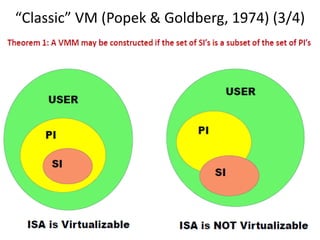
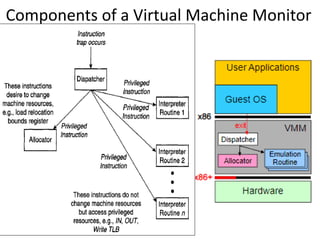
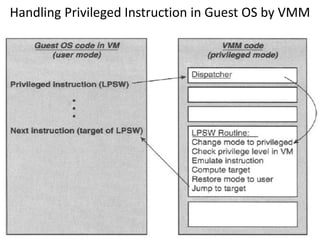
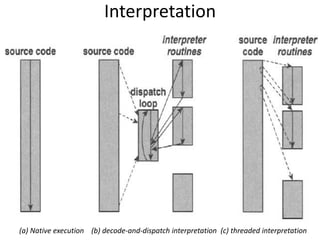
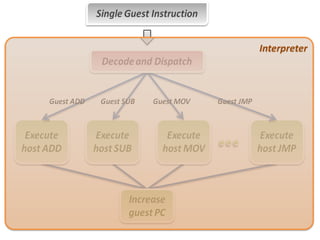
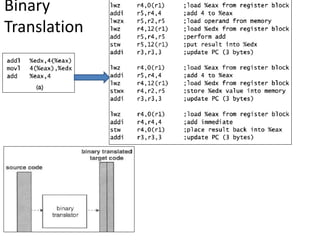
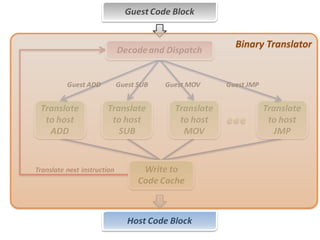
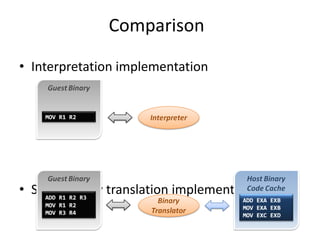
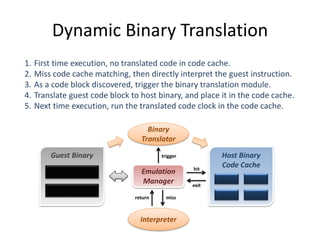
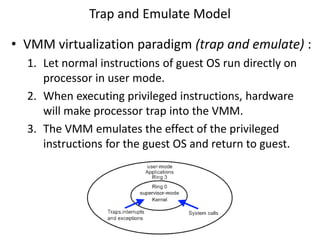
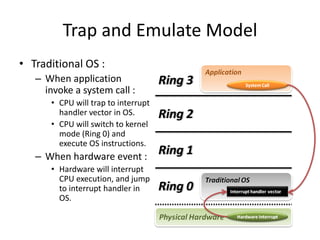
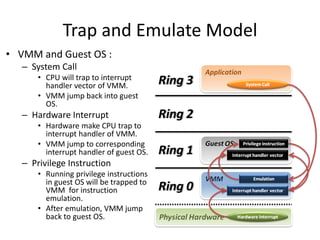
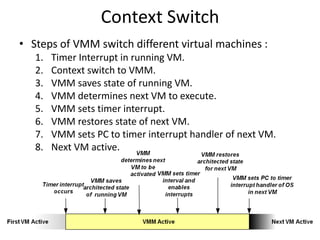
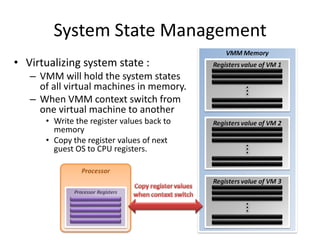
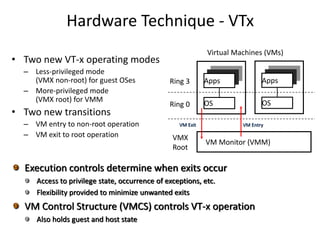
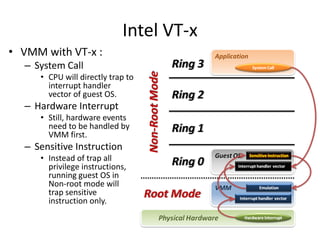
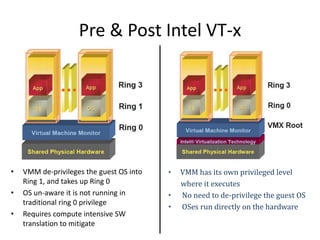
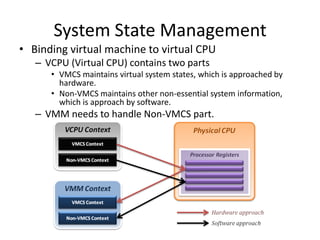
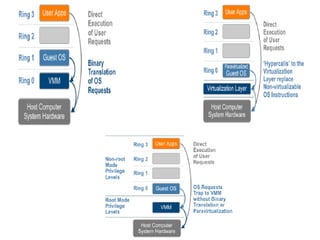
