Downloaded 38 times























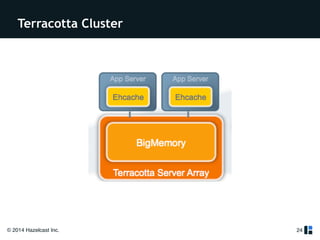
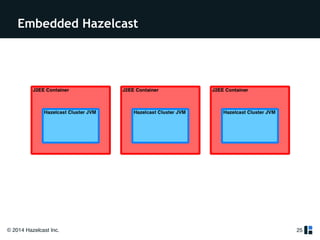
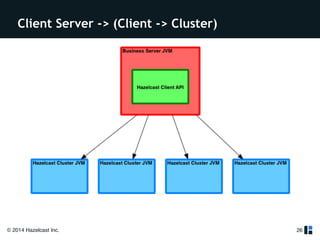












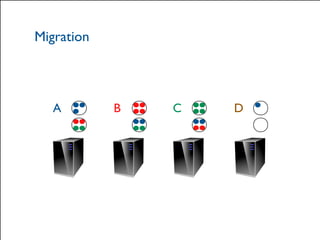
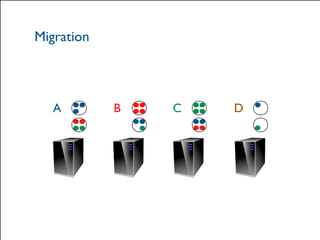
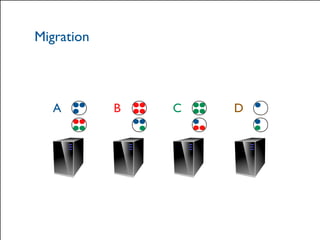
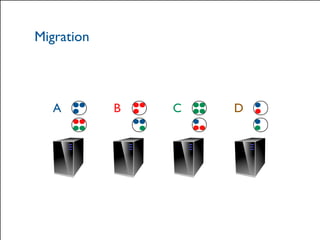
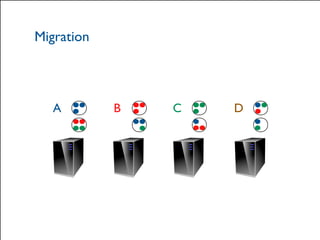
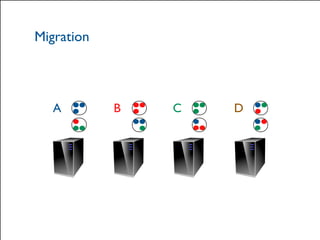
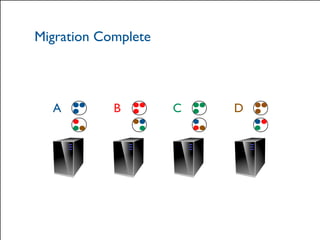






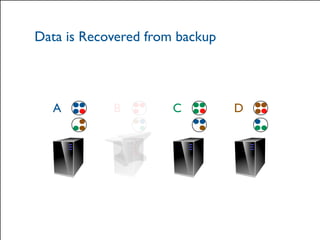
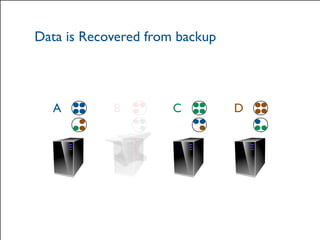















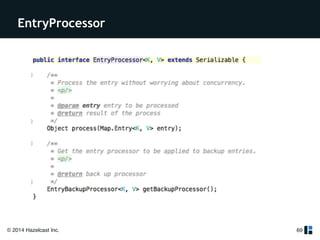








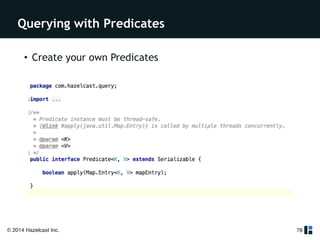






The document provides a comprehensive overview of Hazelcast for users transitioning from Terracotta, highlighting the limitations of Terracotta and how Hazelcast addresses them through features like in-memory distributed data processing and flexible deployment options. It discusses migration strategies, cluster configuration, and the use of distributed collections while emphasizing Hazelcast's scalability, fault tolerance, and ease of use. The conclusion underscores its advantages such as zero downtime and no single point of failure, making it a robust alternative for users seeking enhanced performance and functionality.








































































































