Downloaded 403 times










































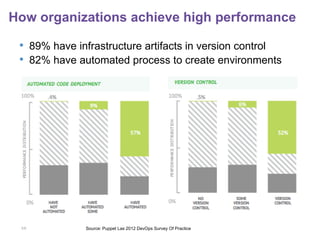
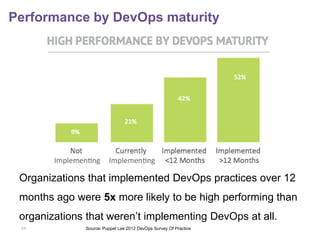


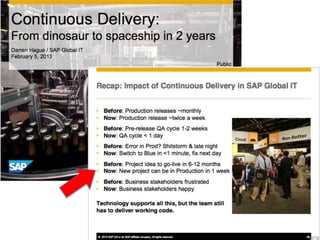












The document discusses how to better sell DevOps practices to organizations. It begins by describing the downward spiral of tensions between IT operations and development teams as applications become more fragile and difficult to deploy. It then provides suggestions for framing the problems organizations face in a way that shows how DevOps practices can help address significant business issues. The document concludes by highlighting examples of organizations successfully implementing DevOps and offers additional resources for learning more.




































































































