Download as PDF, PPTX






![Speeds of Process and Thread (1/2)
7
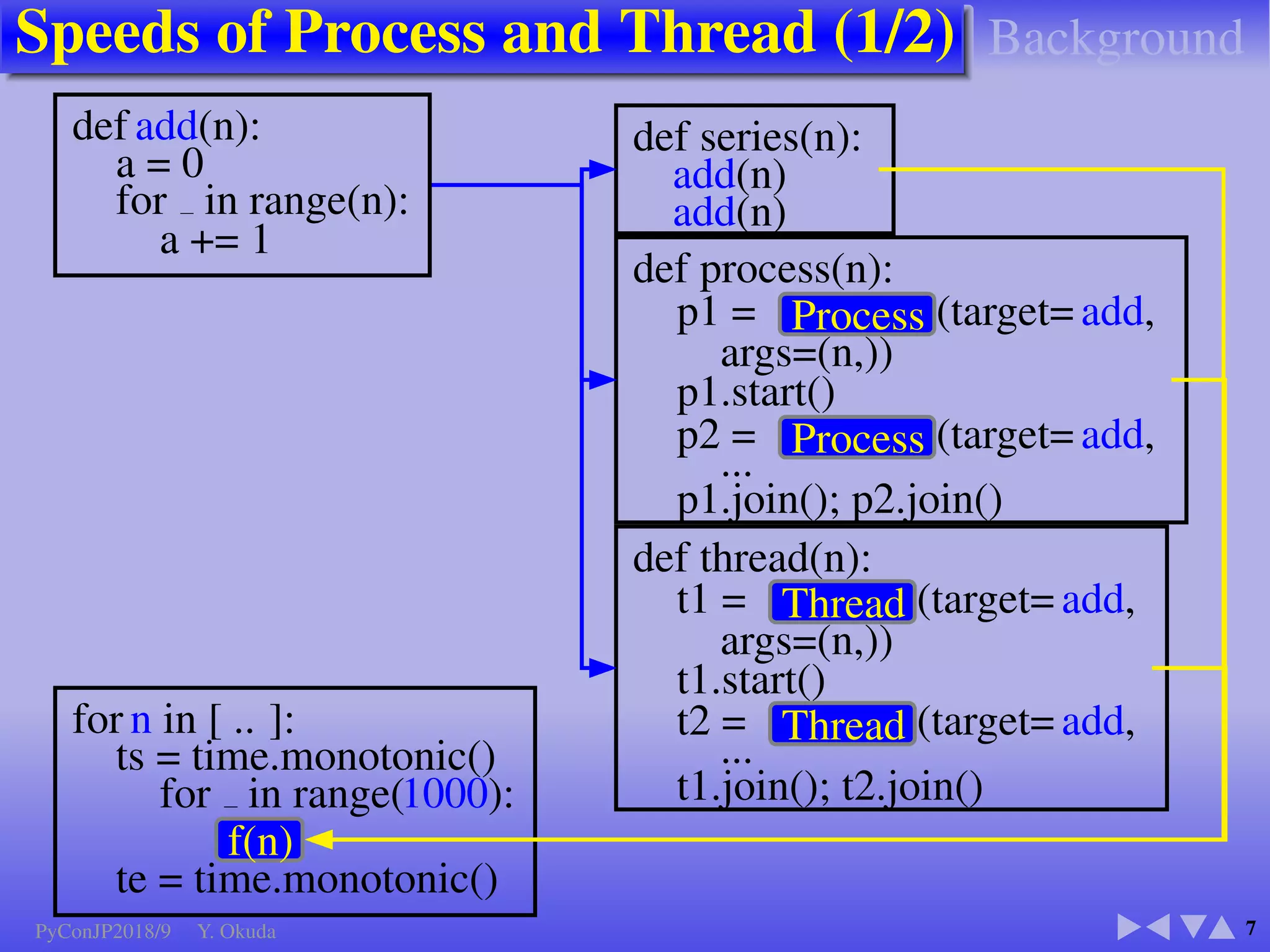
def add(n):
a = 0
for in range(n):
a += 1
for n in [ .. ]:
ts = time.monotonic()
for in range(1000):
f(n)
te = time.monotonic()
def series(n):
add(n)
add(n)
def process(n):
p1 = Process (target= add,
args=(n,))
p1.start()
p2 = Process (target= add,
...
p1.join(); p2.join()
def thread(n):
t1 = Thread (target= add,
args=(n,))
