Downloaded 156 times





![AWS DATA SPECIAL WEBINAR
© 2022, Amazon Web Services, Inc. or its affiliates.
Field
Document
{
"name": "John Smith",
"age": 42,
"confirmed": true,
"join_date": "2014-06-01",
"home": { "lat": 51.5, "lon": 0.1 },
"accounts": [
{ "type": "facebook", "id": "johnsmith" },
{ "type": "twitter", "id": "johnsmith" }
]
}](https://image.slidesharecdn.com/t2s2-220831174555-5ea24352/85/Amazon-OpenSearch-Deep-dive-6-320.jpg)





































![AWS DATA SPECIAL WEBINAR
© 2022, Amazon Web Services, Inc. or its affiliates.
Node Query Cache 활용
GET logs/_search
{
"query": {
"bool": {
"must": [
(…)
],
"filter": [
{
"range": {
"timestamp": {
"gte": "now-1d/m",
"lte": "now/m"
}
}
(…)](https://image.slidesharecdn.com/t2s2-220831174555-5ea24352/85/Amazon-OpenSearch-Deep-dive-46-320.jpg)



![AWS DATA SPECIAL WEBINAR
© 2022, Amazon Web Services, Inc. or its affiliates.
Term을 이용해서 범위 만들기
PUT index/_doc/1
{
"item": ”banana",
"price_krw": 4980
}
GET index/_search
{
"aggs": {
"price_ranges": {
"range": {
"field": "price_krw",
"ranges": [
{ "to": 10 },
{ "from": 10, "to": 100 },
{ "from": 100, "to": 1000 },
{ "from": 1000, "to": 5000 },
{ "from": 5000, "to": 10000 },
{ "from": 10000 }
]
(…)
GET index/_search
{
"aggs": {
"price_ranges": {
"terms": {
"field": "price_krw_range"
}
(…)
fast
slow
PUT index/_doc/1
{
"item": ”banana",
"price_krw": 4980,
"price_krw_range": "1000-5000"
}](https://image.slidesharecdn.com/t2s2-220831174555-5ea24352/85/Amazon-OpenSearch-Deep-dive-50-320.jpg)


![AWS DATA SPECIAL WEBINAR
© 2022, Amazon Web Services, Inc. or its affiliates.
Index sorting
GET scores/_doc/_search
{
"track_total_hits": false,
"size": 3,
"sort": [
{ "Score": "desc" }
]
}
“Name”: “Player000001”, “Score”:10
“Name”: “Player000002”, “Score”:200
“Name”: “Player000003”, “Score”:50
“Name”: “Player9999999”, “Score”:300
“Name”: “Player9999999”, “Score”:300
“Name”: “Player000002”, “Score”:200
“Name”: “Player000003”, “Score”:50
“Name”: “Player000001”, “Score”:10
・・・
・・・
Skipping](https://image.slidesharecdn.com/t2s2-220831174555-5ea24352/85/Amazon-OpenSearch-Deep-dive-53-320.jpg)















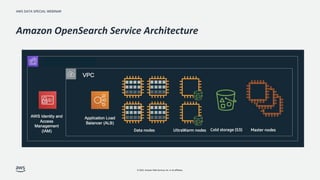
OpenSearch는 배포형 오픈 소스 검색과 분석 제품군으로 실시간 애플리케이션 모니터링, 로그 분석 및 웹 사이트 검색과 같이 다양한 사용 사례에 사용됩니다. OpenSearch는 데이터 탐색을 쉽게 도와주는 통합 시각화 도구 OpenSearch와 함께 뛰어난 확장성을 지닌 시스템을 제공하여 대량 데이터 볼륨에 빠르게 액세스 및 응답합니다. 이 세션에서는 실제 동작 구조에 대한 설명을 바탕으로 최적화를 하기 위한 방법과 운영상에 발생할 수 있는 이슈에 대해서 알아봅니다.













![쿠키런: 킹덤 대규모 인프라 및 서버 운영 사례 공유 [데브시스터즈 - 레벨 200] - 발표자: 용찬호, R&D 엔지니어, 데브시스터즈 ...](https://cdn.slidesharecdn.com/ss_thumbnails/t3s3-221108102039-c0f48289-thumbnail.jpg?width=640&height=640&fit=bounds)













![[Spring Camp 2018] 11번가 Spring Cloud 기반 MSA로의 전환 : 지난 1년간의 이야기](https://cdn.slidesharecdn.com/ss_thumbnails/201804springcamp11stmsafinalpubslideshare-180527051608-thumbnail.jpg?width=640&height=640&fit=bounds)


![[Keynote] 슬기로운 AWS 데이터베이스 선택하기 - 발표자: 강민석, Korea Database SA Manager, WWSO, A...](https://cdn.slidesharecdn.com/ss_thumbnails/d3s01aws-230704014400-3eeae447-thumbnail.jpg?width=640&height=640&fit=bounds)












![[AWS Builders] AWS 스토리지 서비스 소개 및 사용 방법](https://cdn.slidesharecdn.com/ss_thumbnails/awsbuilders200storageservice-190611112205-thumbnail.jpg?width=640&height=640&fit=bounds)


![[Games on AWS 2019] AWS 입문자를 위한 초단기 레벨업 트랙 | AWS 레벨업 하기! : 스토리지 - 현륜식 AWS 솔루션...](https://cdn.slidesharecdn.com/ss_thumbnails/03gamesonawsawsstorage-191014081535-thumbnail.jpg?width=640&height=640&fit=bounds)









![[D3T1S05] Aurora 혼합 구성 아키텍처를 사용하여 예상치 못한 트래픽 급증 대응하기](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s05aurora-240702042911-c7f3f22d-thumbnail.jpg?width=640&height=640&fit=bounds)


![[D3T1S01] Gen AI를 위한 Amazon Aurora 활용 사례 방법](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s01genaiamazonaurora-240702042912-516e67f4-thumbnail.jpg?width=640&height=640&fit=bounds)

![[D3T2S01] Amazon Aurora MySQL 메이저 버전 업그레이드 및 Amazon B/G Deployments 실습](https://cdn.slidesharecdn.com/ss_thumbnails/d3t2s01amazonaurorabluegreendeployment-240702042226-3ae36566-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S07] AWS S3 - 클라우드 환경에서 데이터베이스 보호하기](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s07-240702042911-cb134cd6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S04] Aurora PostgreSQL performance monitoring and troubleshooting by use...](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s04aurorapostgresqlperformancemonitoringandtroubleshooting-240702042912-5df626e3-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S06] Neptune Analytics with Vector Similarity Search](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s06neptuneanalyticsvectorsilimliaritysearch-240702042912-94c41309-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T2S03] Data&AI Roadshow 2024 - Amazon DocumentDB 실습](https://cdn.slidesharecdn.com/ss_thumbnails/d3t2s03documentdbhandson-240702042224-047bbc2c-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S03] Amazon DynamoDB design puzzlers](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s03amazondynamodbdesignpuzzlers-240702042912-ad6df881-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S02] Aurora Limitless Database Introduction](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s02auroralimitlessdatabaseintroduction-240702042911-cb5552b7-thumbnail.jpg?width=640&height=640&fit=bounds)