Download to read offline



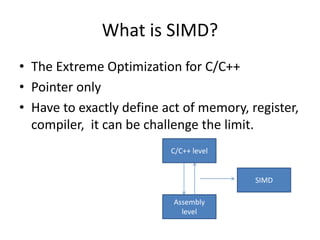
![C=A+B ?
float arr0[4] = { 1,2,3,4 };
float arr1[4] = { 5,6,7,8 };
float arr2[4] = { 0 };
A
B
C
A B
C +
=
Result: arr2[4] => { 6,8,10,12 };](https://image.slidesharecdn.com/happytousesimd-210928111705/85/Happy-To-Use-SIMD-4-320.jpg)
![Why is SIMD fast?
for(int i=0;i<4;i++)
arr2[i]=arr0[i]+arr1[i];
for(int i=0;i<4;i++)
*(arr2 + i) = *(arr0 + i)+*(arr1 + i);
1 1*4
(1+1)*4 (1+1)*4 (1+1)*4
37 cycles
1*4
1*4
Assume
the all
instruction sets
have
1 instruction and
1 cycle](https://image.slidesharecdn.com/happytousesimd-210928111705/85/Happy-To-Use-SIMD-5-320.jpg)
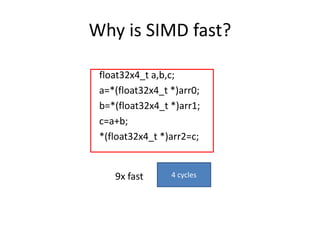


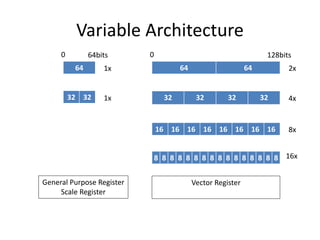


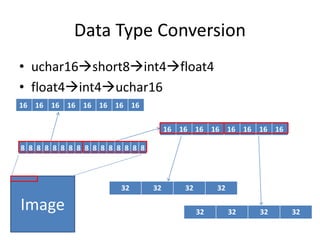
![Re-Definition Register
union reg128 {
uchar16 _uchar16;
short8 _short8;
int4 _int4;
float4 _float4;
double2 _double2;
uchar _uchar[16];
short _short[8];
int _int4;
float _float[4];
double _double[2];
…
void print_uchar()
{
printf(“%d %d..n”,
_uchar[0],_uchar[1],_uchar[2]….);
}
void print_float()
{
printf(“%f %f %f %fn”,
_float[0],_float[1]...);
}
…
};](https://image.slidesharecdn.com/happytousesimd-210928111705/85/Happy-To-Use-SIMD-12-320.jpg)
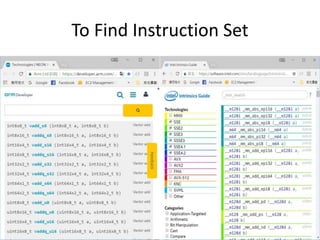







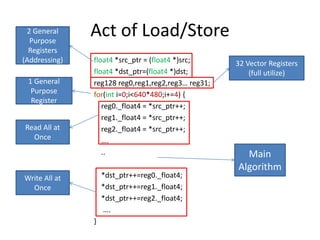
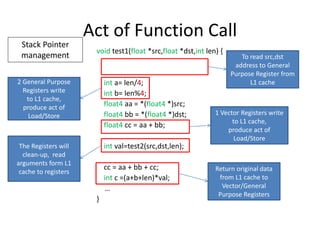
![Known Methodology
int arr0[100] = {1,2,3…};
void test1 (float *src,float *dst,int len)
{
int arr1[100] = {1,2,3…};
int b =4;
int *arr2 = (int *)malloc(100*sizeof(int));
int c = len + b;
…
}
Memory
(DDR3)
L1 cache
Instruction set
Const
Memory
(DDR3)](https://image.slidesharecdn.com/happytousesimd-210928111705/85/Happy-To-Use-SIMD-22-320.jpg)
![Known Methodology
class a
{
int val = 3;
int map[100] = {1,2,3,4,5};
a();
…
};
Memory
(DDR3)
Same as struct](https://image.slidesharecdn.com/happytousesimd-210928111705/85/Happy-To-Use-SIMD-23-320.jpg)


![Few To Use Array,
More To Use Pointer++
void test1(float *src,float *dst,int len)
{
float4 *src_ptr =(float4 *)src;
float4 *dst_ptr=(float4 *)dst;
float4 reg0,reg1…;
for(int i=0;i<len;i+=4)
{
reg0=*src_ptr++;
reg1=*src_ptr++;
reg0 = reg0+reg1;
…..
*dst_ptr++=reg0;
*dst_ptr++=reg1;
}
}
• Not recommend to use
void test2(float4 *src,float4 *dst,int len)
{
int len_4 = len/4;
float4 reg0,reg1…;
for(int i=0;i<len_4;i+=2)
{
reg0=src[i]+src[i+1];
…
dst[i]=reg0;
dst[i+1]=src[i+1];
}
}](https://image.slidesharecdn.com/happytousesimd-210928111705/85/Happy-To-Use-SIMD-26-320.jpg)


![• Choice inner-instruction (Unalign Load/Store)
• Access aligning data, use alignr or vext
assembly
• Declare 16 bits alignment or malloc and shift
address
Solve Method
32 32 32 32 32 32 32 32
reg0
reg3=vext(reg0,reg1,1)
reg1
float __attribute__ ((aligned (16))) a[40];
float *b=(float *)malloc(sizeof(float)*40);
b= (float*)(((unsigned long)b + 15) & (~0x0F))](https://image.slidesharecdn.com/happytousesimd-210928111705/85/Happy-To-Use-SIMD-29-320.jpg)