t1.start()
t2 = Thread (target= add,
...
t1.join(); t2.join()
Background
PyConJP2018/9 Y. Okuda](https://image.slidesharecdn.com/okudapyconjp2018-180926164917/75/Comparing-On-The-Fly-Accelerating-Packages-Numba-TensorFlow-Dask-etc-14-2048.jpg)



![Is Thread Safe? (1/2)
9
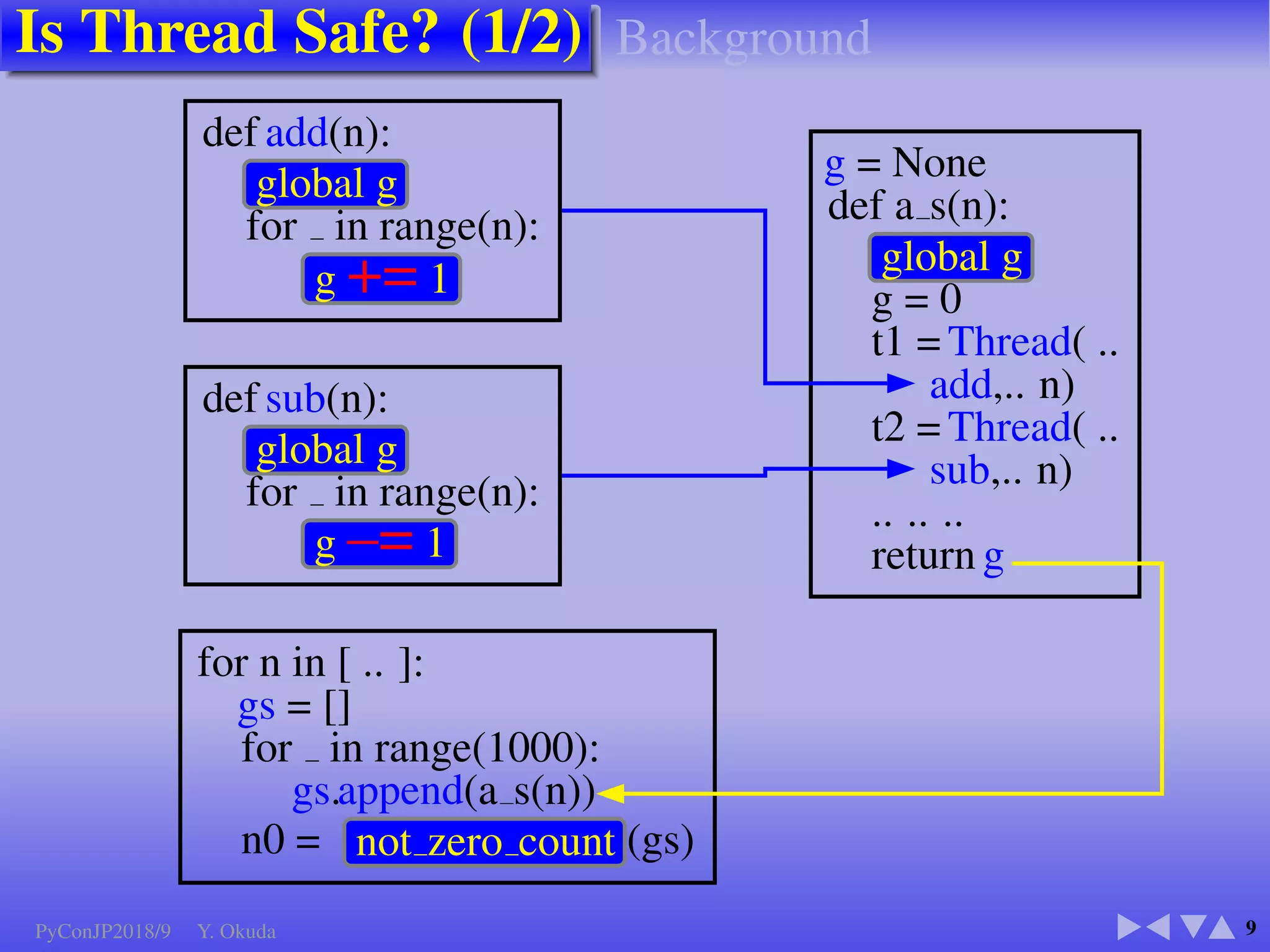
def add(n):
global g
for in range(n):
g += 1
def sub(n):
global g
for in range(n):
g –= 1
g = None
def a s(n):
global g