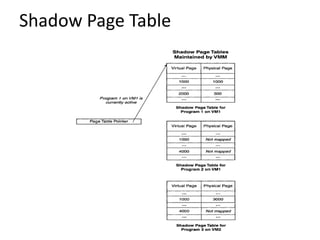
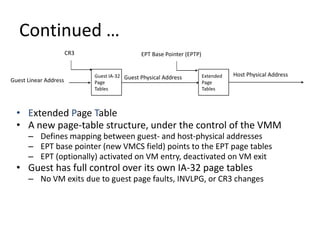
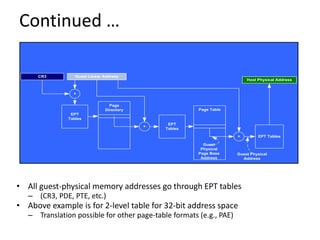
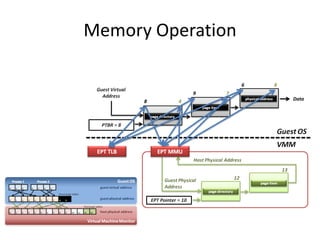
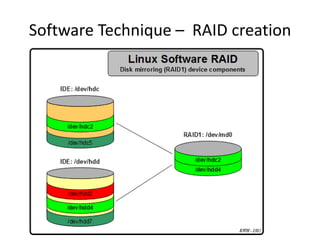
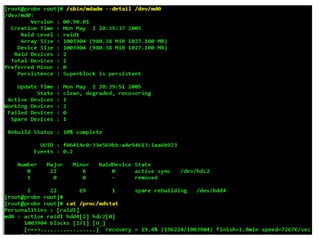
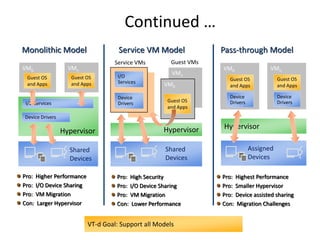
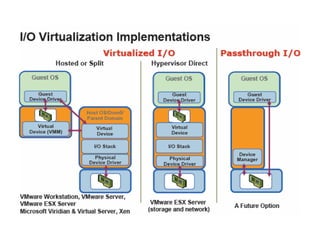
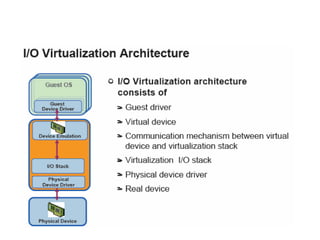
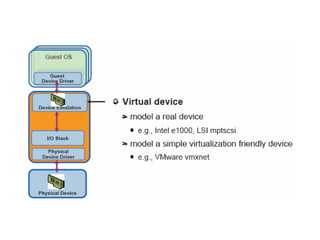
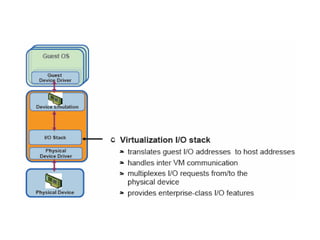
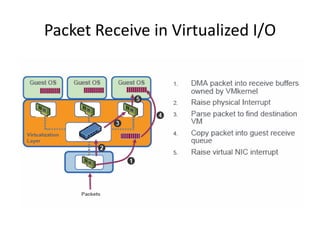
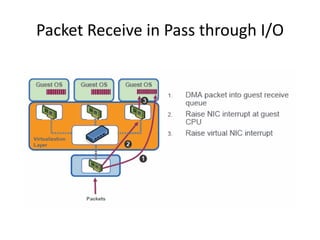
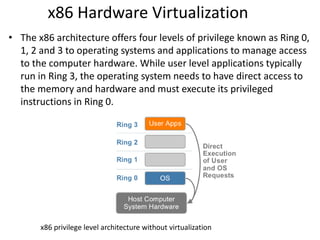
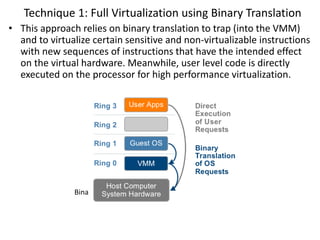
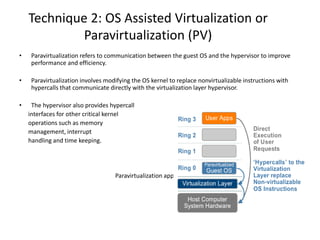
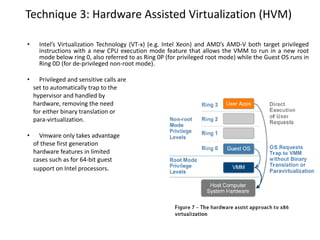
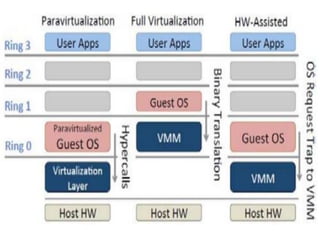
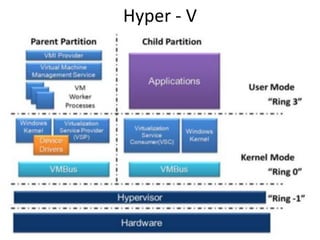
