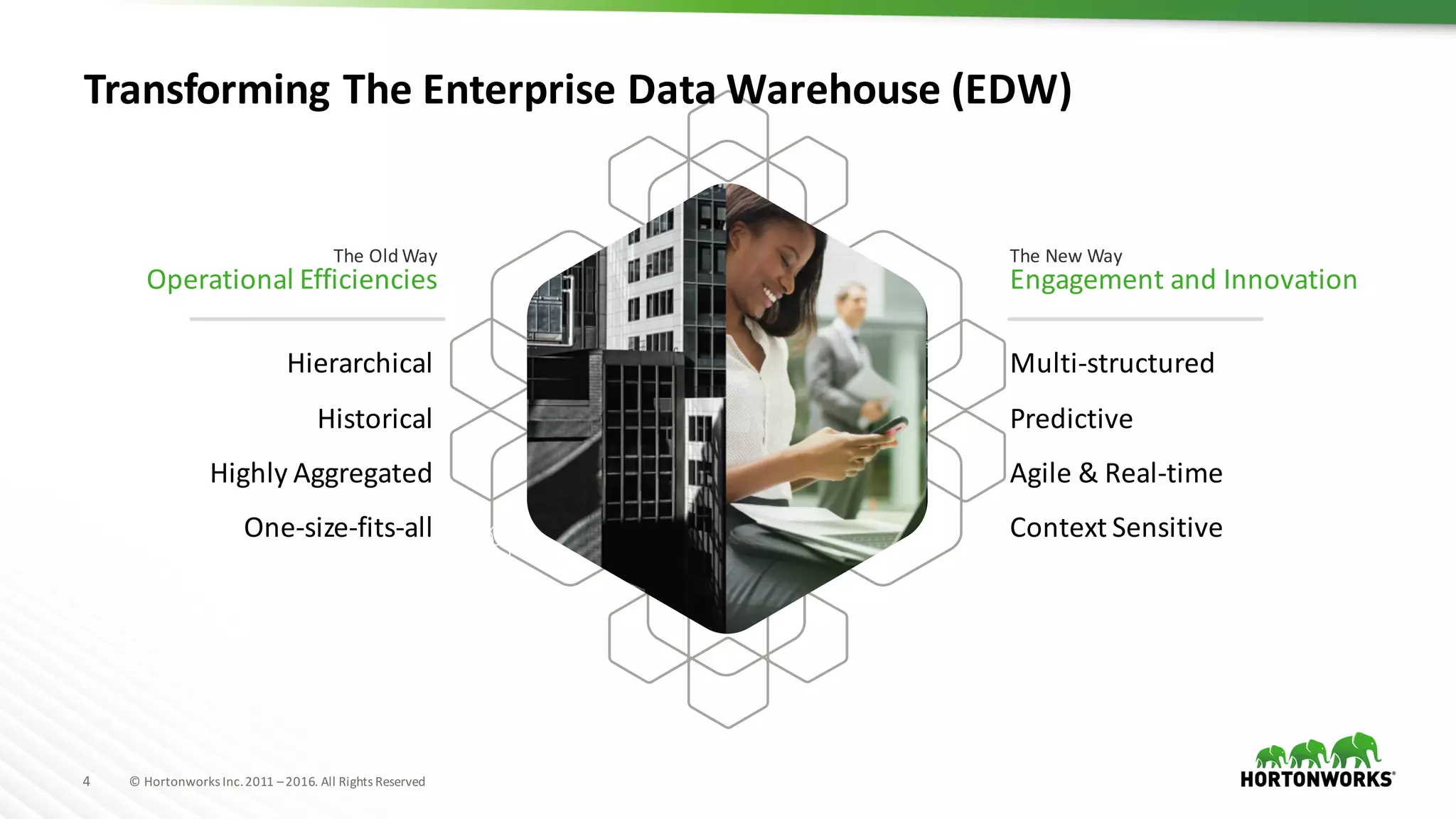
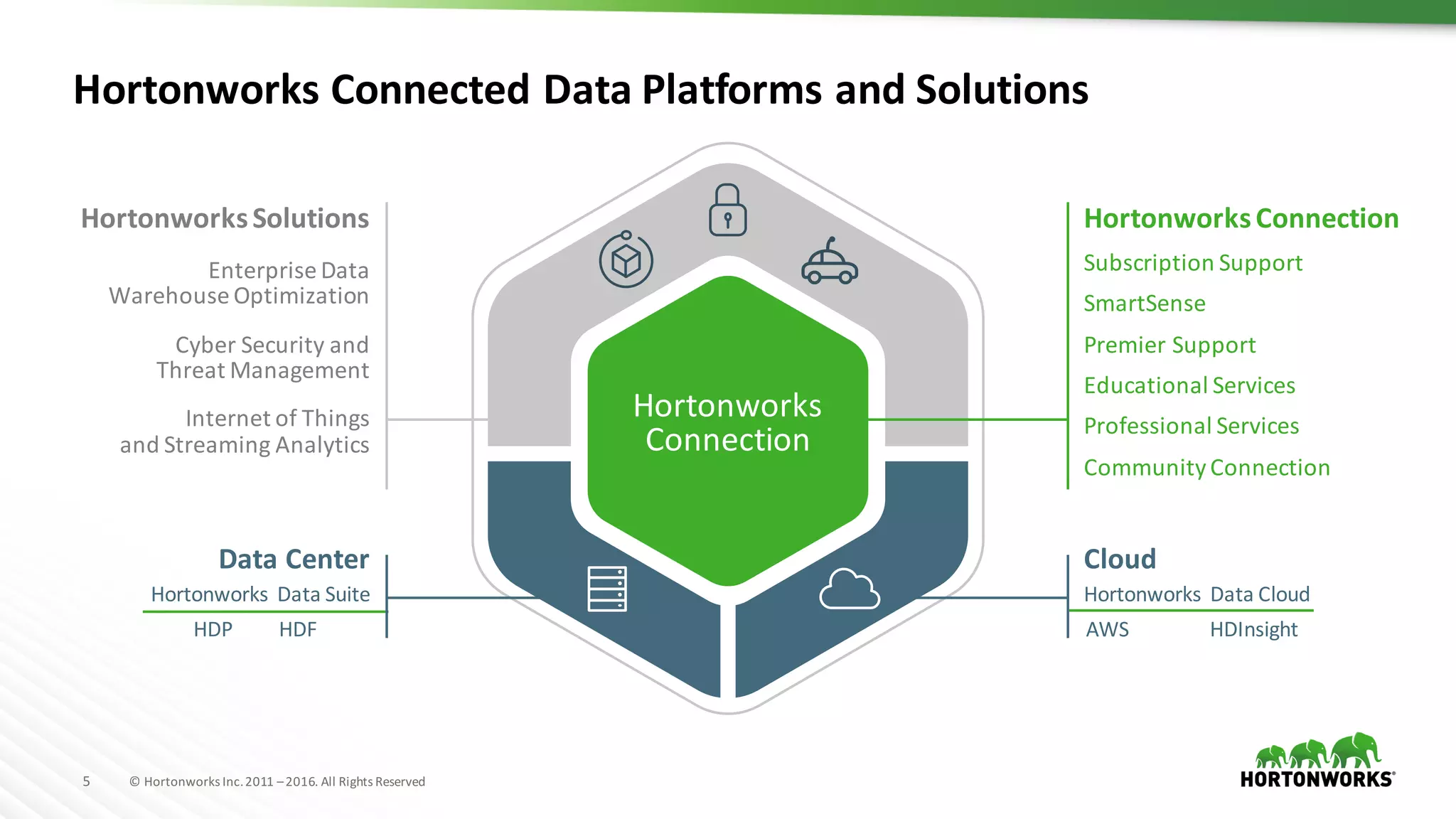

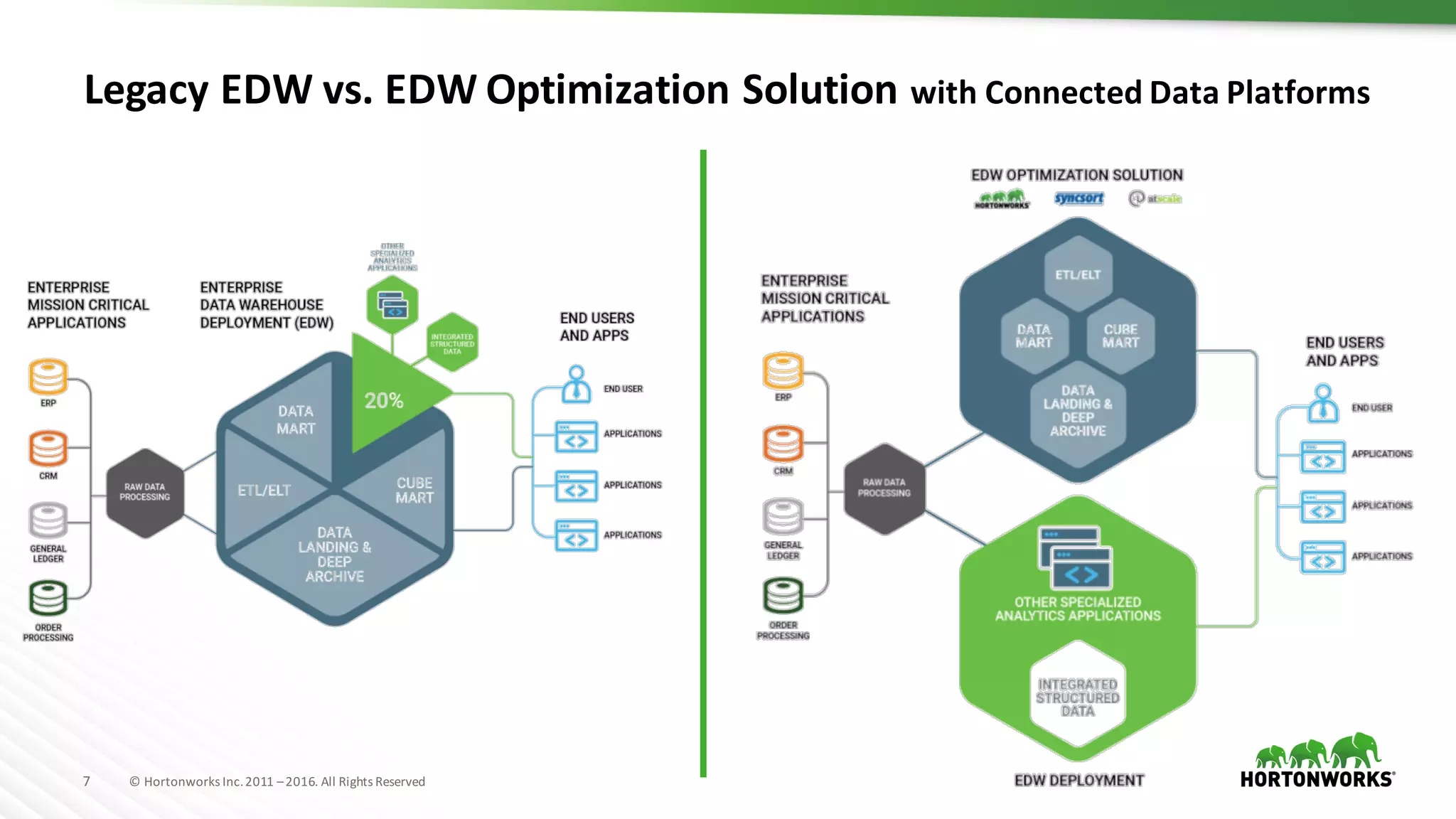
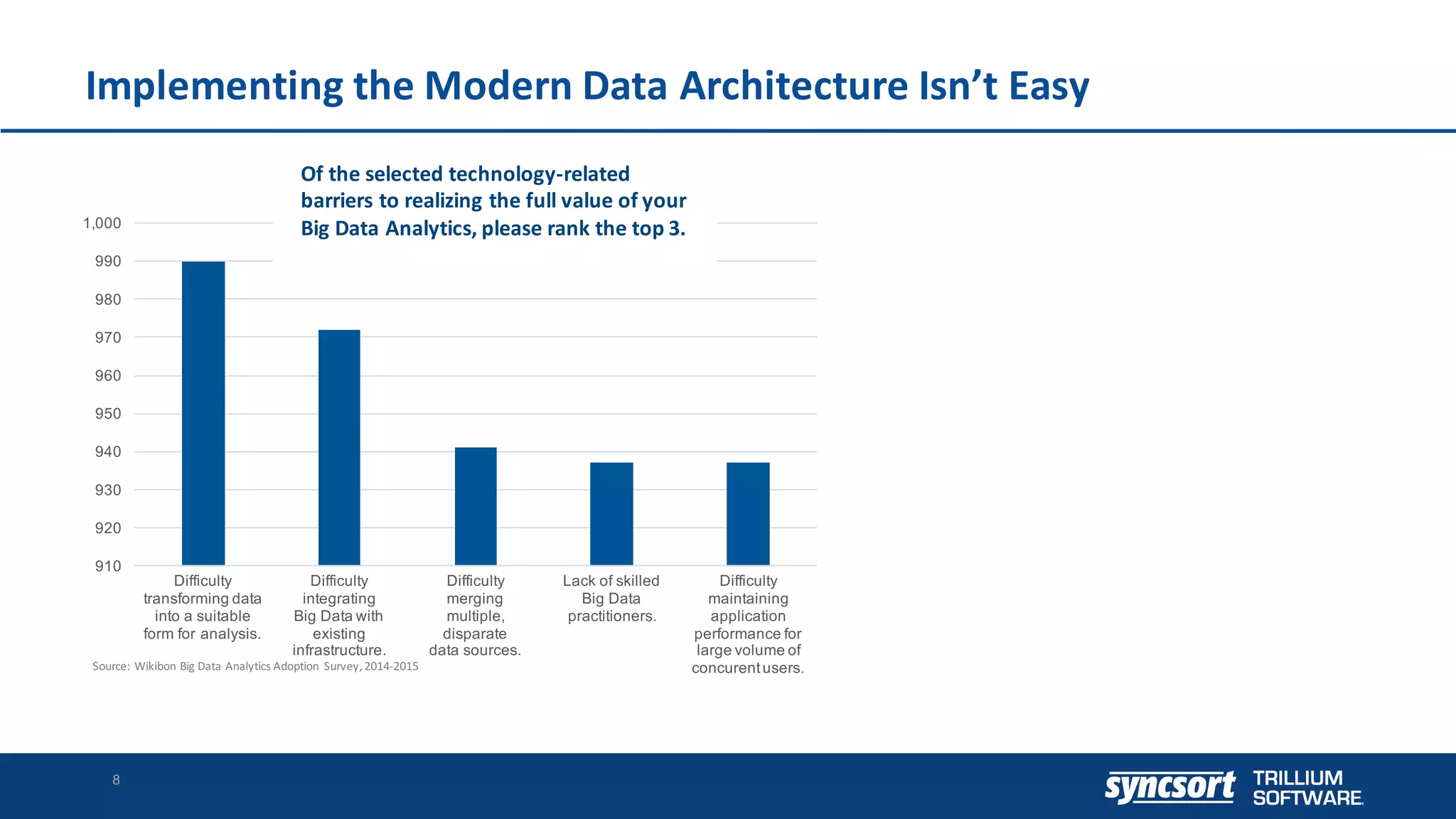
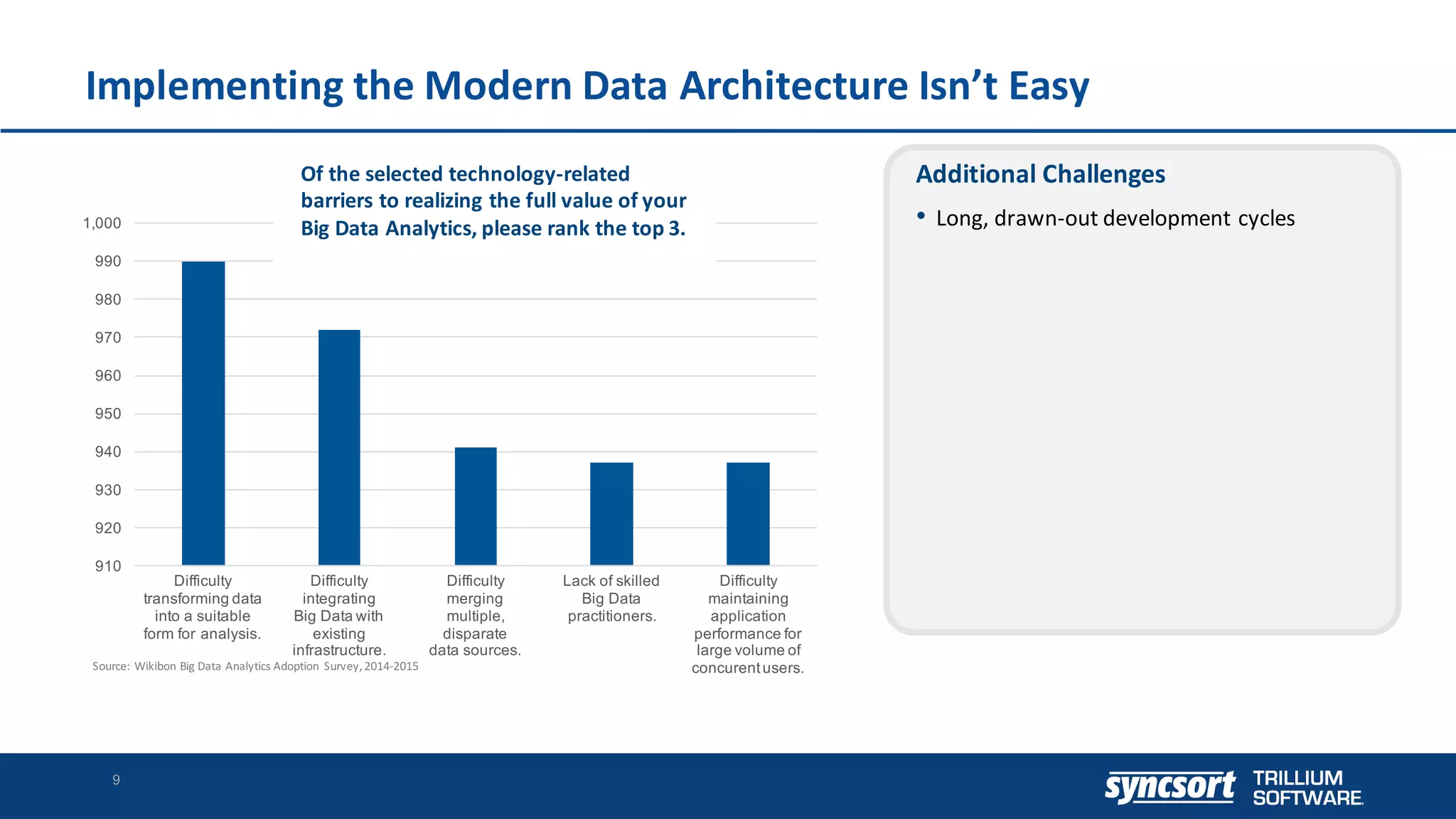
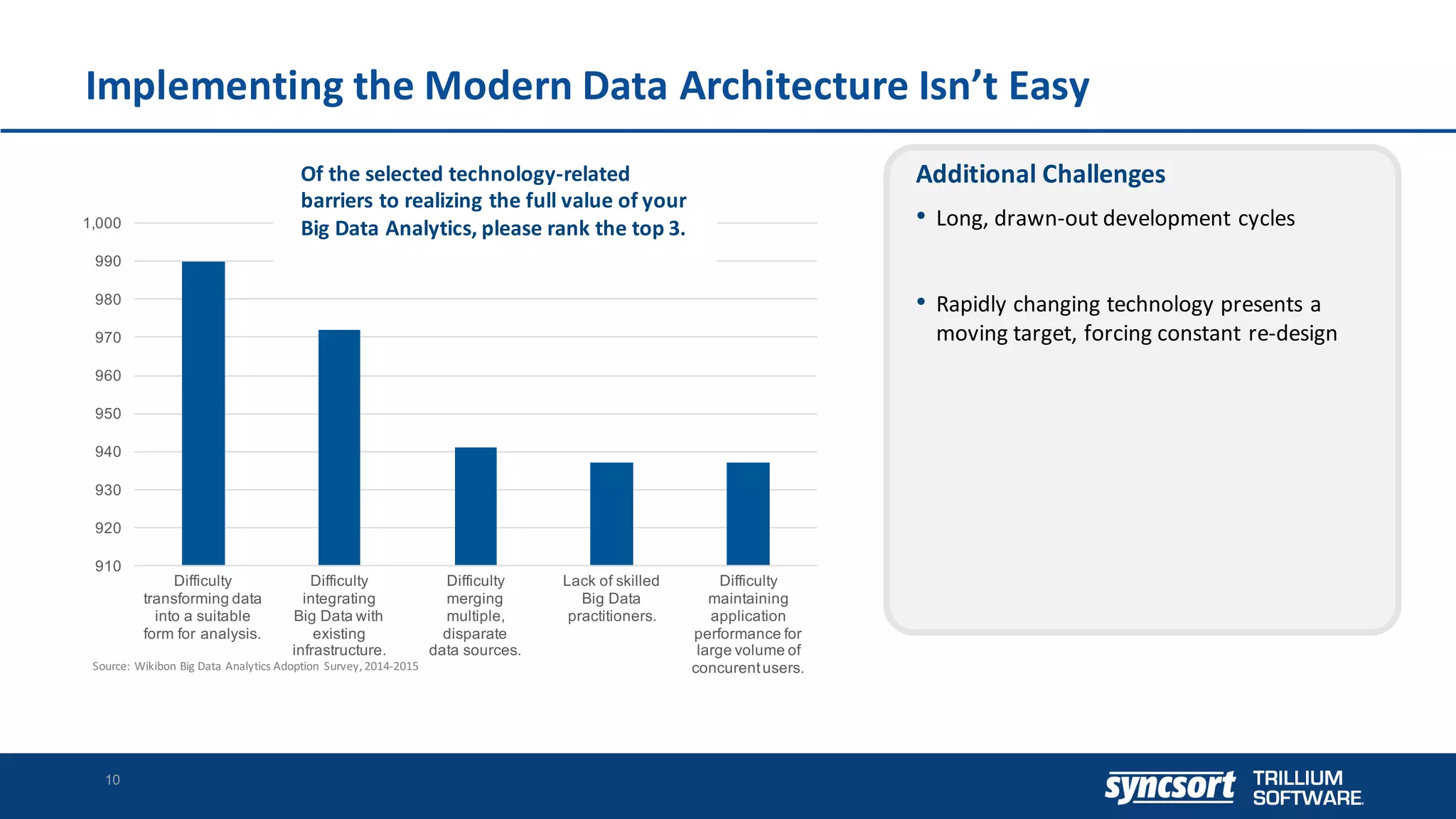
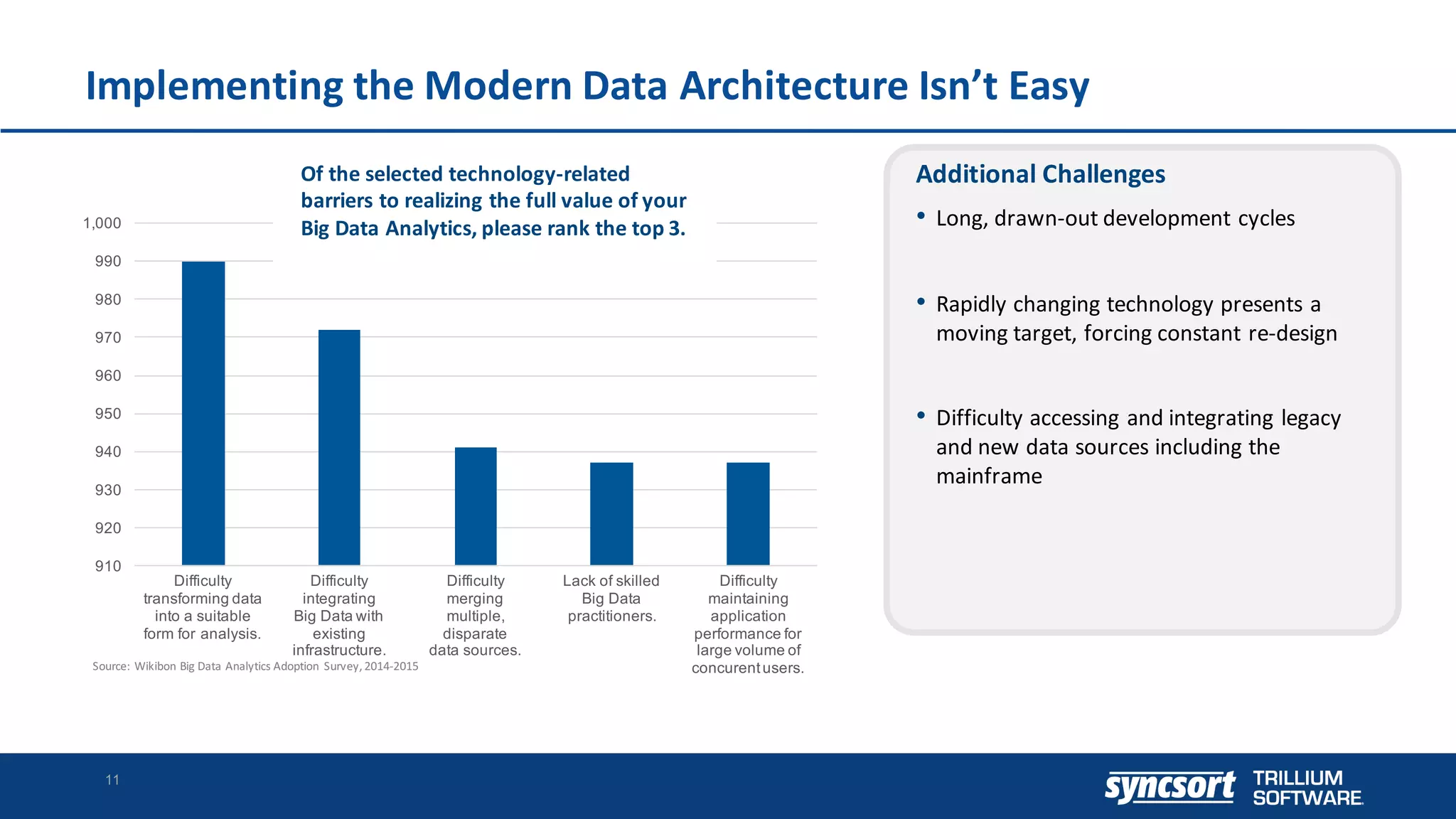