g = 0
t1 = Thread( ..
add,.. n)
t2 = Thread( ..
sub,.. n)
.. .. ..
return g
for n in [ .. ]:
gs = []
for in range(1000):
gs.append(a s(n))
n0 = not zero count (gs)
Background
PyConJP2018/9 Y. Okuda](https://image.slidesharecdn.com/okudapyconjp2018-180926164917/75/Comparing-On-The-Fly-Accelerating-Packages-Numba-TensorFlow-Dask-etc-22-2048.jpg)

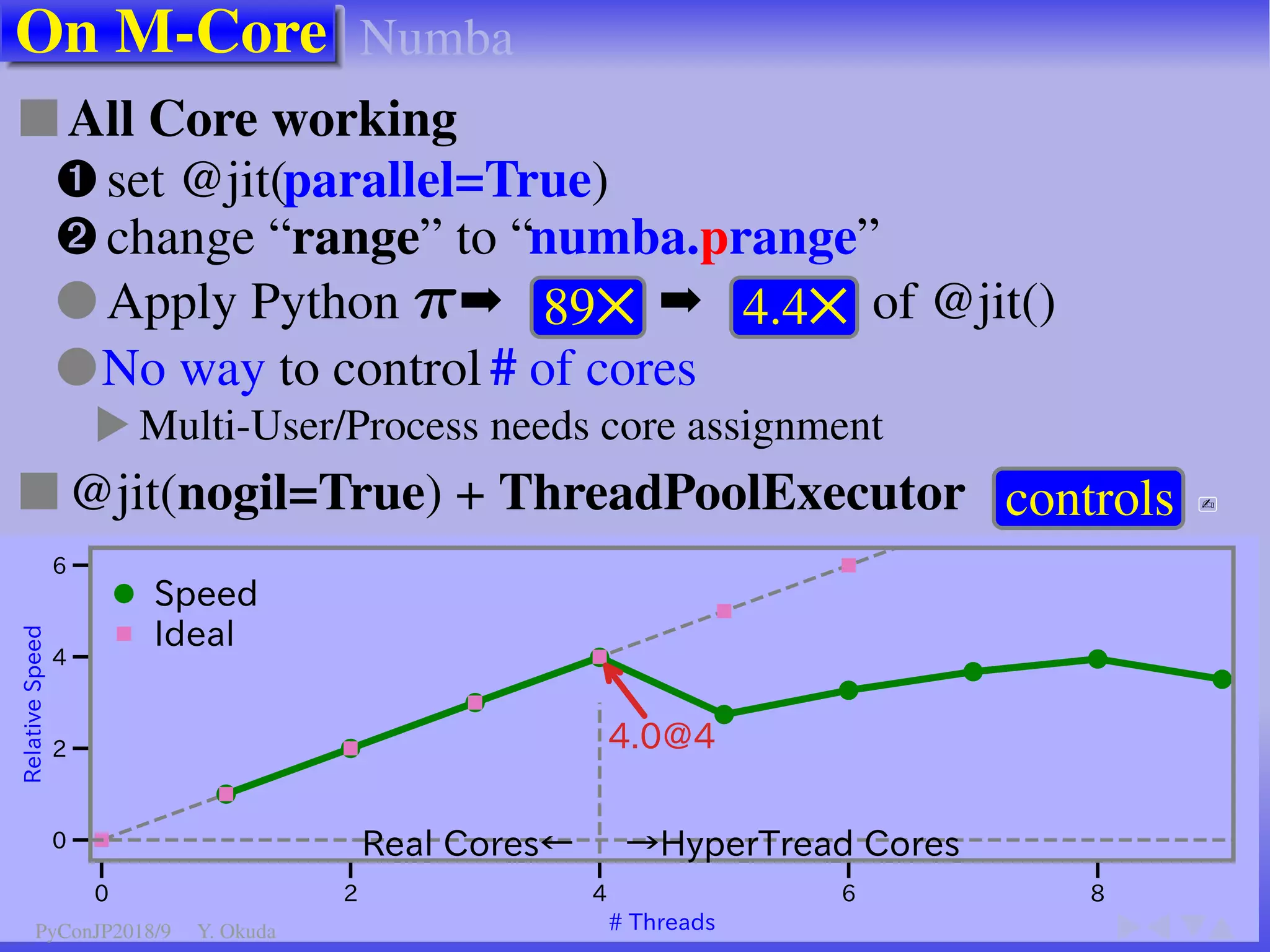

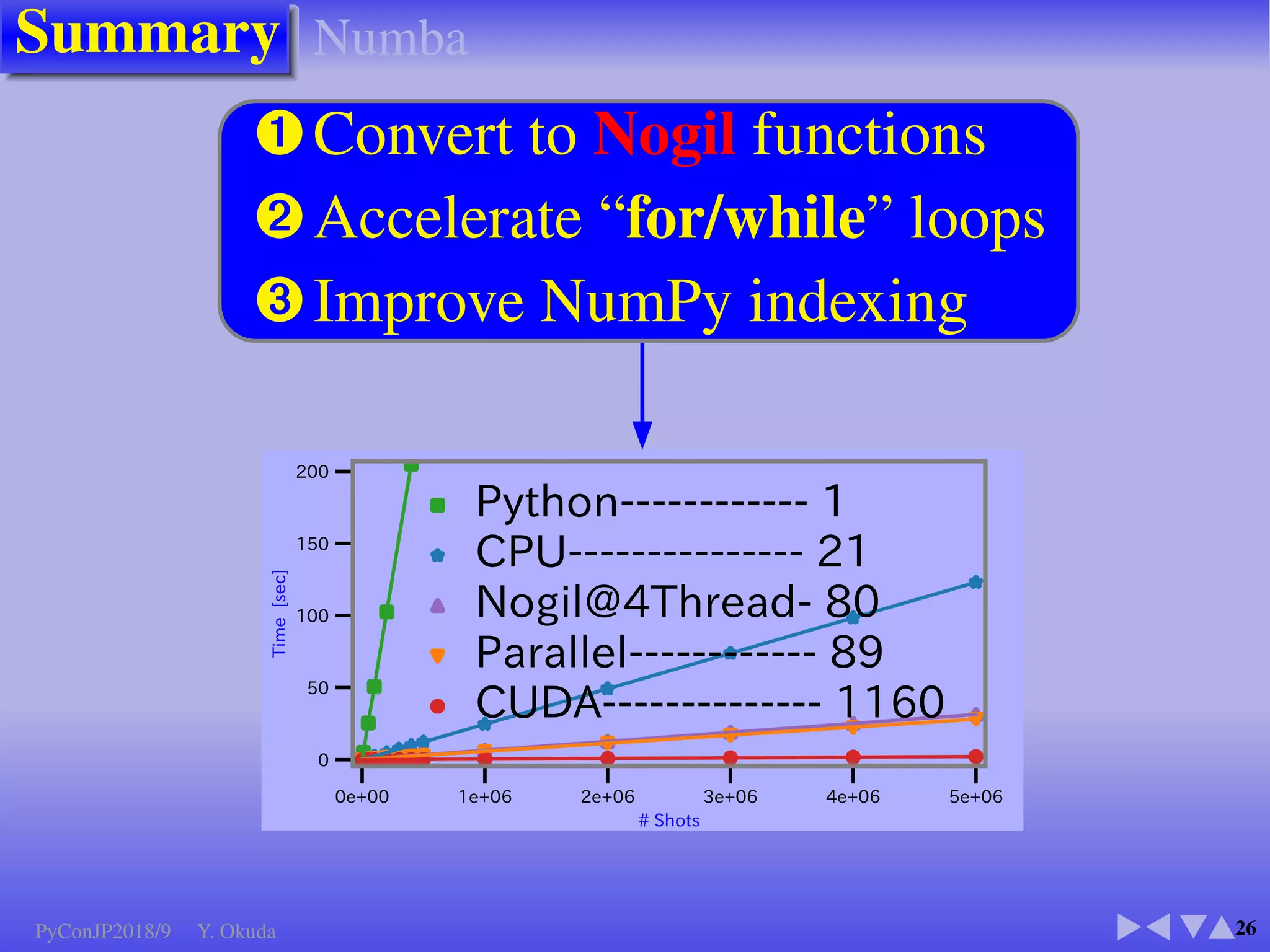