![Why
float arr[4*32+4] = {…};
float4 *arr_ptr = (float4 *)arr;
float4 a0,a1,a2,a3,a4,a5,a6 … a32;
A0 = *arr_ptr++;
A1= *arr_ptr++;
…
A32 = *arr_ptr++;
Over 32 register variables at same
time, it makes extra Load/Store in
operation process, can’t be
optimized.](https://image.slidesharecdn.com/happytousesimd-210928111705/85/Happy-To-Use-SIMD-33-320.jpg)



![Act of Branch Instruction
float a[100],b[100];
for(int i=0;i<100;i++)
{
if(a[i]<50)
b[i]=a[i];
else
b[i] = 30;
}
1 100 100
(1+1+1)*100
(1+1)*100*2
(1+1)*100
1101 cycles](https://image.slidesharecdn.com/happytousesimd-210928111705/85/Happy-To-Use-SIMD-39-320.jpg)

![Analyse SIMD Branch
float4 cmp = {50,50,50,50};
reg128 val0;
reg128 reg0,mask,tmp0,tmp1;
val0._float4 = { 30,30,30,30 };
for(int i=0;i<100;i+=4)
{
reg0._float4 = *a_ptr++;
mask._uint4=vcltq_f32(reg0._float4,cmp);
tmp0._uint4=vandq_u32(reg0._uint4,mask._uint4);
mask.uint4 = vnotq_u32(mask);
tmp1._uint4=vandq_u32(val0._uint4,mask._uint4);
reg0._uint4=vxor_u32(temp0._uint4,temp1._uint4);
*b_ptr++ = reg0._uint4;
}
if(a[i]<50) b[i]=a[i];
else b[i] =30;
11..1 00..0 11..1 00..0
If true
32’s one
If false
32’s zero
0 128
0000 1111
0011 0100
0000 0100
AND
1111 0000
1011 0001
101 1 0000
NOT
AND
1011 0000
0000 0100
101 1 0100
XOR](https://image.slidesharecdn.com/happytousesimd-210928111705/85/Happy-To-Use-SIMD-41-320.jpg)


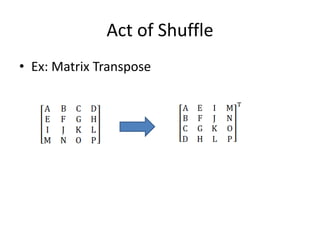
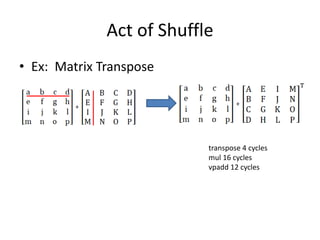
![Act of Shuffle
for(int i=0;i<4;i++)
for(int j=i;j<4;j++)
{
int index0=i*4+j,index1=j*4+i;
float temp=a[index0];
a[index0]=a[index1];
a[index1]=temp;
}
(4+3+2+1)*3
4 4
1
(1+1)*10
(1+1)*10
(1+1)*10*2
159 cycles
(1+1+1+1)*10](https://image.slidesharecdn.com/happytousesimd-210928111705/85/Happy-To-Use-SIMD-46-320.jpg)
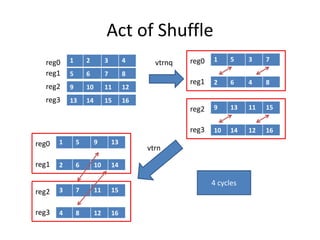
![Act of Shuffle
reg256 temp0,temp1;
reg128 reg0,reg1,reg2,reg3;
temp0._float4x2=vtrnq_f32(reg0,reg1);
temp1._float4x2=vtrnq_f32(reg2,reg3);
float2 temp =temp0._float2[1];
temp0._float2[1]=temp1._float2[0];
temp1._float2[0]=temp;
temp=temp0._float2[3];
temp0._float2[3]=temp1._float[2];
temp1._float[2]=temp;
4 cycles
vtrn
vtrn
39.75x](https://image.slidesharecdn.com/happytousesimd-210928111705/85/Happy-To-Use-SIMD-47-320.jpg)





![Read Element and Write Back
reg128 reg0;
float4 a= {0,1,2,3};
reg0._float4 = a;
float2 val1= reg0._float2[0];
reg0._float2[1]=val1;
float val0=reg0._float[2];
reg0._float[3] = val0;
1. Whether Instruction is supported,
if not, write to L1 Load/Store as same as array.
1. It depends on whether compiler is smart or not!!
0 1 2 3
寫
讀
讀
寫
寫](https://image.slidesharecdn.com/happytousesimd-210928111705/85/Happy-To-Use-SIMD-55-320.jpg)



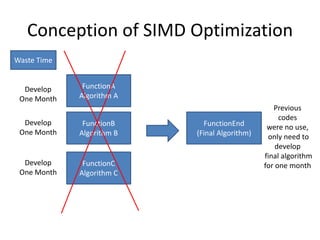


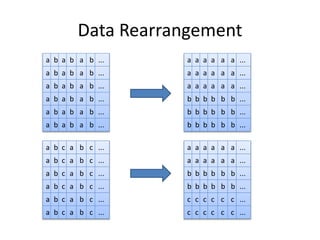






The document discusses SIMD (Single Instruction, Multiple Data) and its optimization techniques for enhancing computational efficiency in C/C++ programming. It covers memory architecture, register usage, cache performance, and specific coding strategies to minimize cycles and latency during data processing. The information highlights the importance of understanding CPU architecture and using vector registers effectively to achieve significant performance improvements.



































