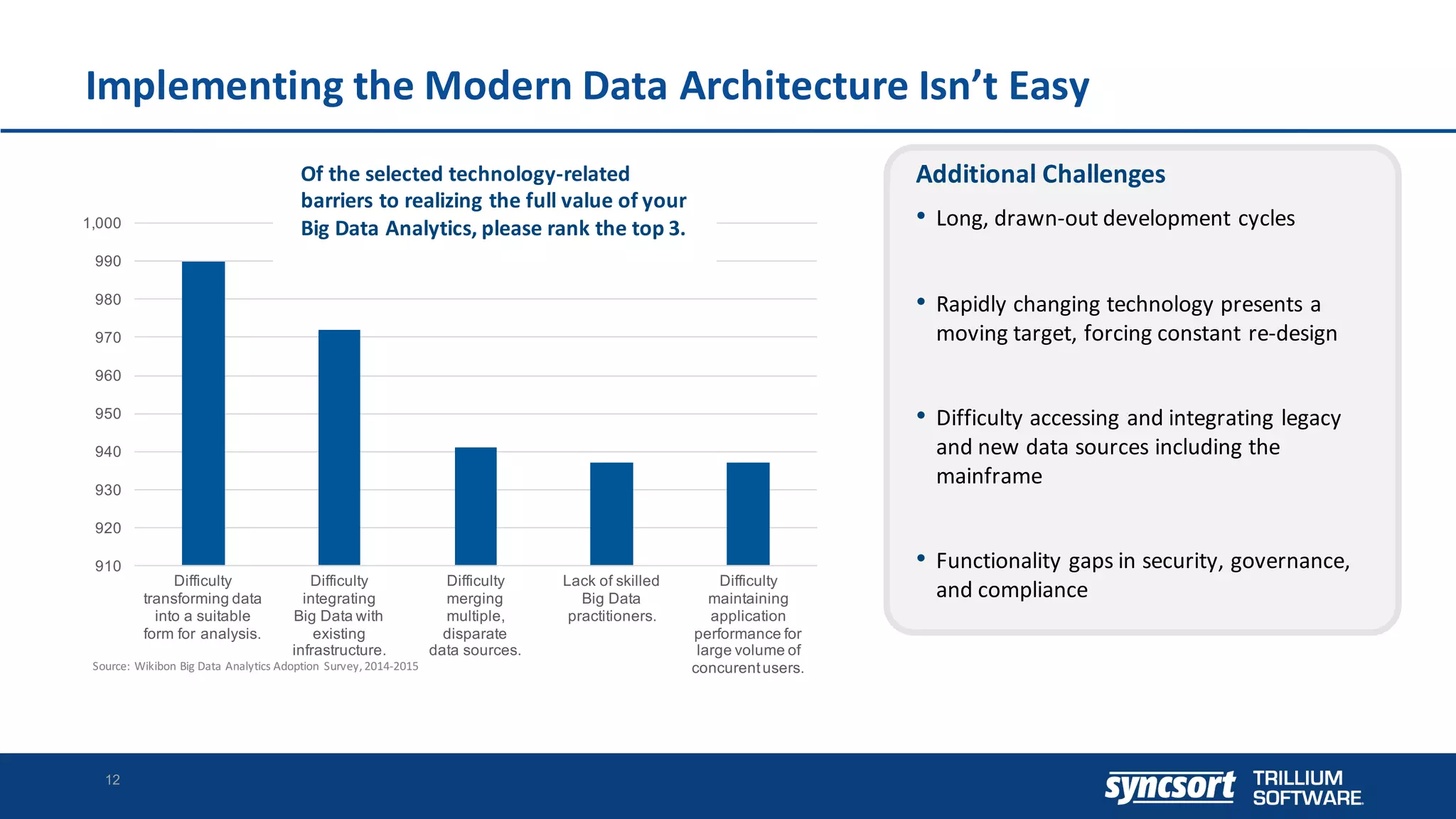

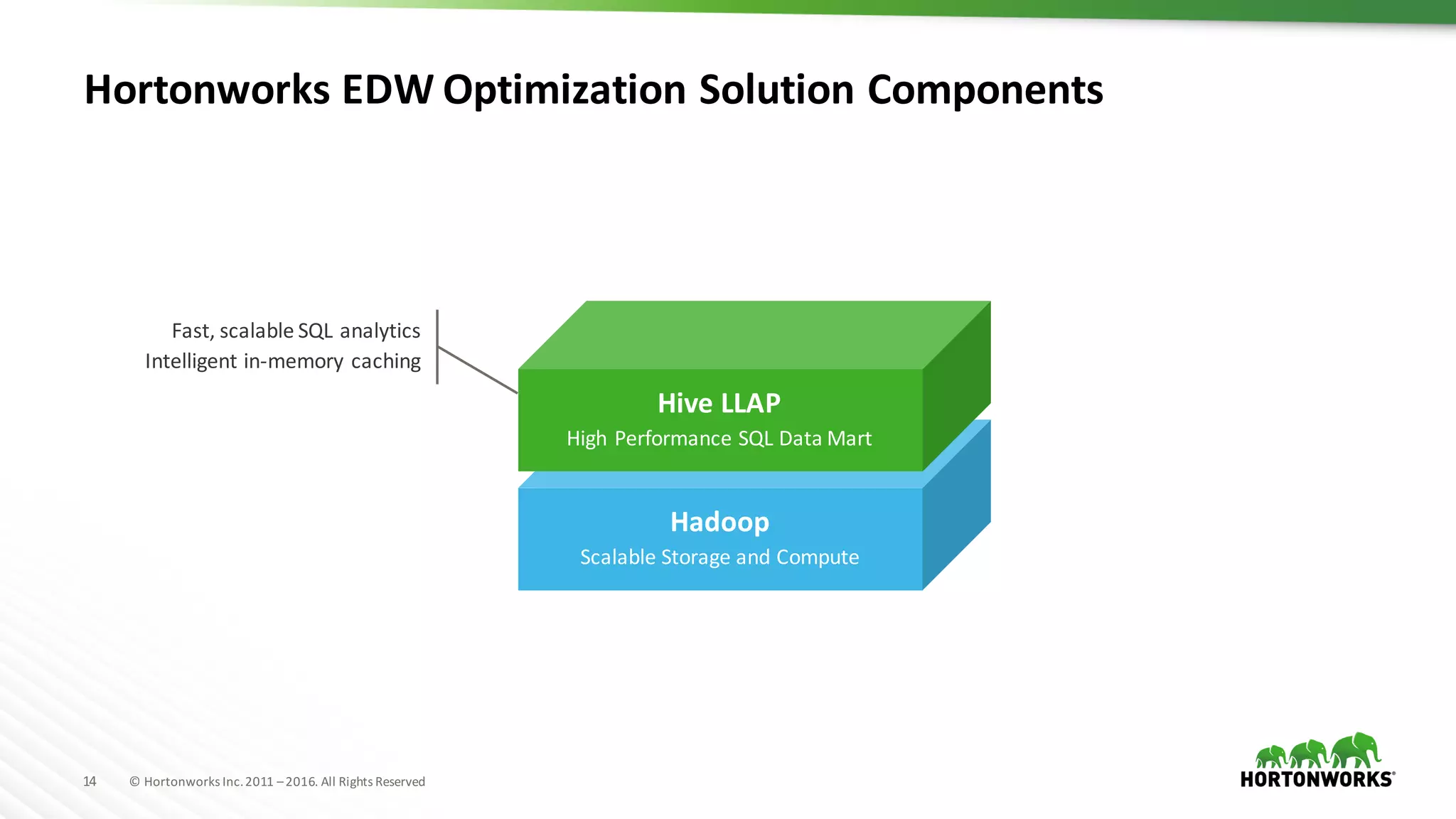
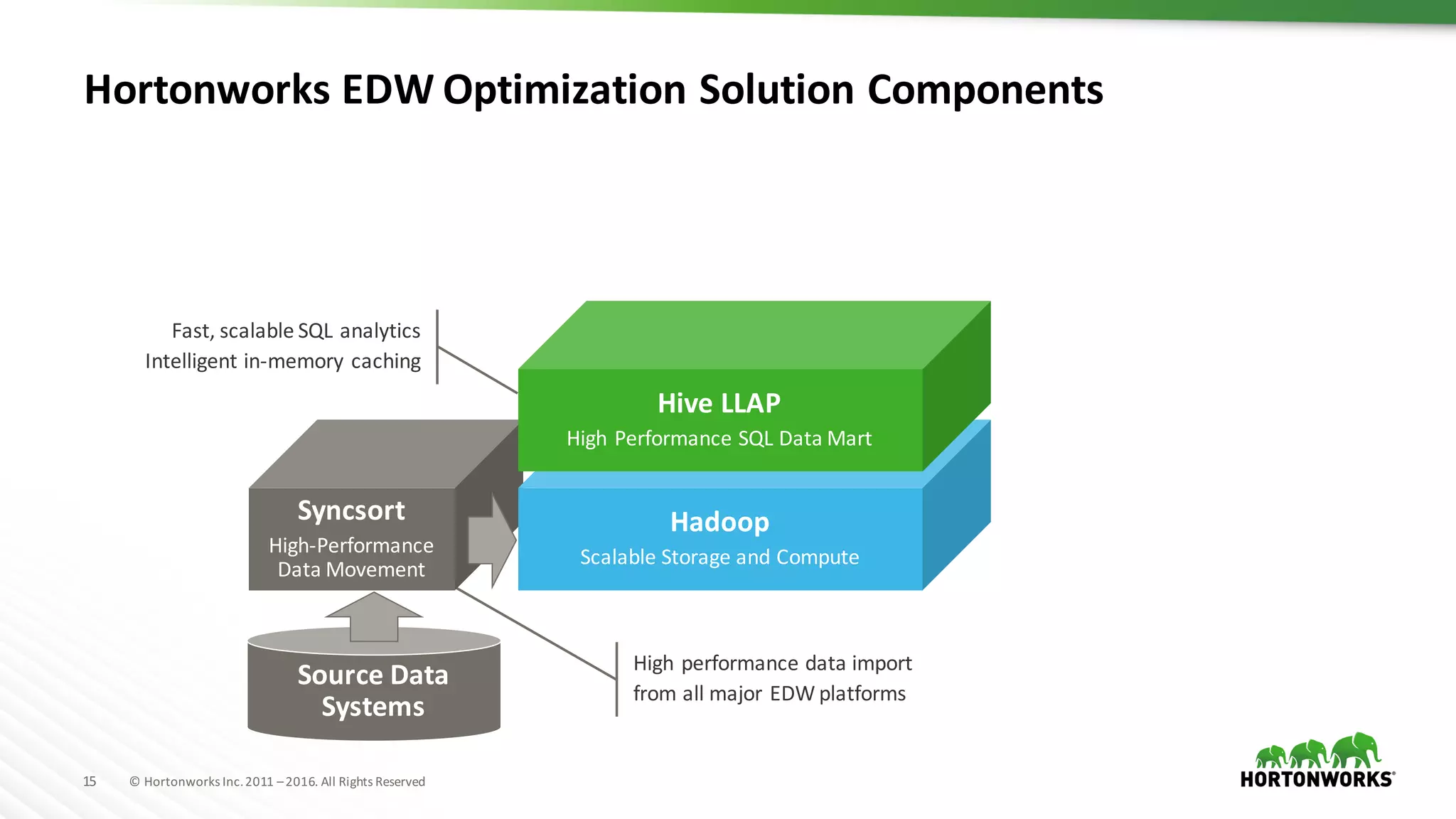
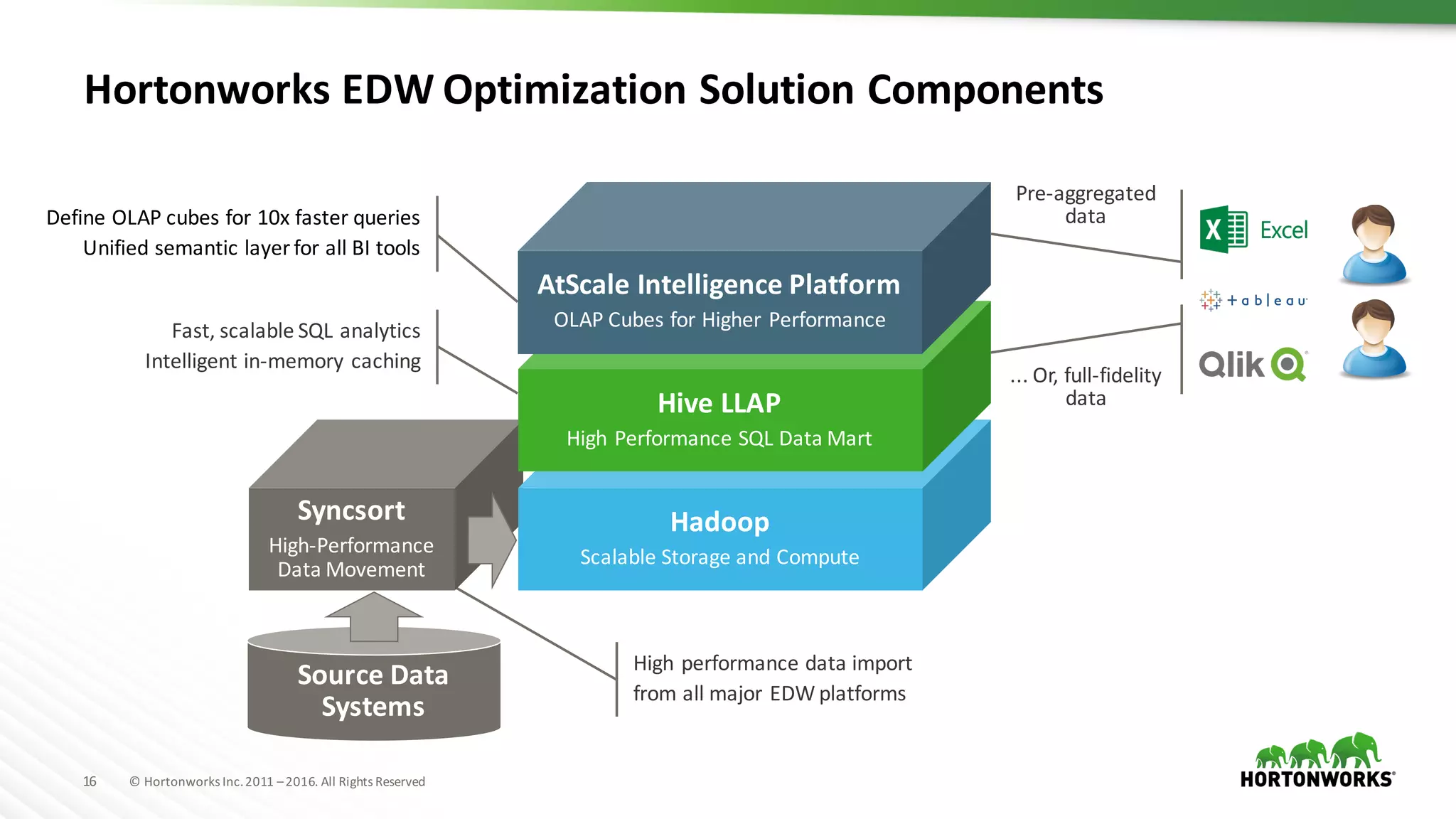





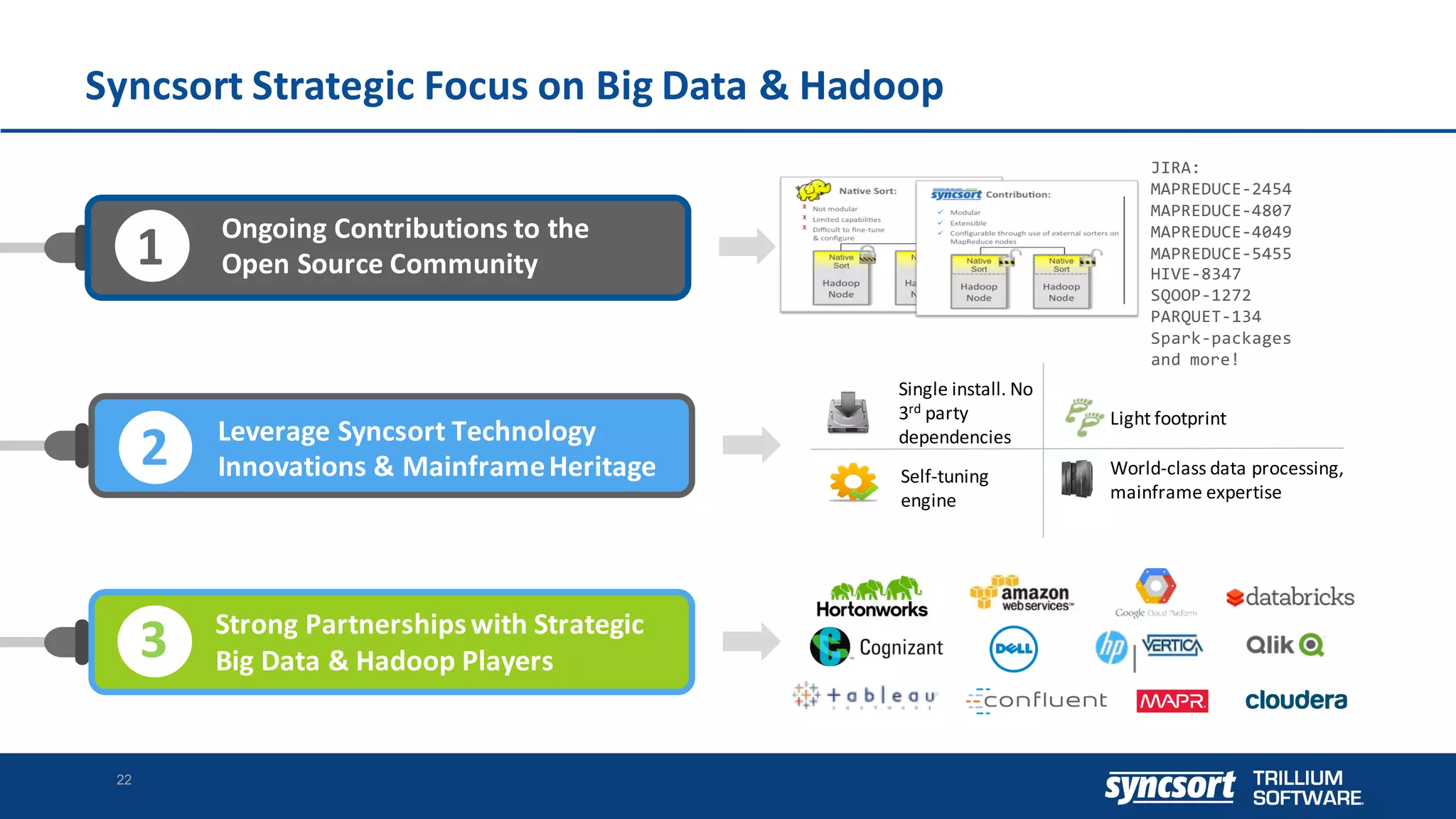
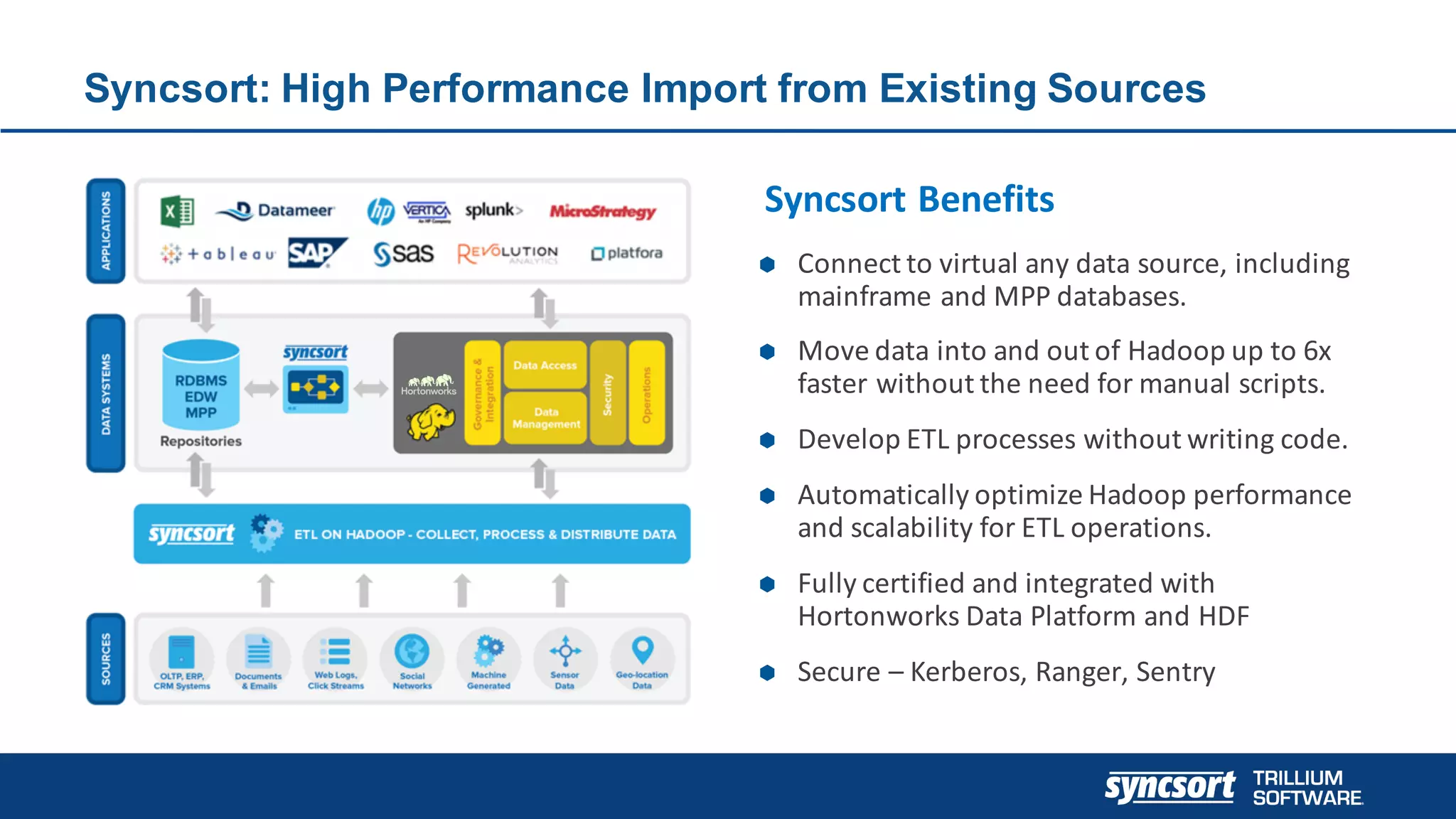
