Downloaded 30 times
![In Memory Data Grids Alexey Kharlamov [email_address] Skype: aharlamov](https://image.slidesharecdn.com/highload2009-imdgpresentation-091024122117-phpapp02/85/HighLoad-2009-In-Memory-Data-Grids-1-320.jpg)


















![Спасибо Alexey Kharlamov [email_address] Skype: aharlamov](https://image.slidesharecdn.com/highload2009-imdgpresentation-091024122117-phpapp02/85/HighLoad-2009-In-Memory-Data-Grids-25-320.jpg)

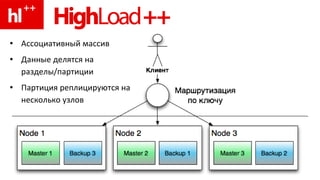
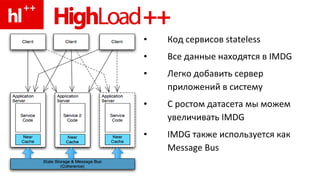
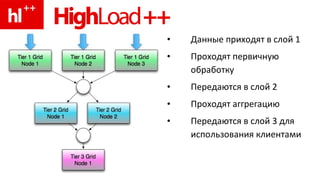
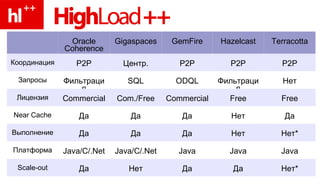
Документ обсуждает концепцию in-memory data grids (IMDG) и их применение в обработке больших объемов данных с высокой производительностью. Подчеркивается важность масштабирования и параллельной обработки, а также необходимость оптимизации доступа к данным с использованием кеширования и денормализации. Рассматриваются транзакции и их управление в распределенных системах, с примерами практических операций, таких как перевод денег.



























