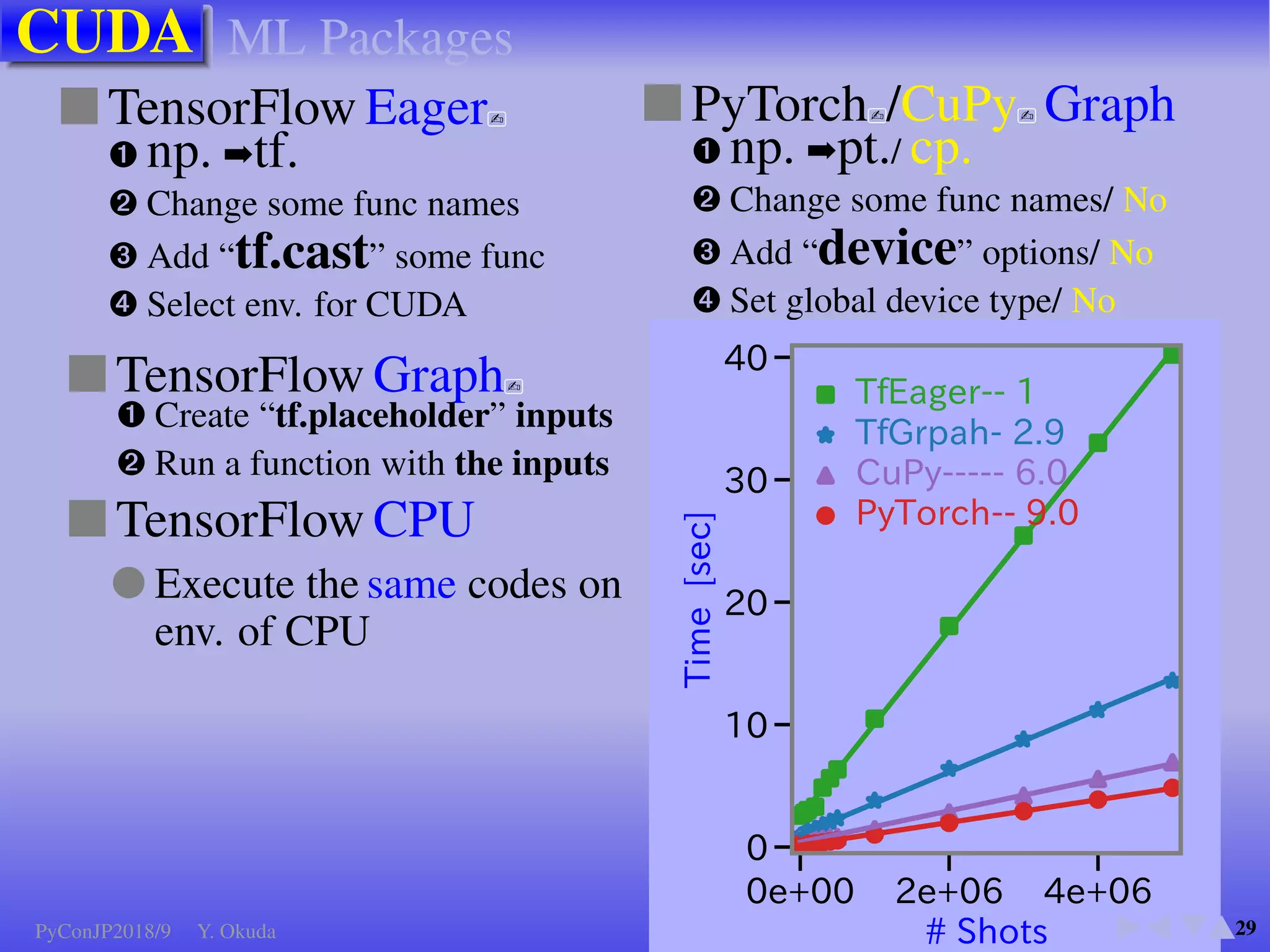
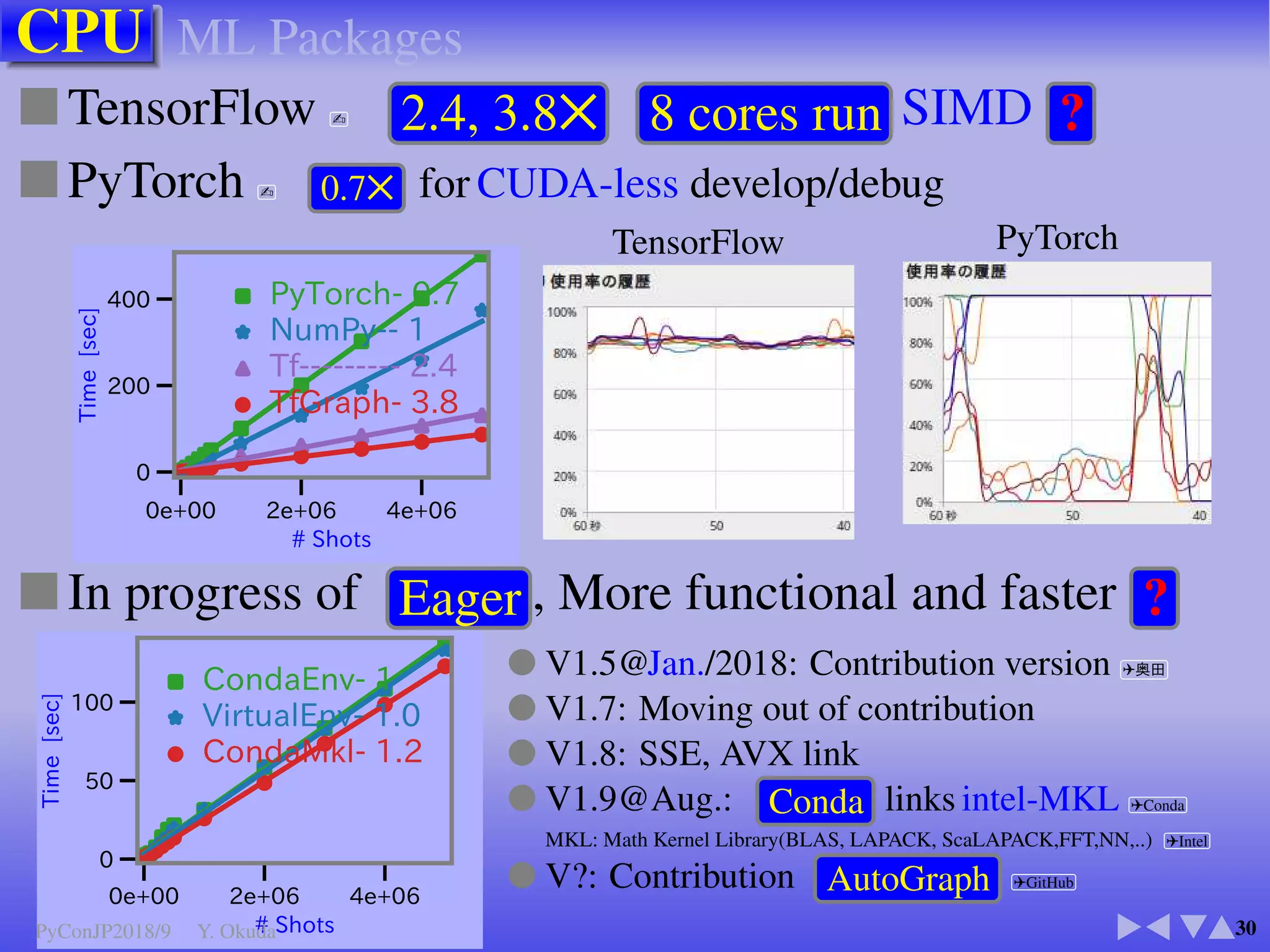
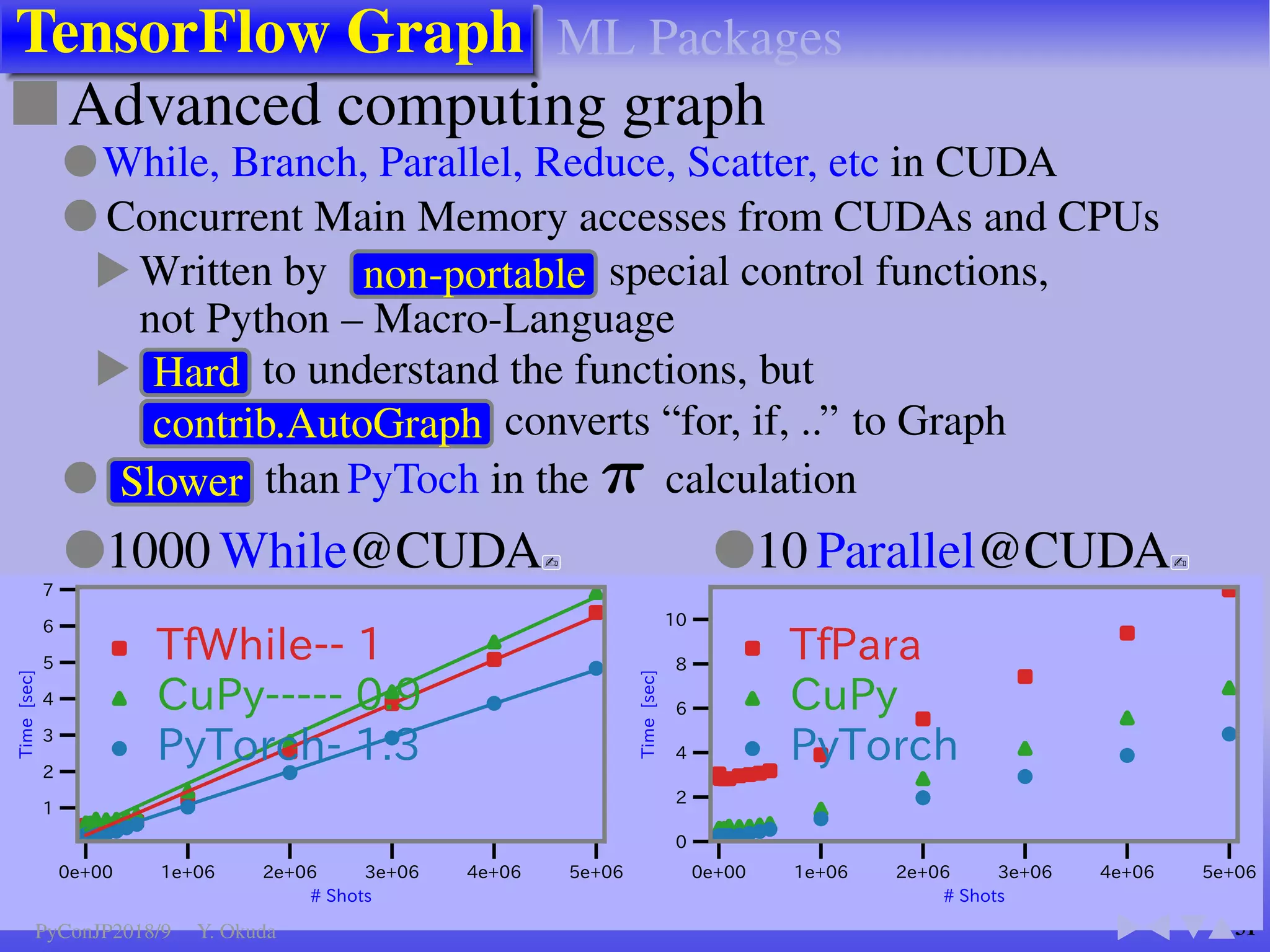
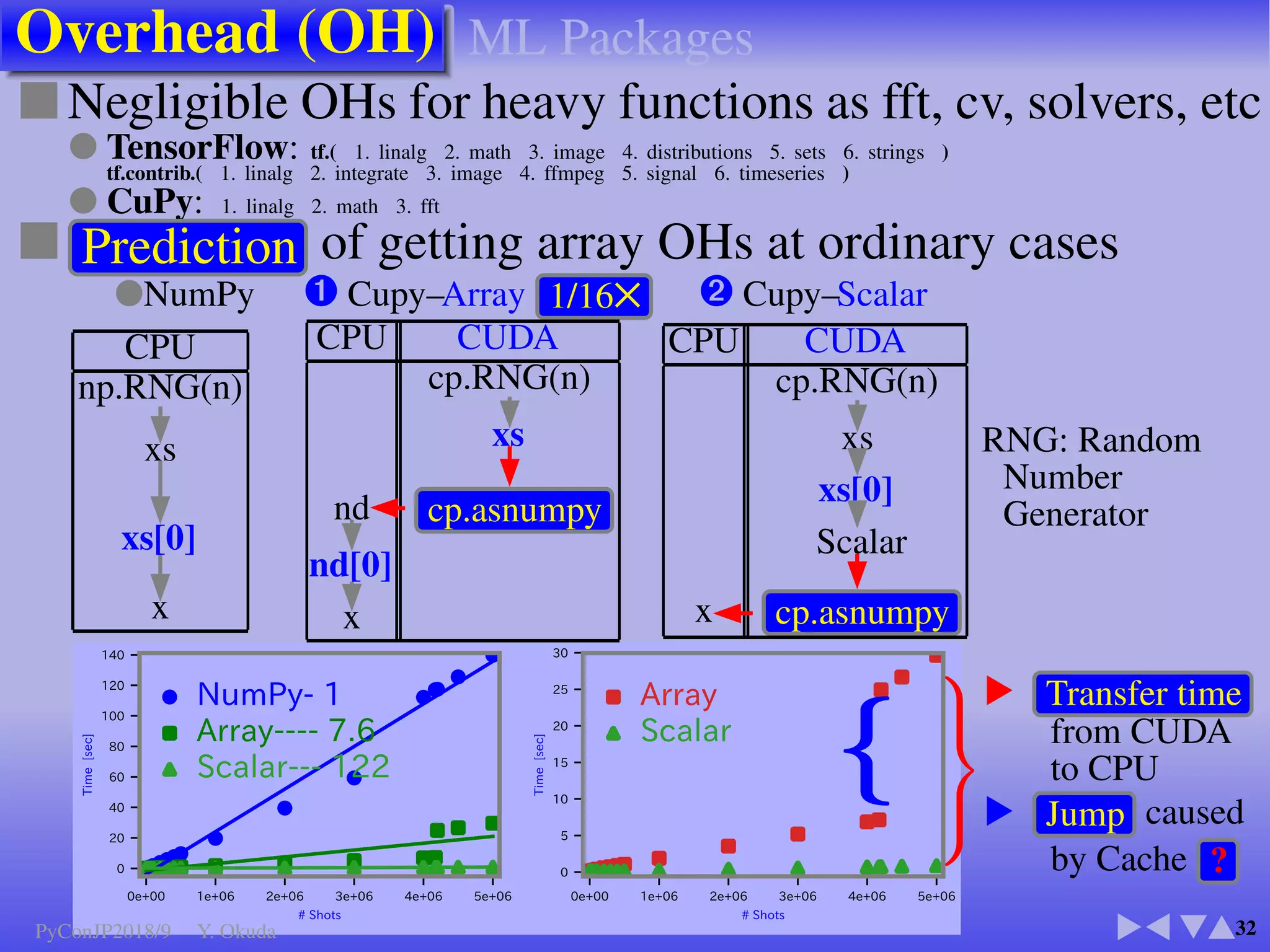
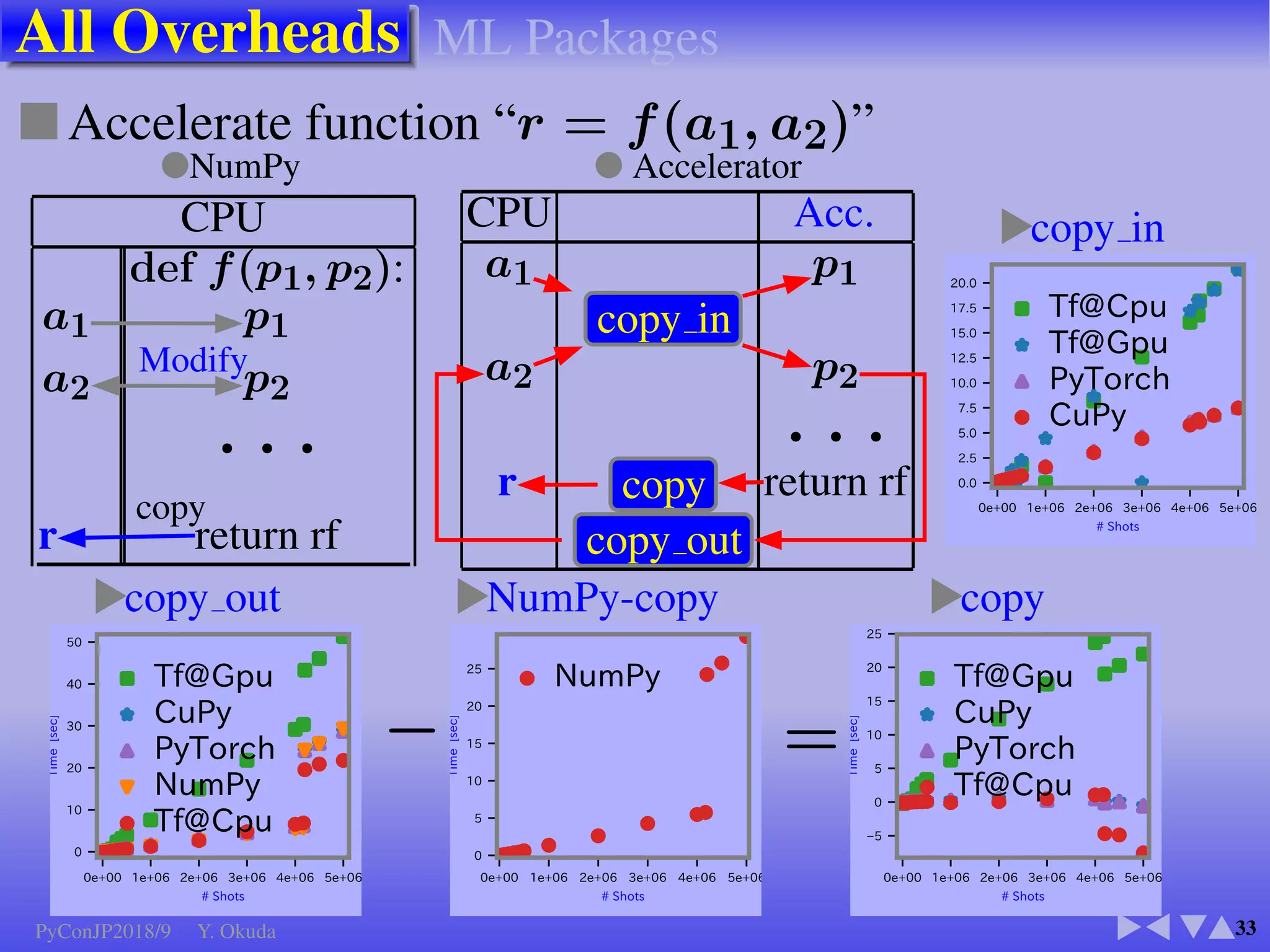
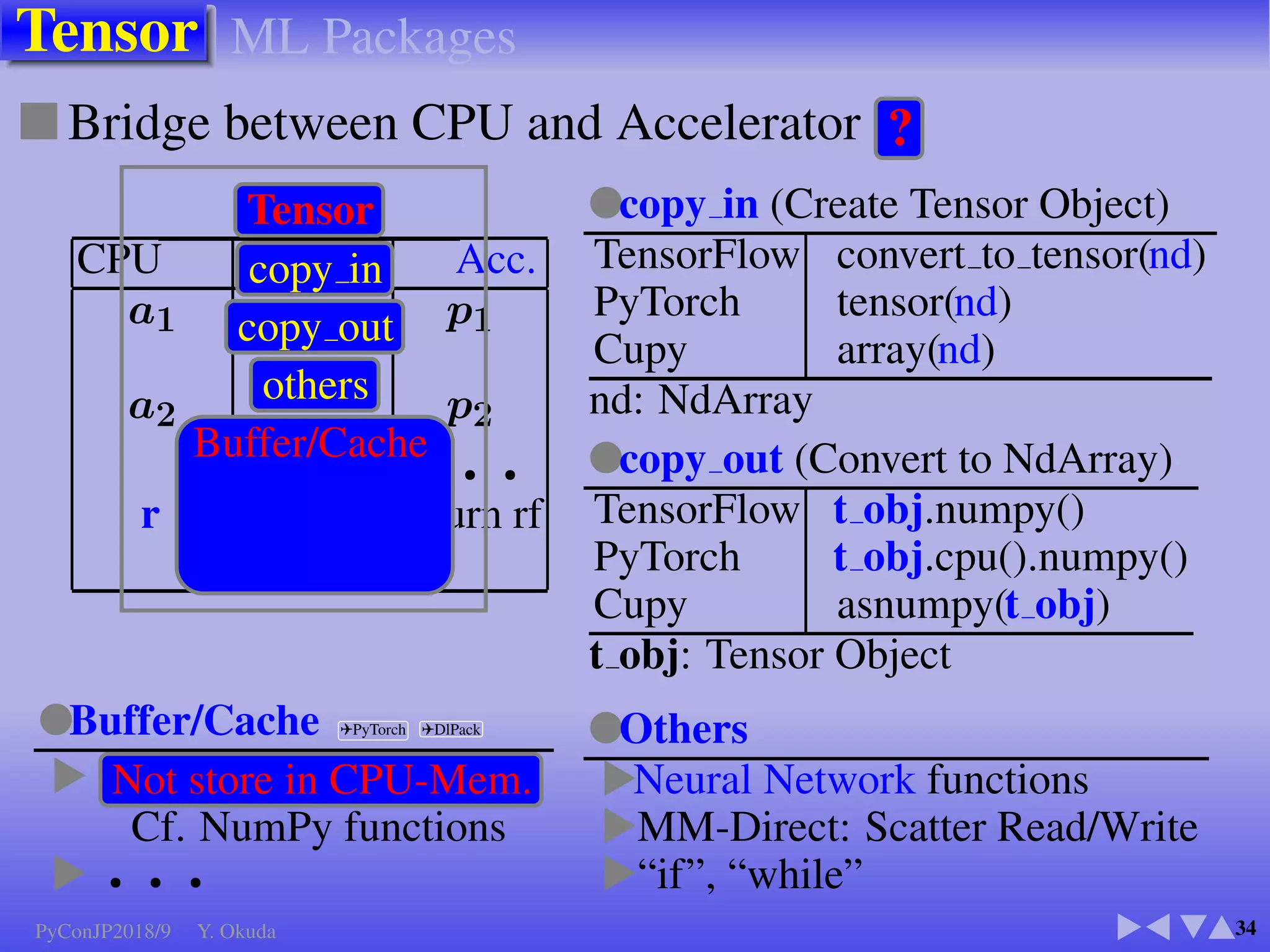
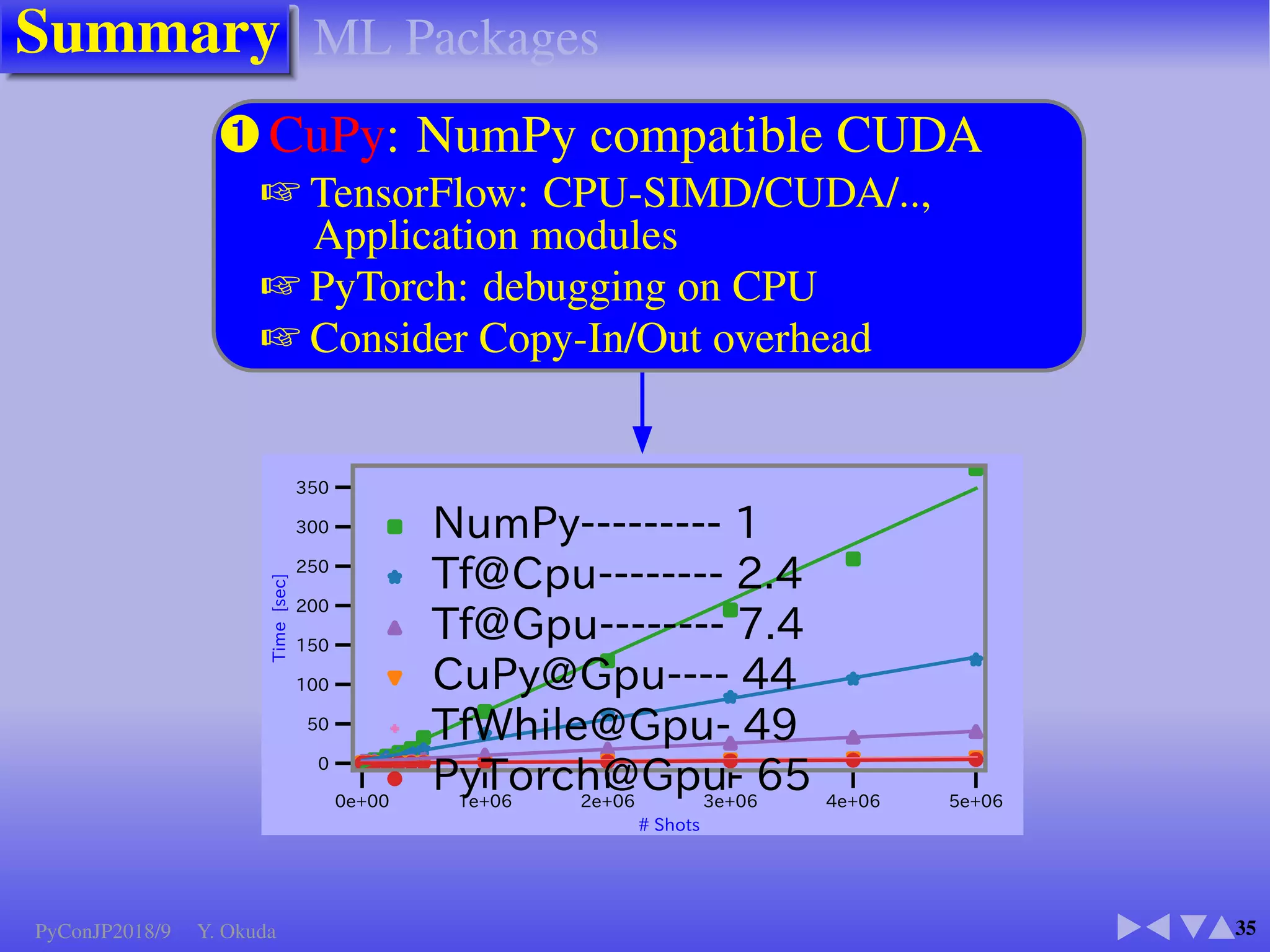

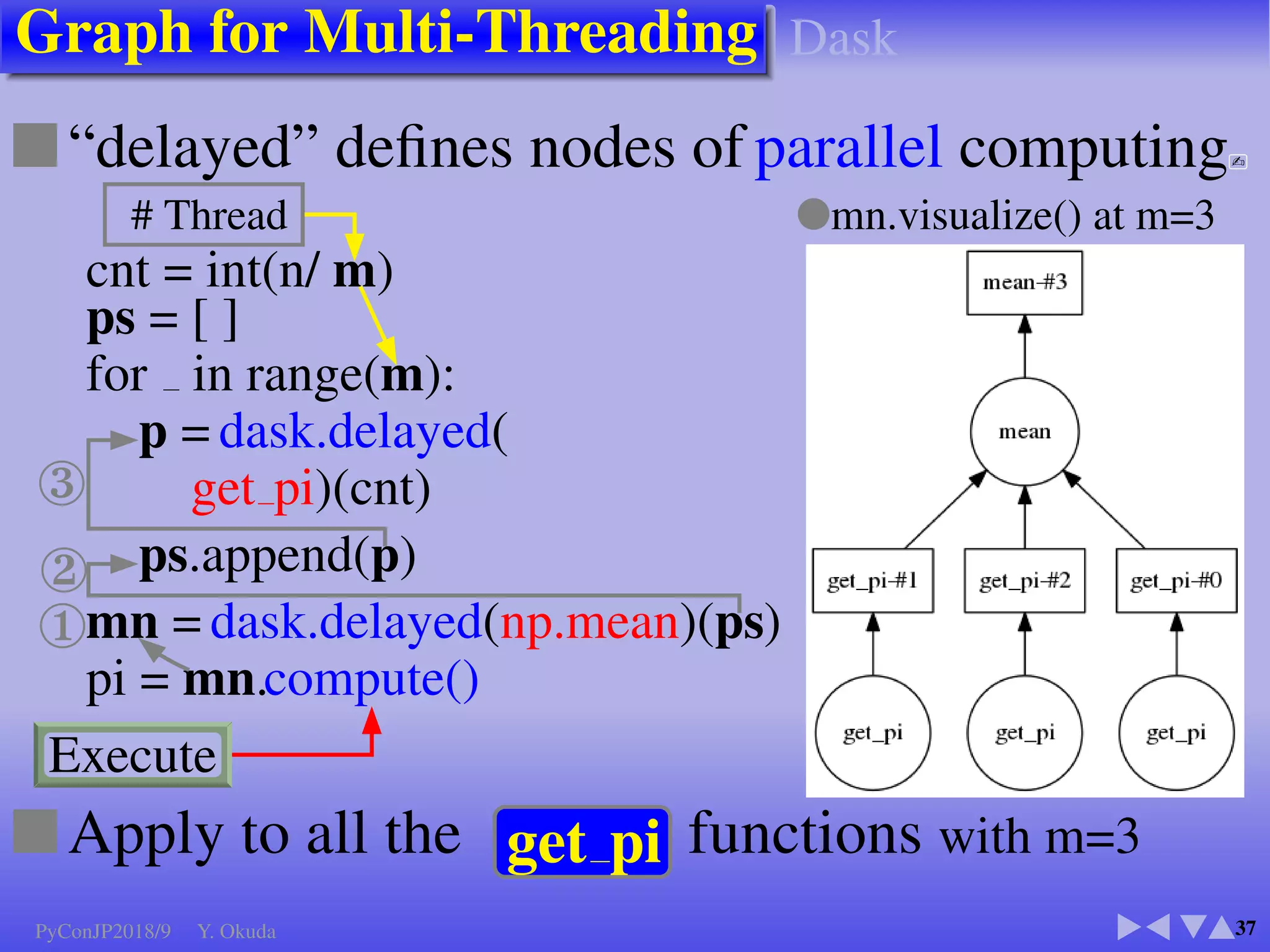
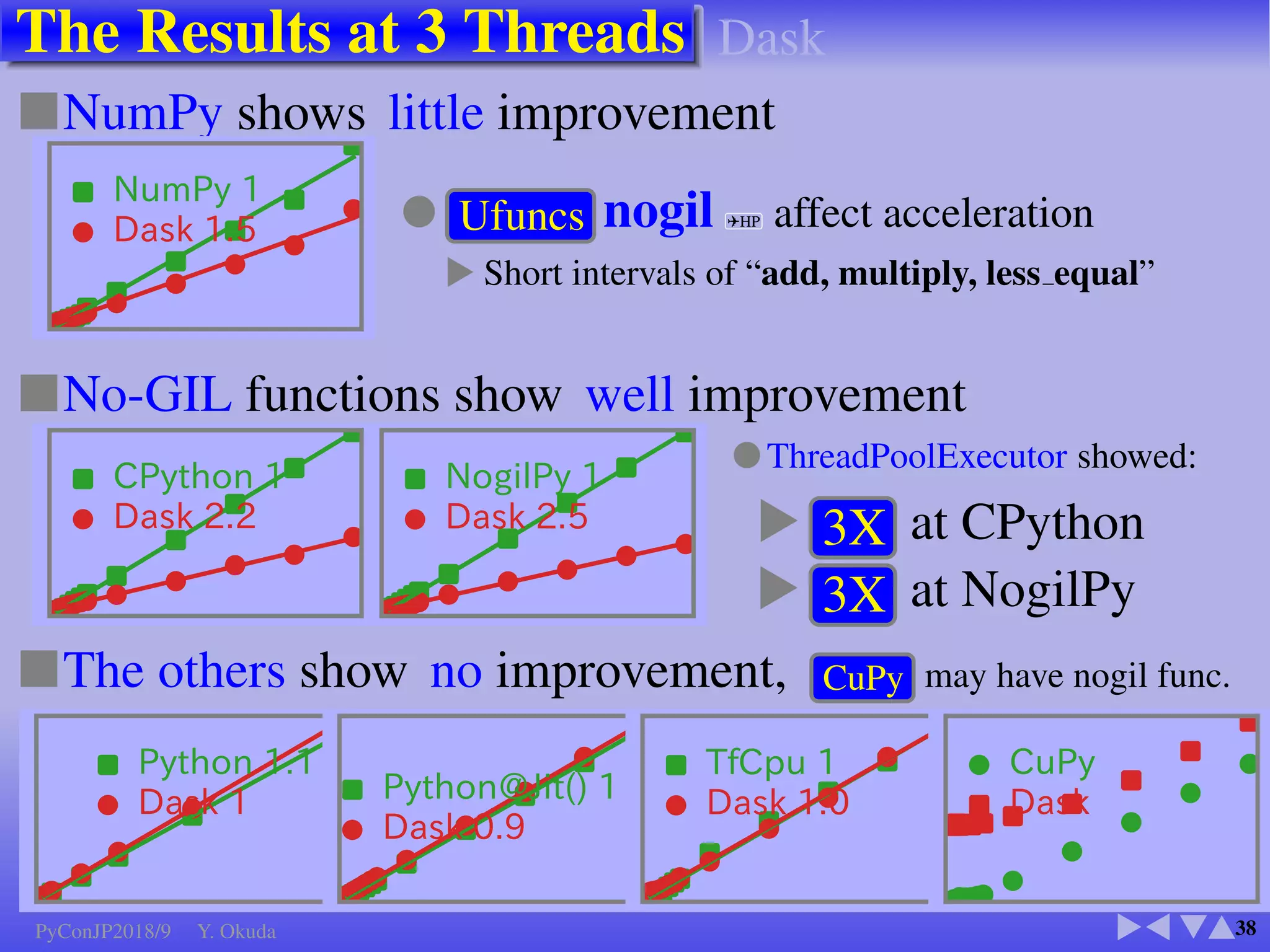
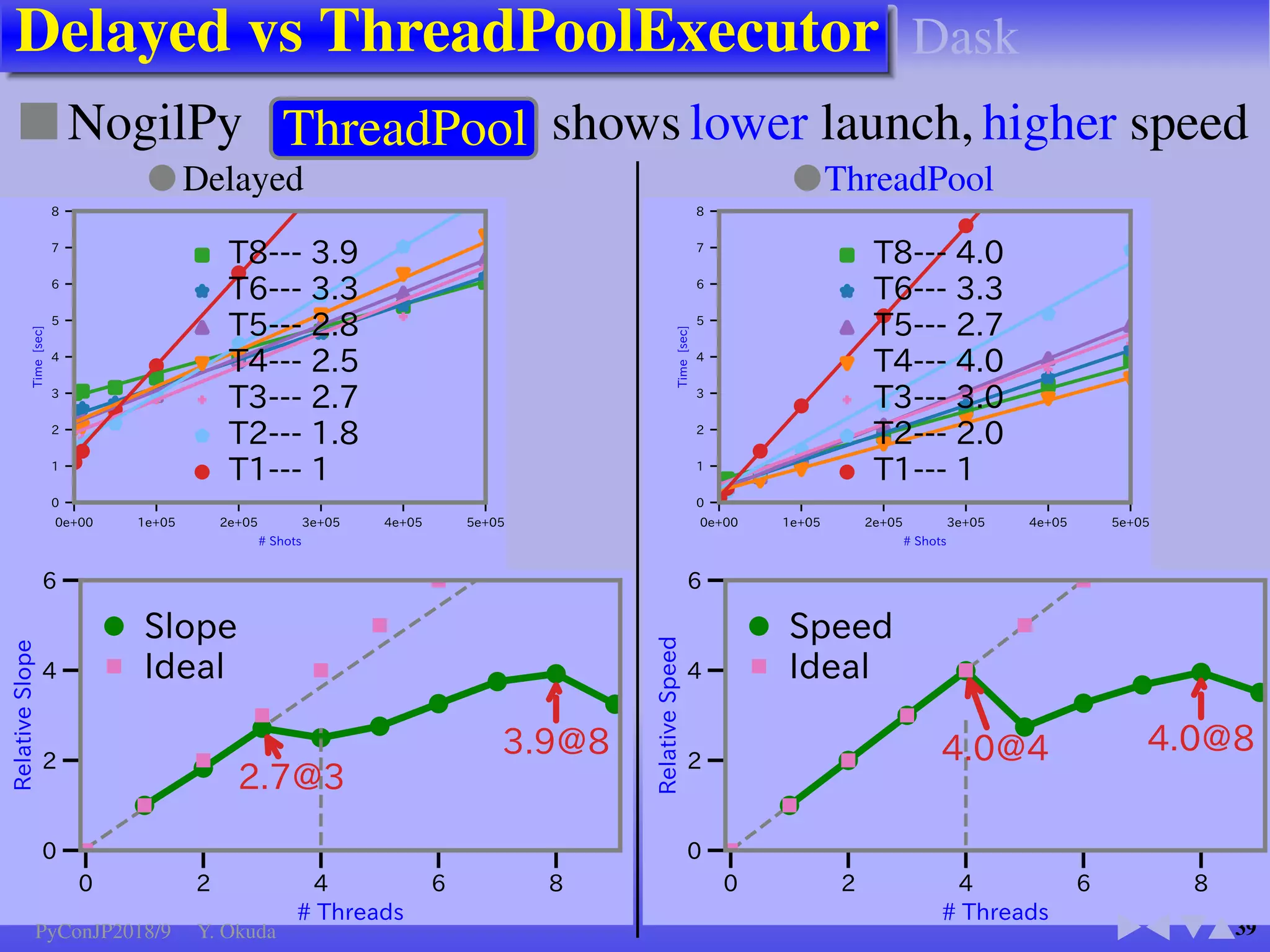