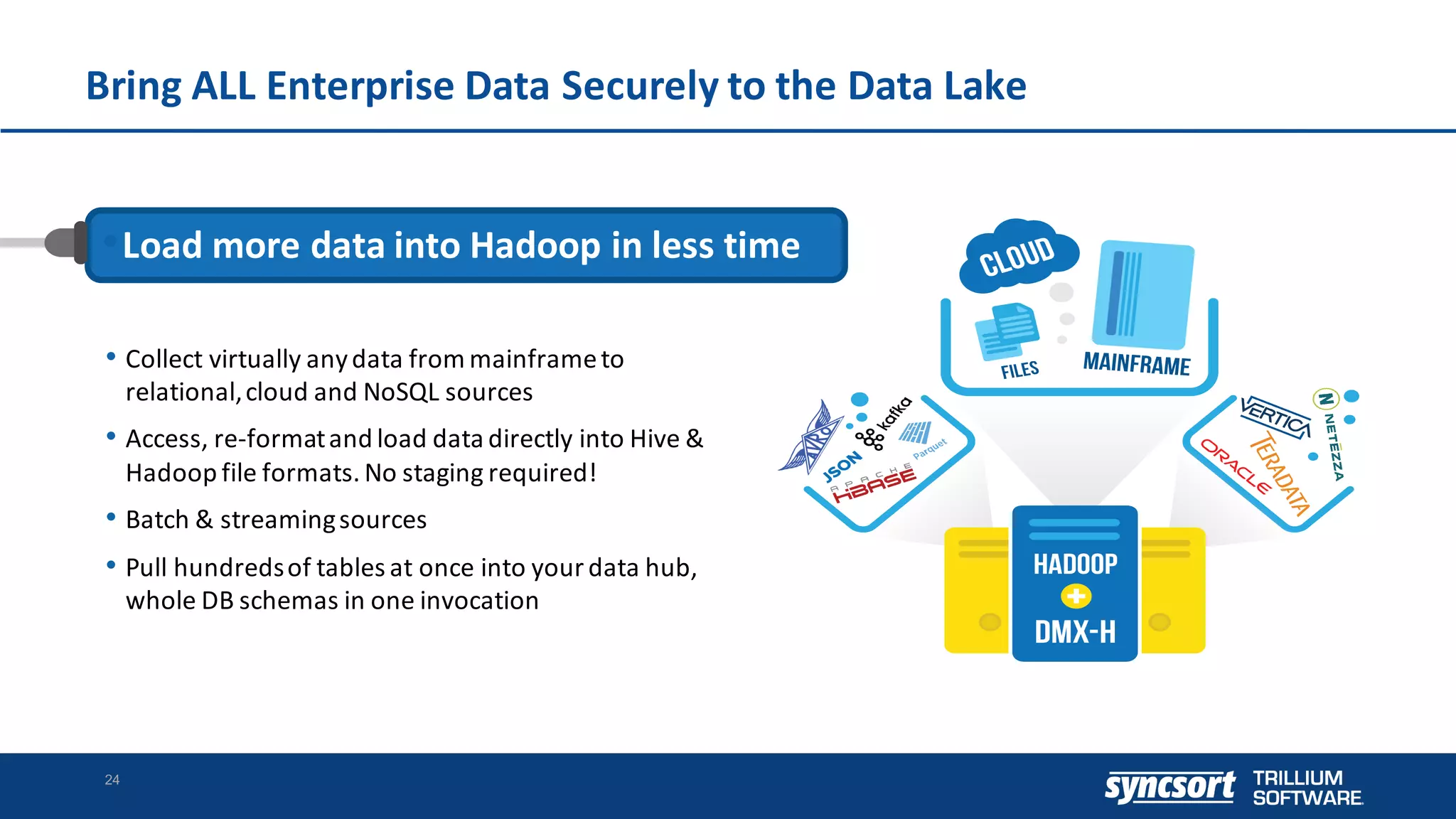
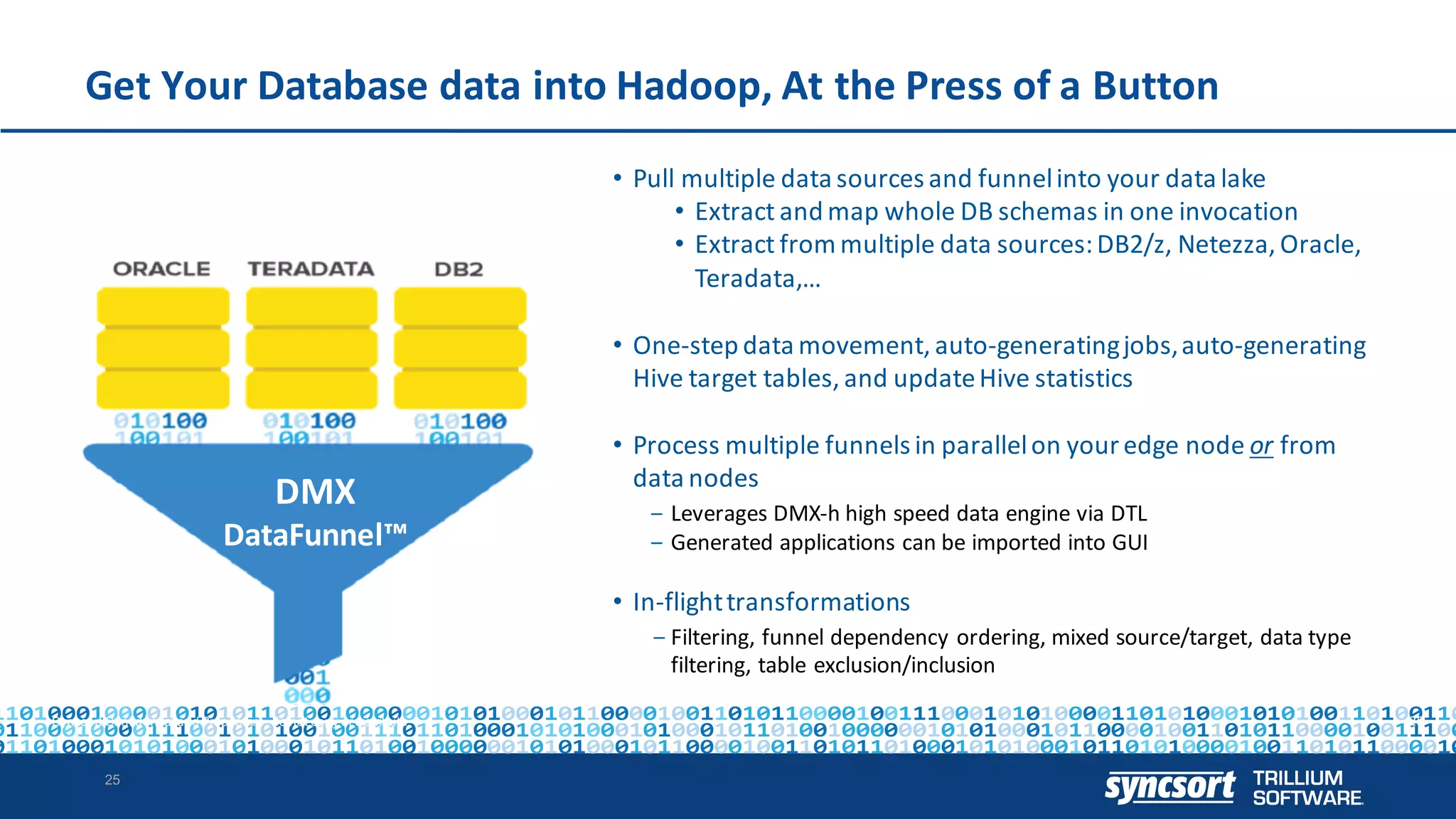






The document discusses the optimization of enterprise data warehouses (EDWs) using Hortonworks' Connected Data Platforms, emphasizing the transformation from traditional EDWs to more agile, real-time analytics with Apache Hadoop. It identifies challenges in current EDW implementations, including high costs, data integration difficulties, and the need for skilled practitioners, while presenting solutions that leverage open-source technology for cost-effective and efficient data processing. Additionally, it highlights case studies showcasing the benefits of using optimized EDW solutions for improved business intelligence and operational efficiency.




































































![[BDD 2025 - Artificial Intelligence] Building AI Systems That Users (and Comp...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingaisystemsthatusersandcompanieslove-251124030845-038f7732-thumbnail.jpg?width=640&height=640&fit=bounds)





![[BDD 2025 - Full-Stack Development] Digital Accessibility: Why Developers nee...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-digitalaccessibilitywhydevelopersneedtoknowandcarein2025-251127011019-0674441d-thumbnail.jpg?width=640&height=640&fit=bounds)



![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)



![[BDD 2025 - Mobile Development] Crafting Immersive UI with E2E and AGSL Shade...](https://cdn.slidesharecdn.com/ss_thumbnails/md-craftingimmersiveuiwithe2eandagslshaderveronicaputrianggraini-251124030840-0c677f44-thumbnail.jpg?width=640&height=640&fit=bounds)




