Download as PDF, PPTX
















![© SQLintersection. All rights reserved.
http://www.SQLintersection.com
Backup Tuning Options
▪ Experiment with BUFFERCOUNT, BLOCKSIZE, and MAXTRANSFERSIZE
▪ If using backup compression with TDE (SQL Server 2016 or newer)
Make sure to set MAXTRANSFERSIZE greater than 64K
-- Striped backup to two files on two different drives
-- with backup compression, using parameter options
BACKUP DATABASE [BigDatabaseTest]
TO DISK = N'R:SQL2017BackupsBigDatabaseTestCompressedA1.bak',
DISK = N'S:SQL2017BackupsBigDatabaseTestCompressedB1.bak'
WITH NOFORMAT, INIT, NAME = N’BigDatabaseTest-Full Database Backup', SKIP,
NOREWIND, NOUNLOAD, COMPRESSION, STATS = 1,
BUFFERCOUNT = 2200, BLOCKSIZE = 65536, MAXTRANSFERSIZE = 2097152;](https://image.slidesharecdn.com/highavailability-disasterrecovery101-190326150926/75/High-availability-disaster-recovery-101-17-2048.jpg)















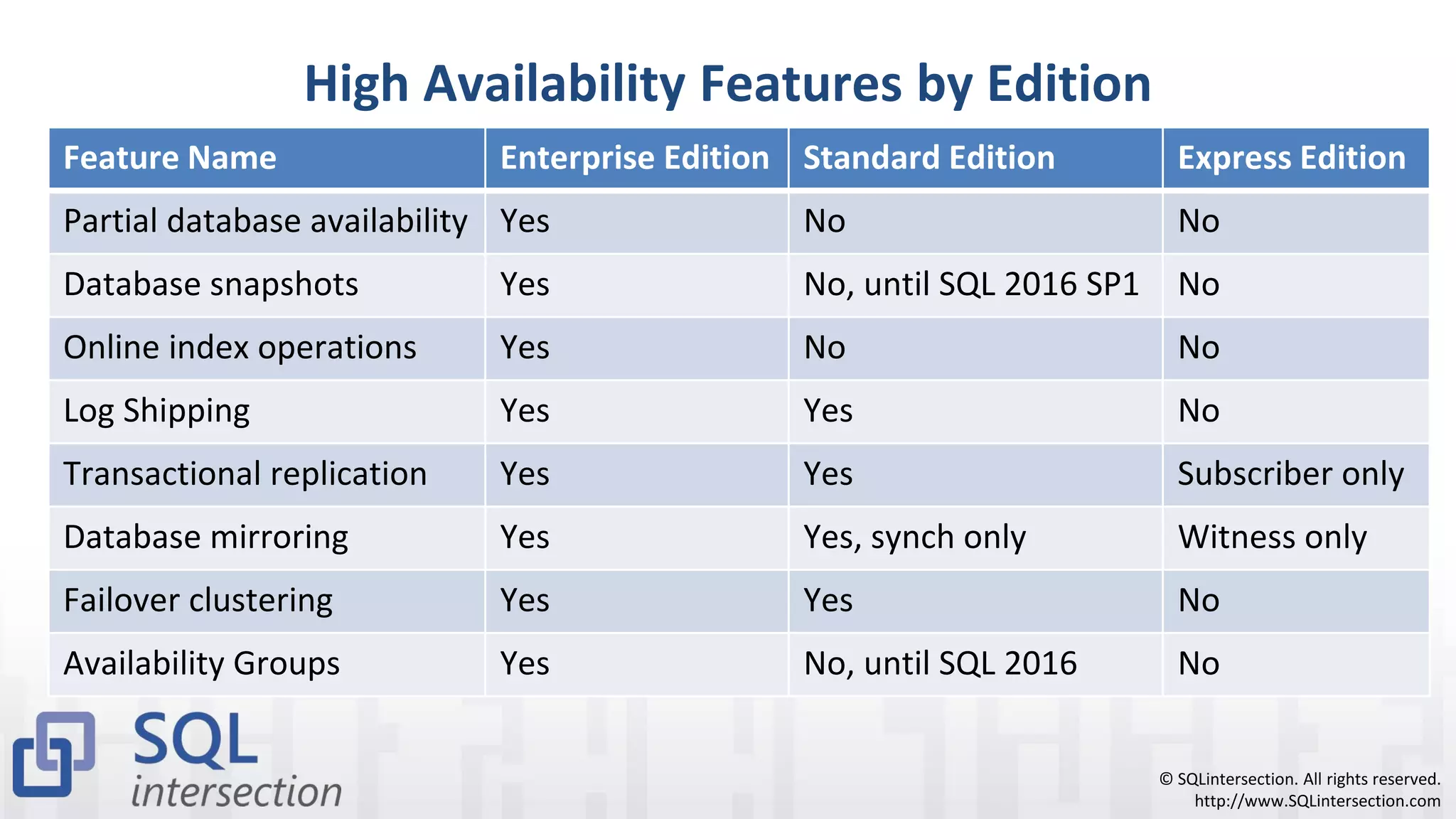










The document discusses high availability and disaster recovery strategies for SQL Server databases. It defines high availability and outlines some common causes of planned and unplanned downtime. It then describes several high availability technologies in SQL Server 2017 like Always On Availability Groups, database mirroring, log shipping, and backup/restore methods. It emphasizes having a backup and restore testing plan as well as using component redundancy to avoid single points of failure and reduce unplanned downtimes.



































