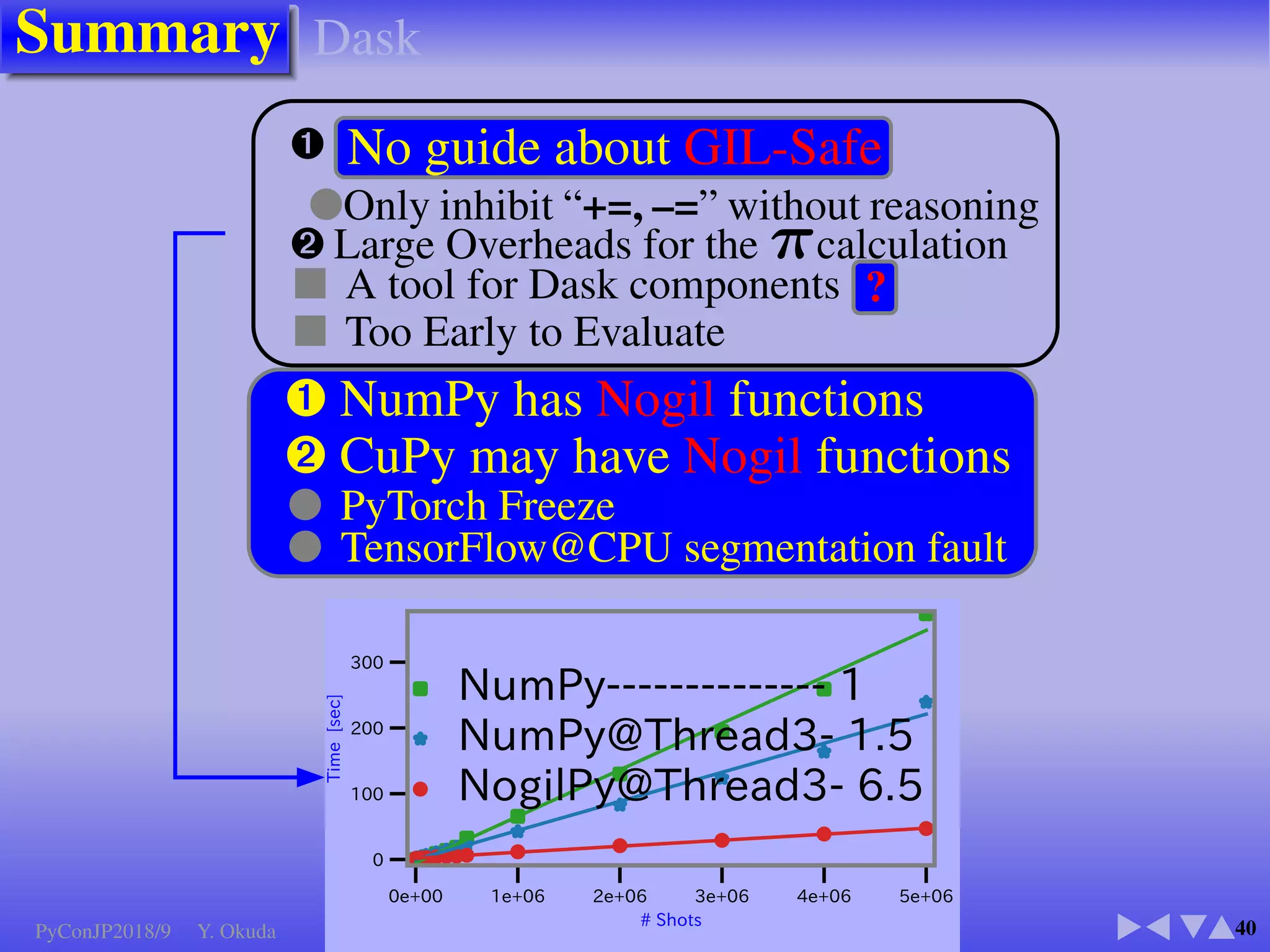

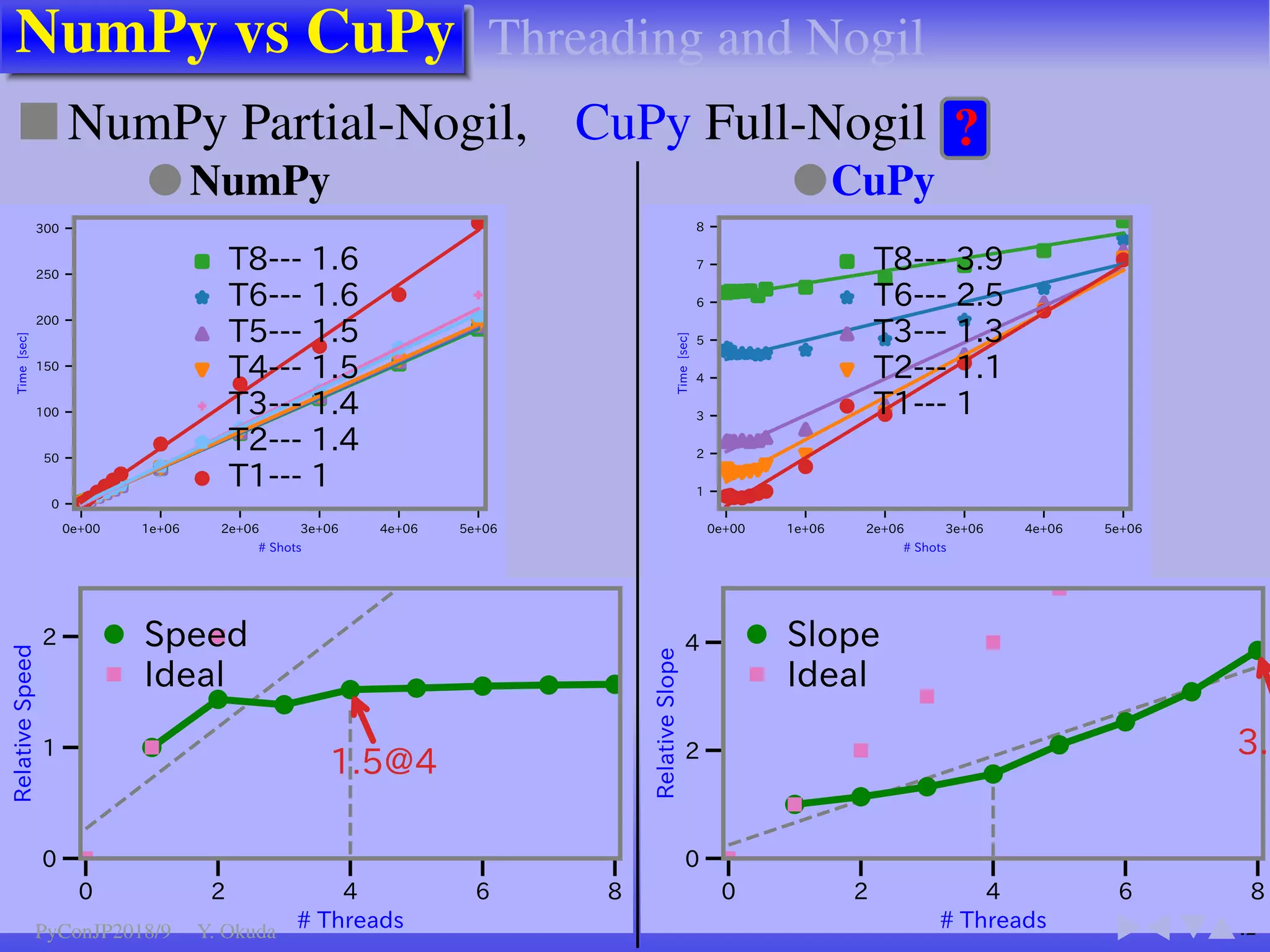
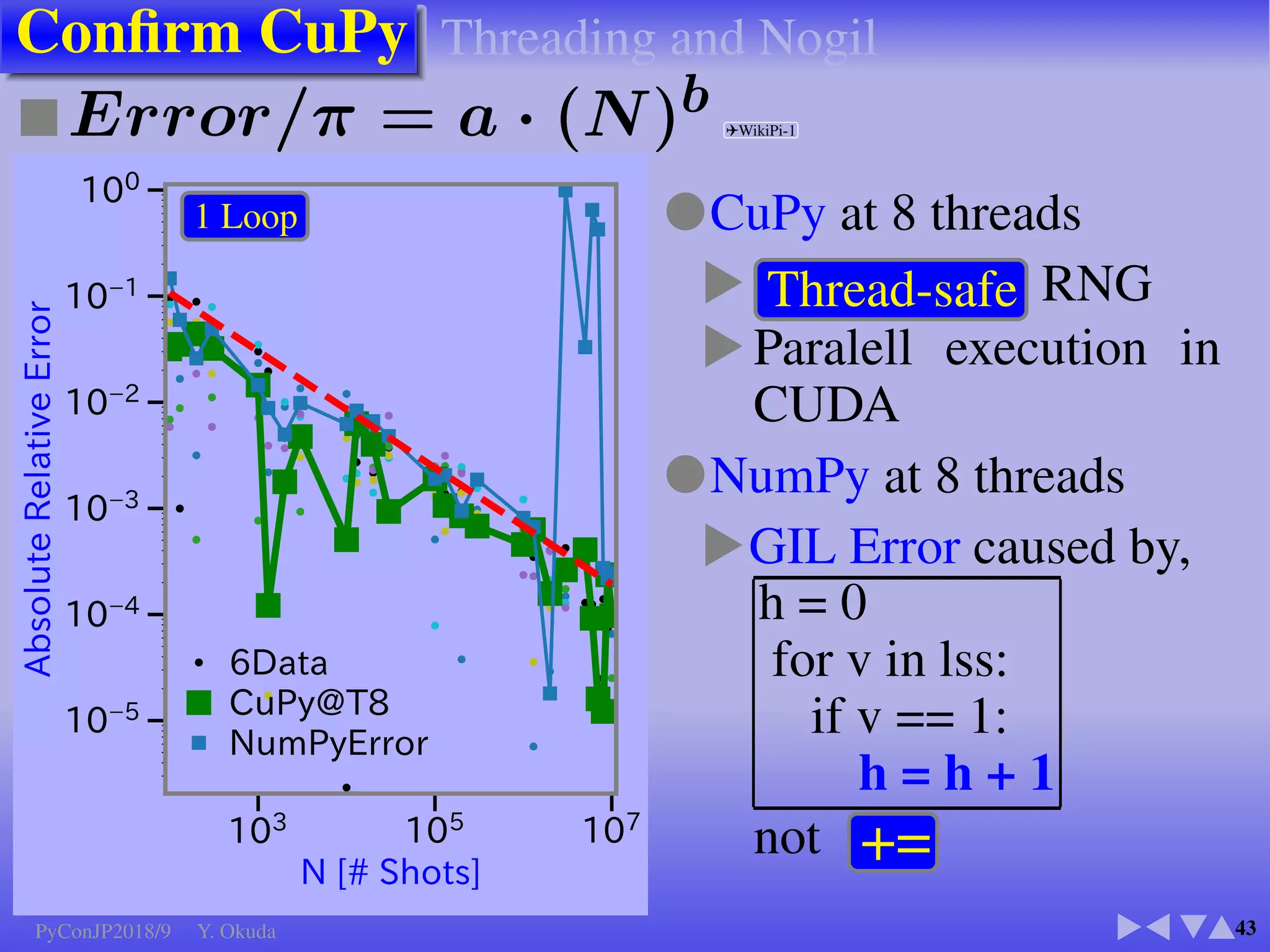
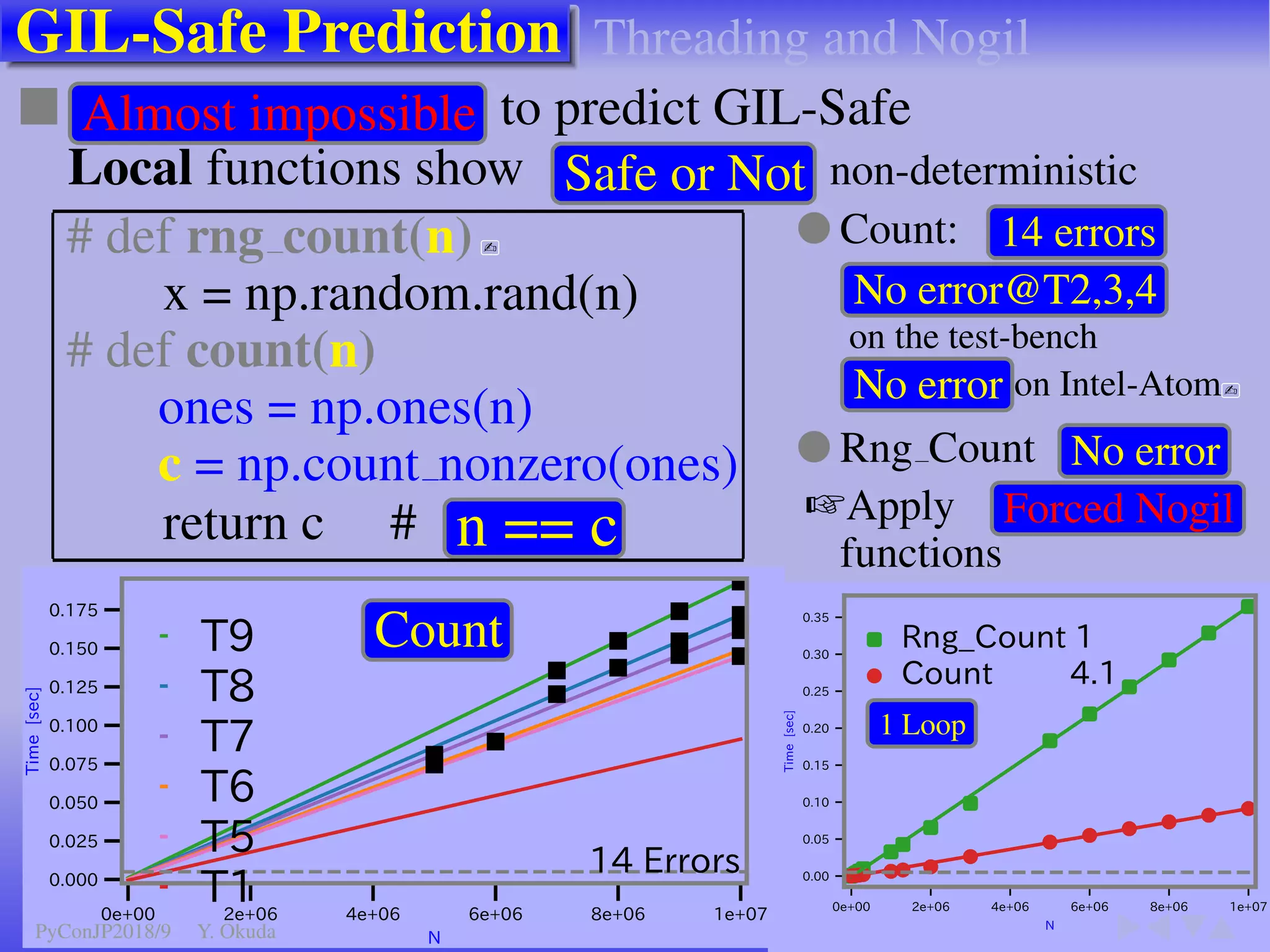
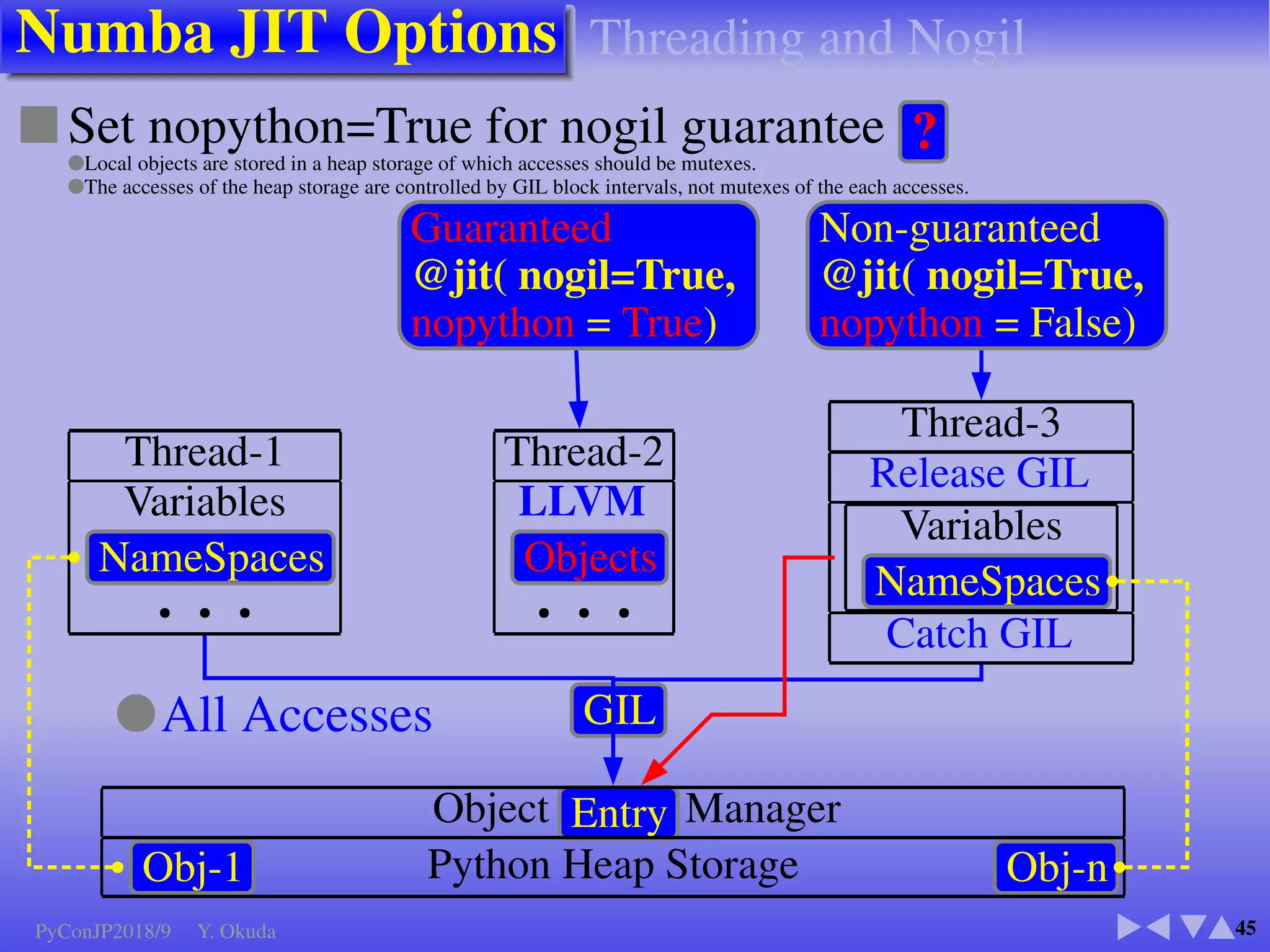


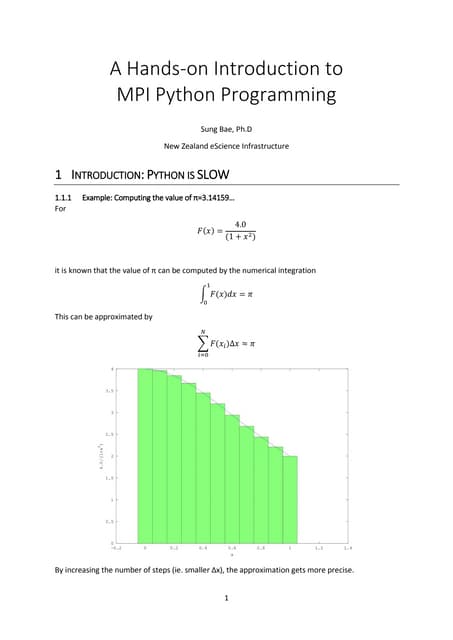
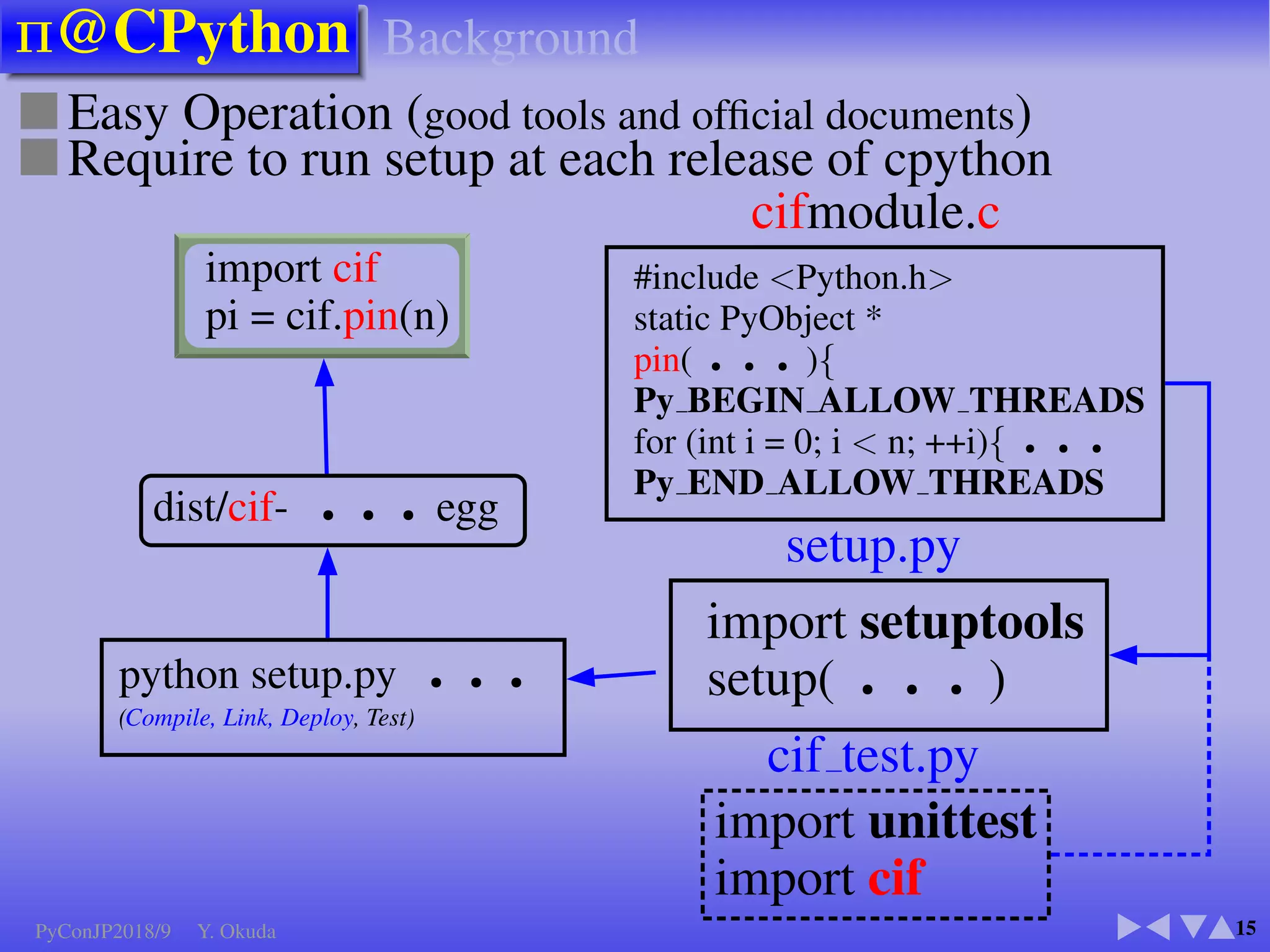
●Many Python codes: ✈Official ✈NumPy
▼
Language: All except class, try, except, with, yield
▼
Function call: inner,closure, recursive
▼