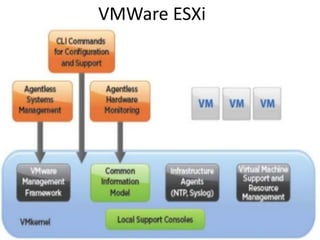
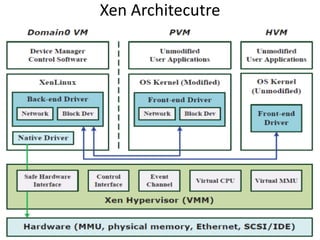
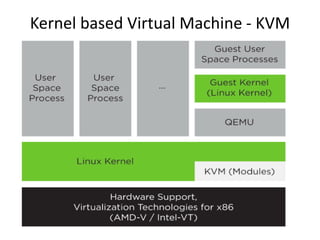
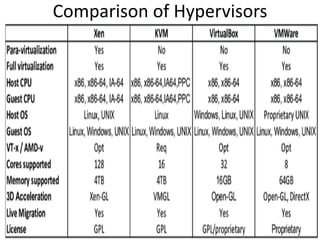
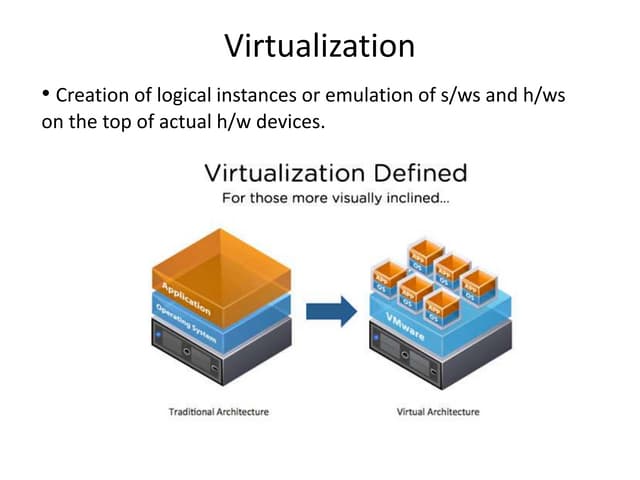
The document describes hypervisors and their role in virtualization. It discusses how a hypervisor sits between virtual machines and hardware to provide an isolated environment for each VM. It also compares different types of hypervisors, including describing how early hypervisors used full virtualization through trap-and-emulate to virtualize privileged instructions. The document then discusses the design conditions for a hypervisor based on Popek and Goldberg's virtualization theorem, including how the hypervisor must provide equivalence, performance, and resource control for virtual machines.