Download to read offline












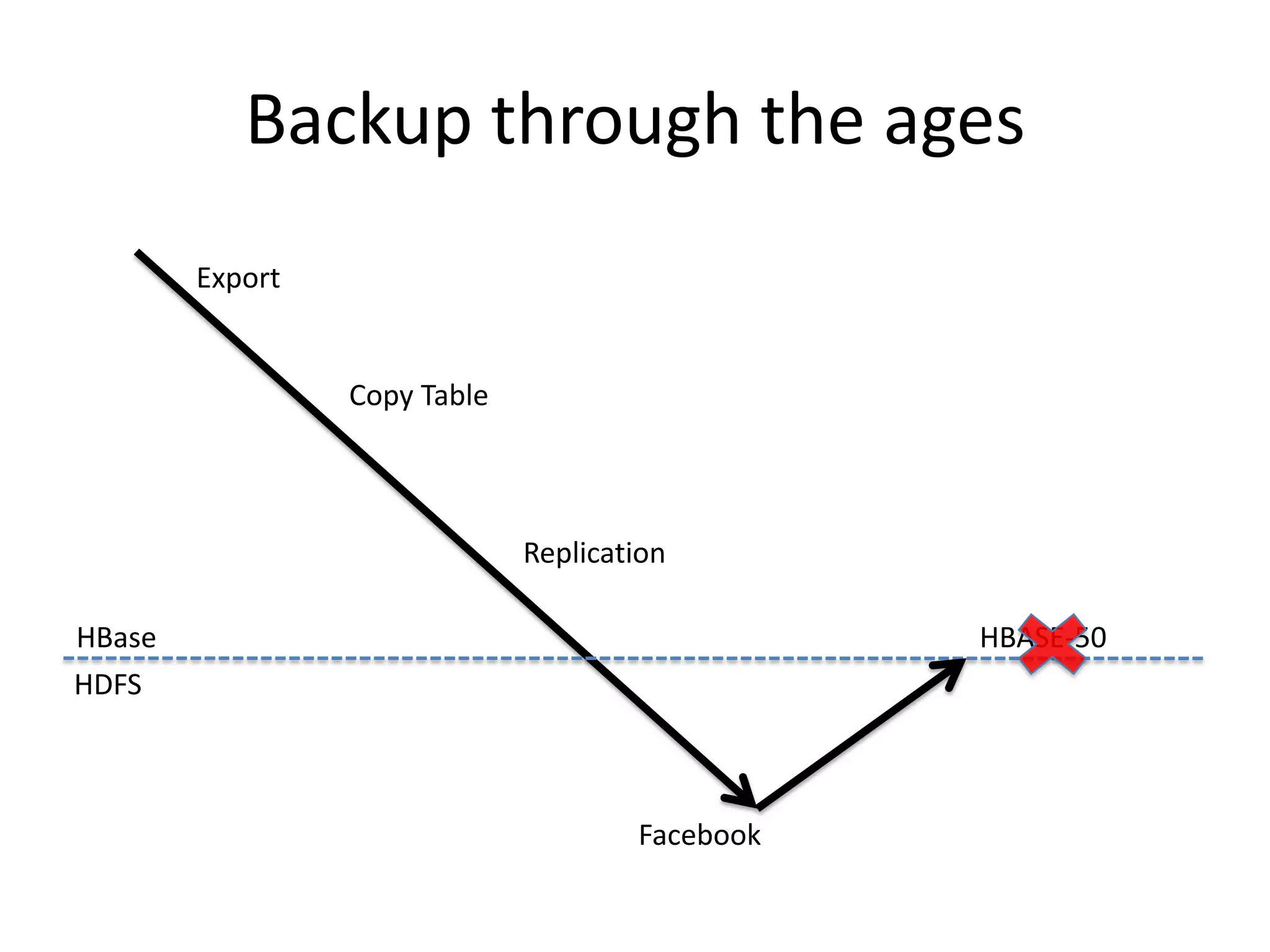


















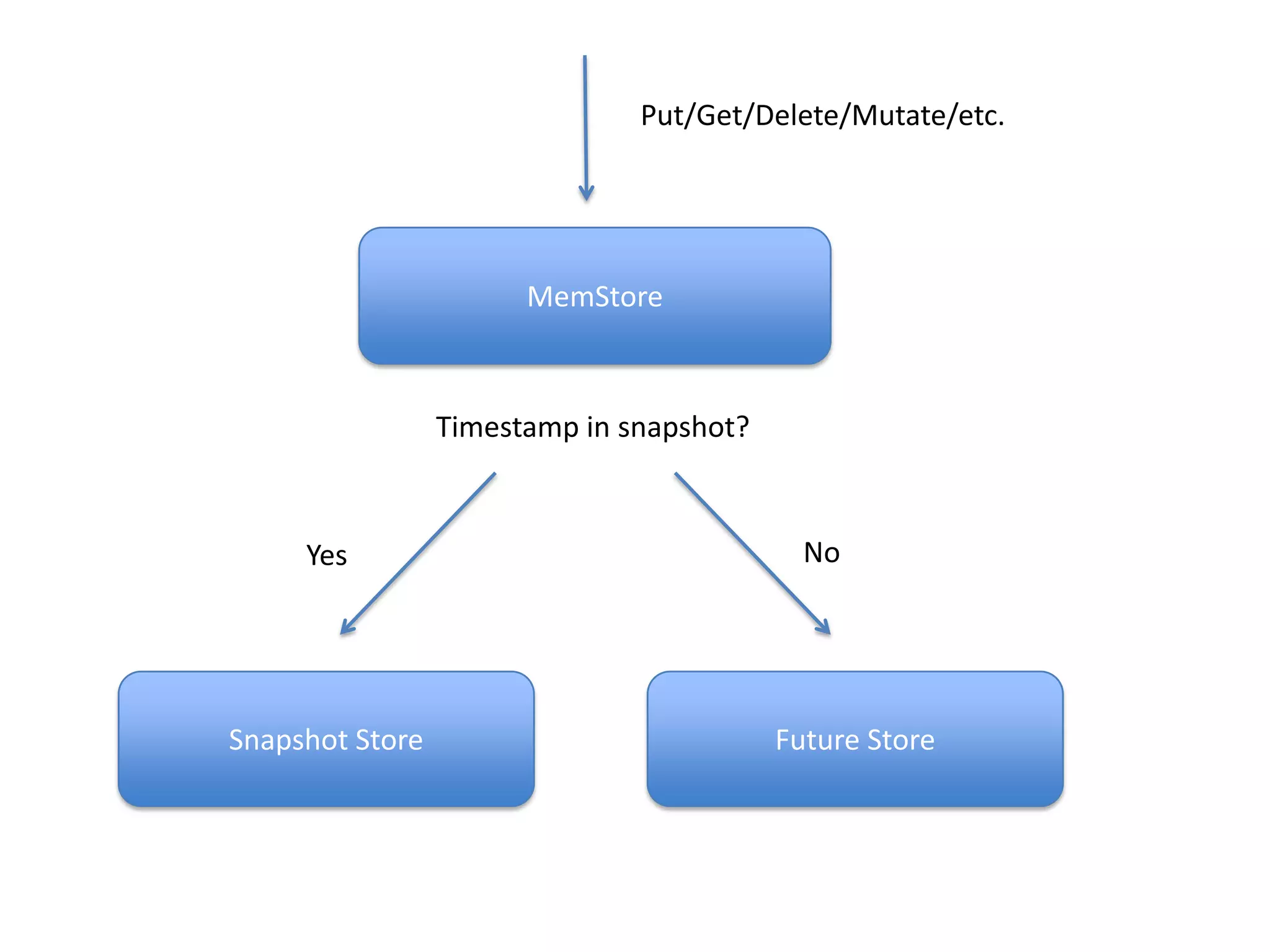

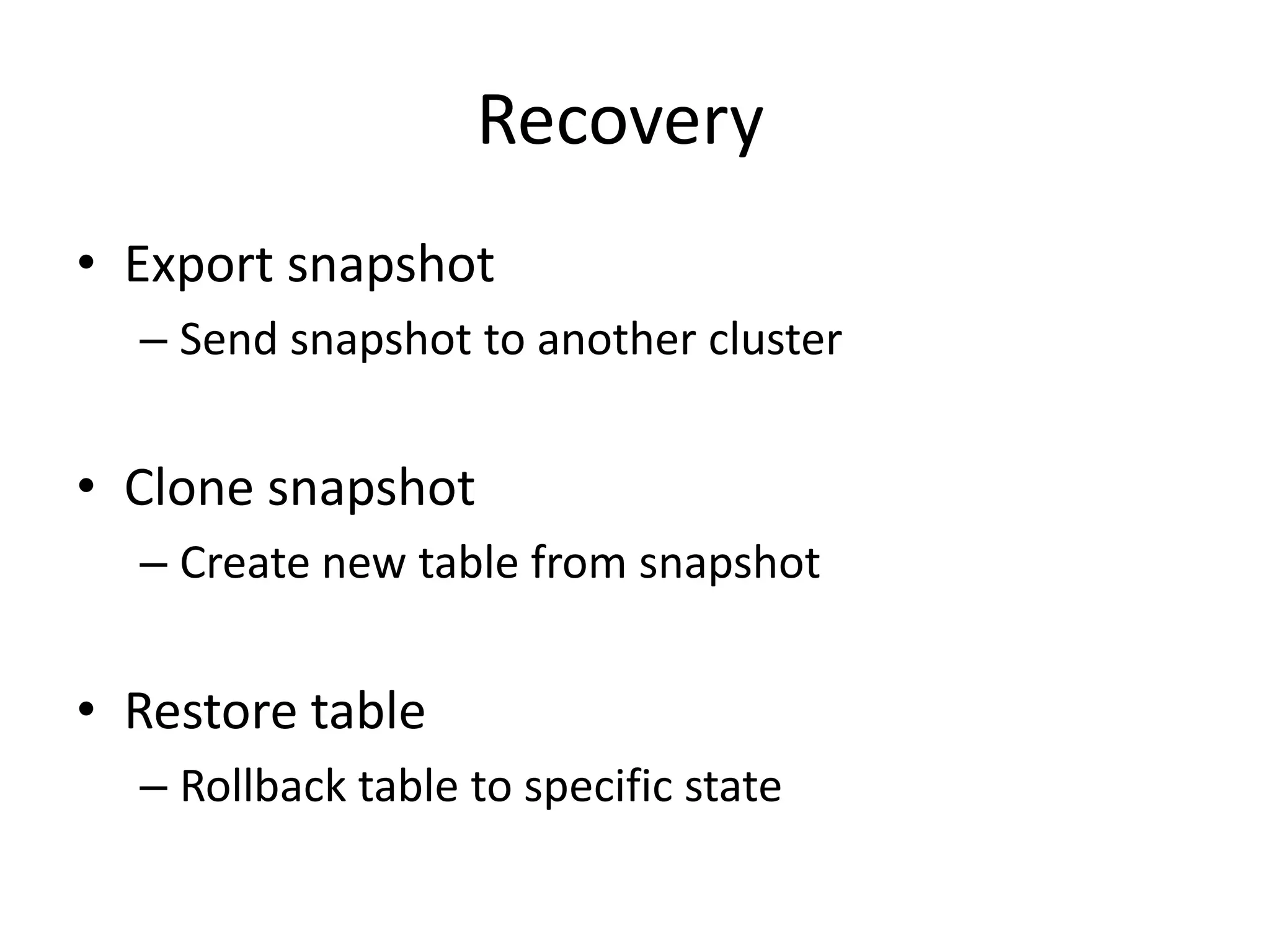









HBase now includes a built-in snapshot feature that allows users to take point-in-time backups of tables with minimal impact on the running cluster. Snapshots can be taken in an offline, globally consistent, or timestamp consistent manner. The snapshots can then be exported to another cluster, used to clone a new table, or restore an existing table to a prior state captured by the snapshot. The snapshot functionality provides a simple, distributed, and high performance solution for backup and recovery of large HBase datasets.





















































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)