Built-in:abs() bool complex divmod() enumerate() float int iter() len() min() max() next() print() range round()
sorted() type() zip()
▼
NumPy: all() any() argmax() argmin() cumprod() cumsum() max() mean() min() nonzero() prod() std()
take() var() argsort() astype() copy() flatten() item() itemset() ravel() reshape() sort() sum() transpose() view()
▼
Modules: array, cmath, collections, ctypes, enum, math, operator, functools, random, cffi
● CUDA Kernel codes ● NumPy: Not Supported
Numba
PyConJP2018/9 Y. Okuda](https://image.slidesharecdn.com/okudapyconjp2018-180926164917/75/Comparing-On-The-Fly-Accelerating-Packages-Numba-TensorFlow-Dask-etc-49-2048.jpg)

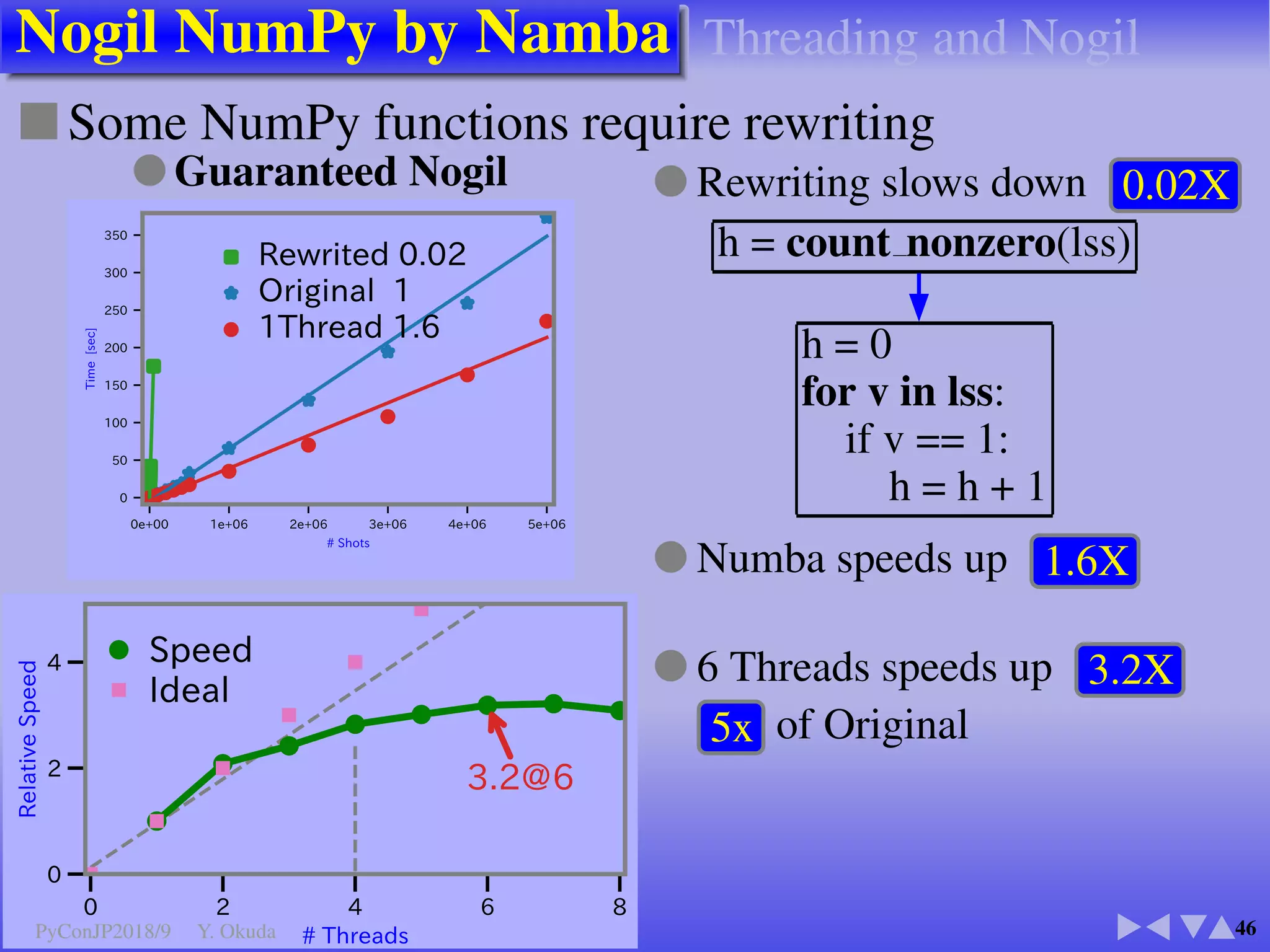
![Accelerate NumPy Indexing
23
■ Jit NumPy indexing ➡ 817✕ , actual 100✕ ✈Murillo
● “for loop” and a function vector operations
on List and NdArray by native and Jit
def for add(n, vs):
for i in range(n):
vs[i] += 1
def np add(n, vs):
a = np.add (vs, 1)
F](https://image.slidesharecdn.com/okudapyconjp2018-180926164917/75/Comparing-On-The-Fly-Accelerating-Packages-Numba-TensorFlow-Dask-etc-51-2048.jpg)




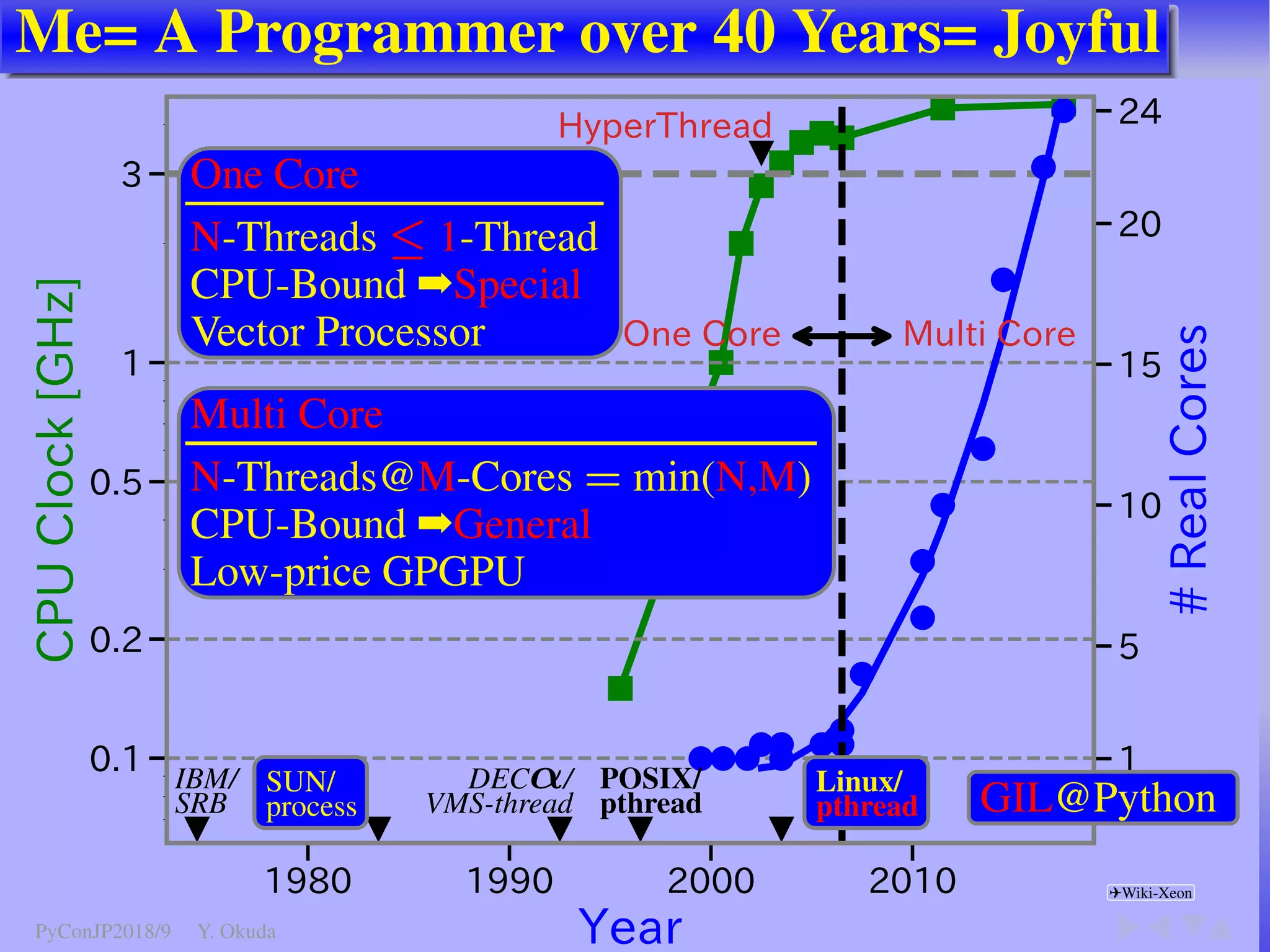
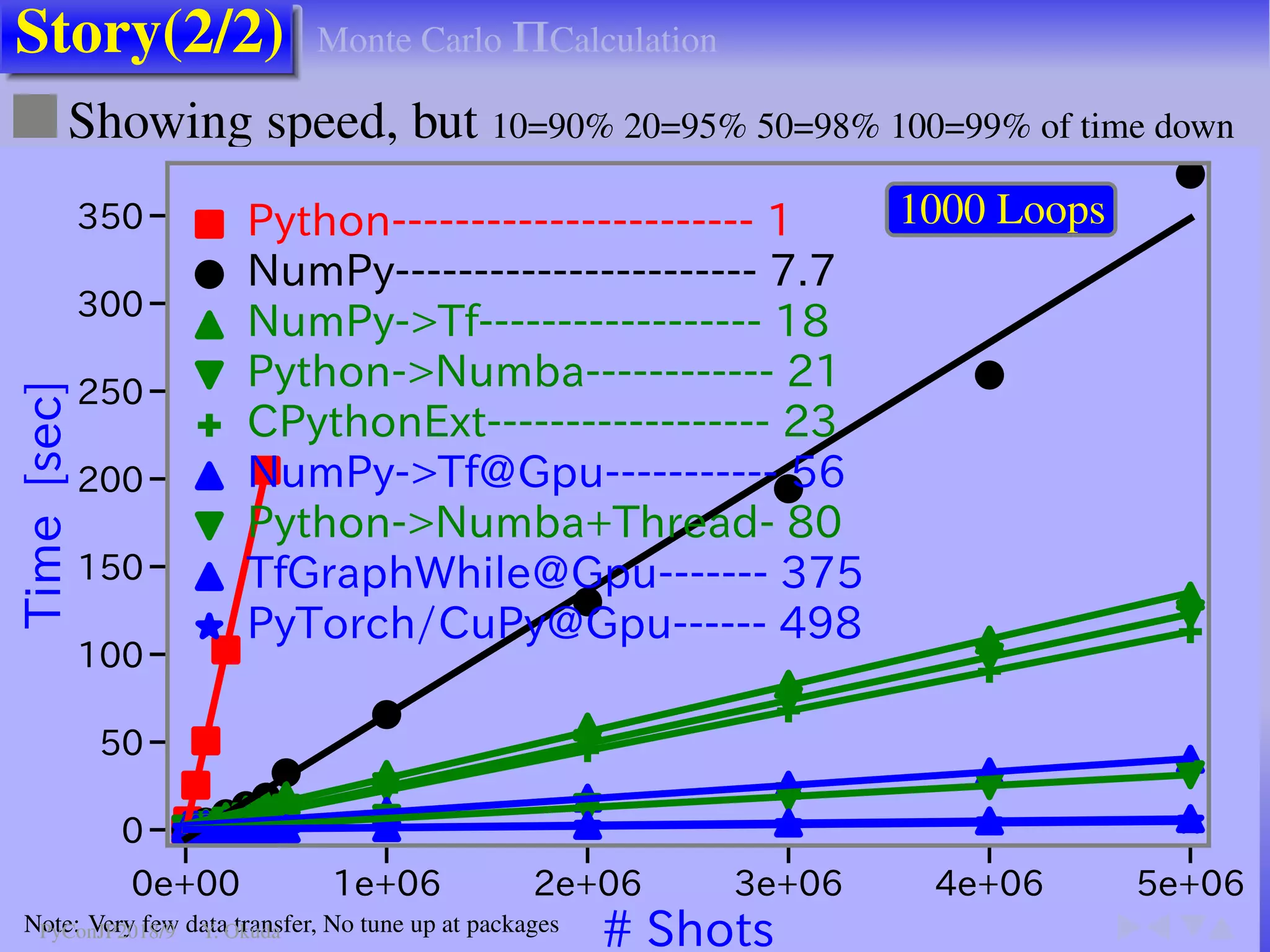
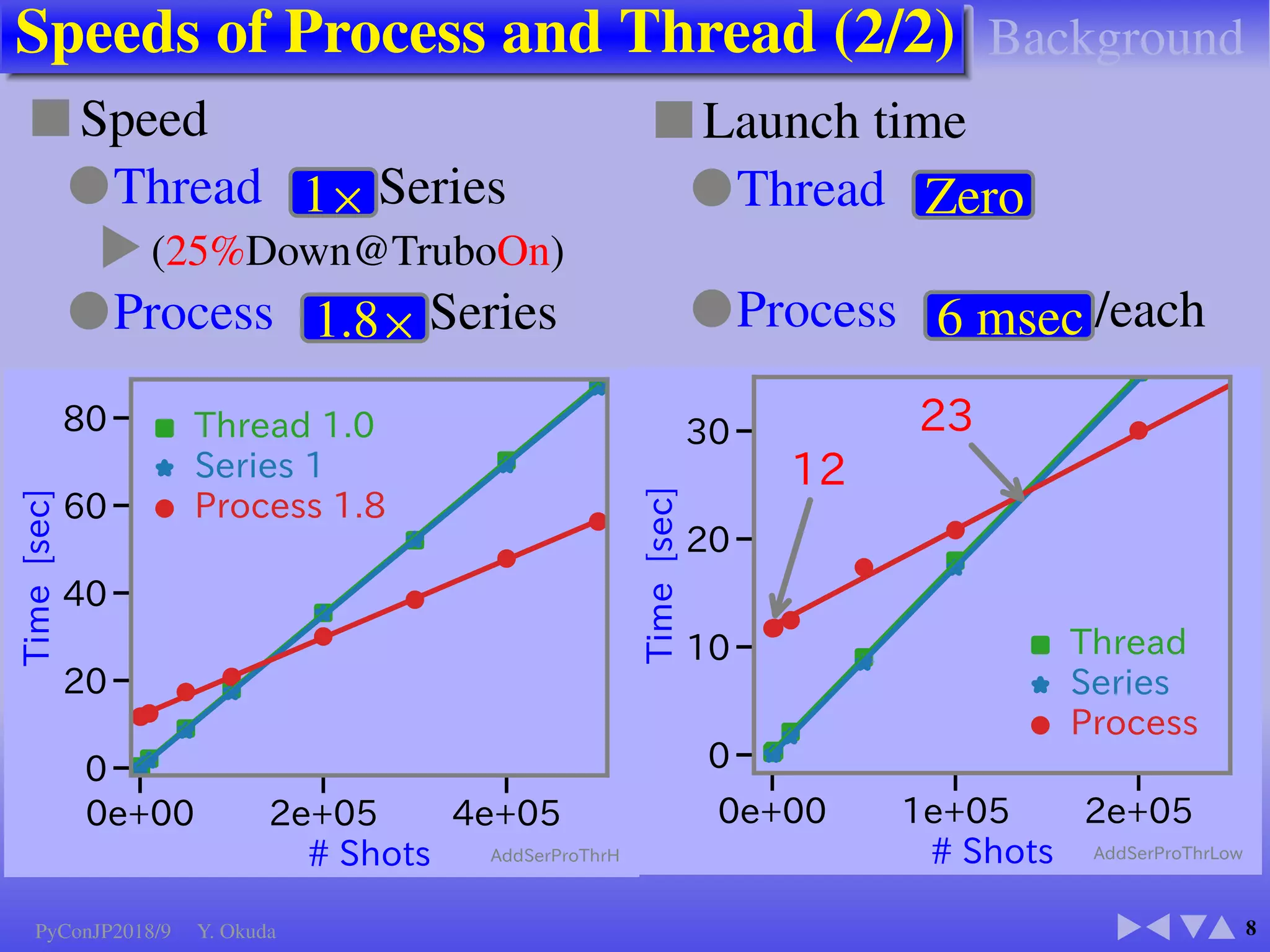
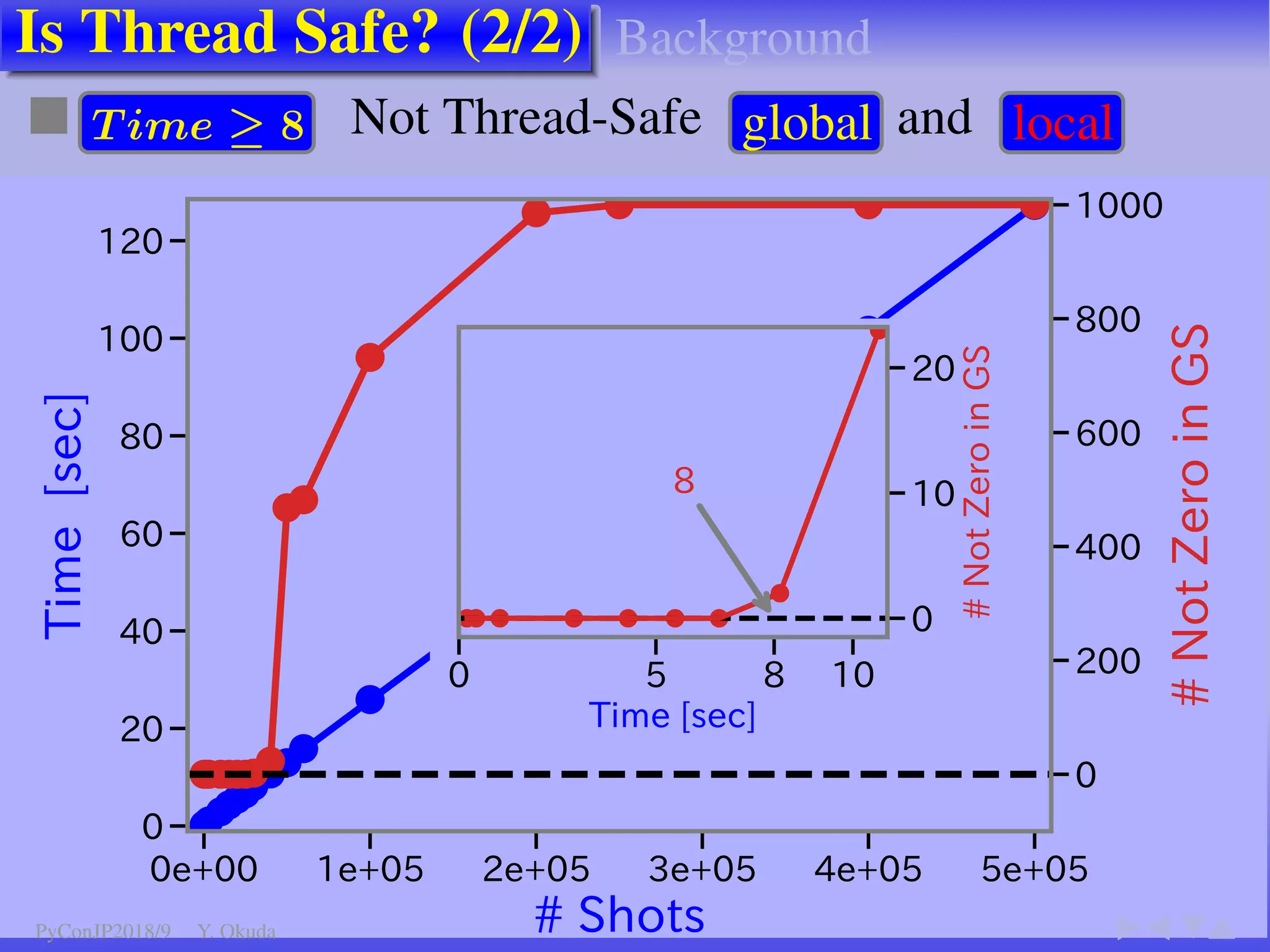
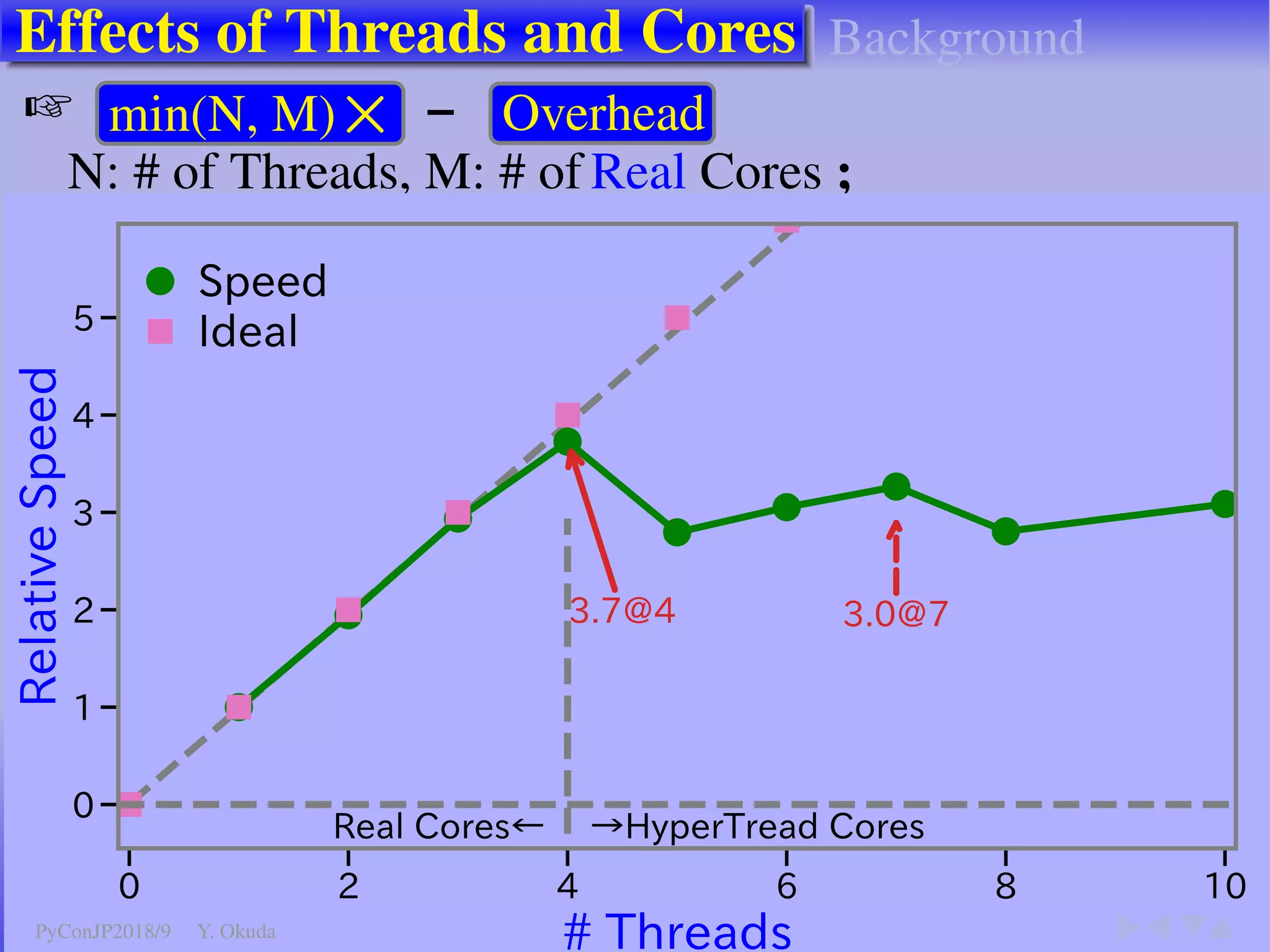
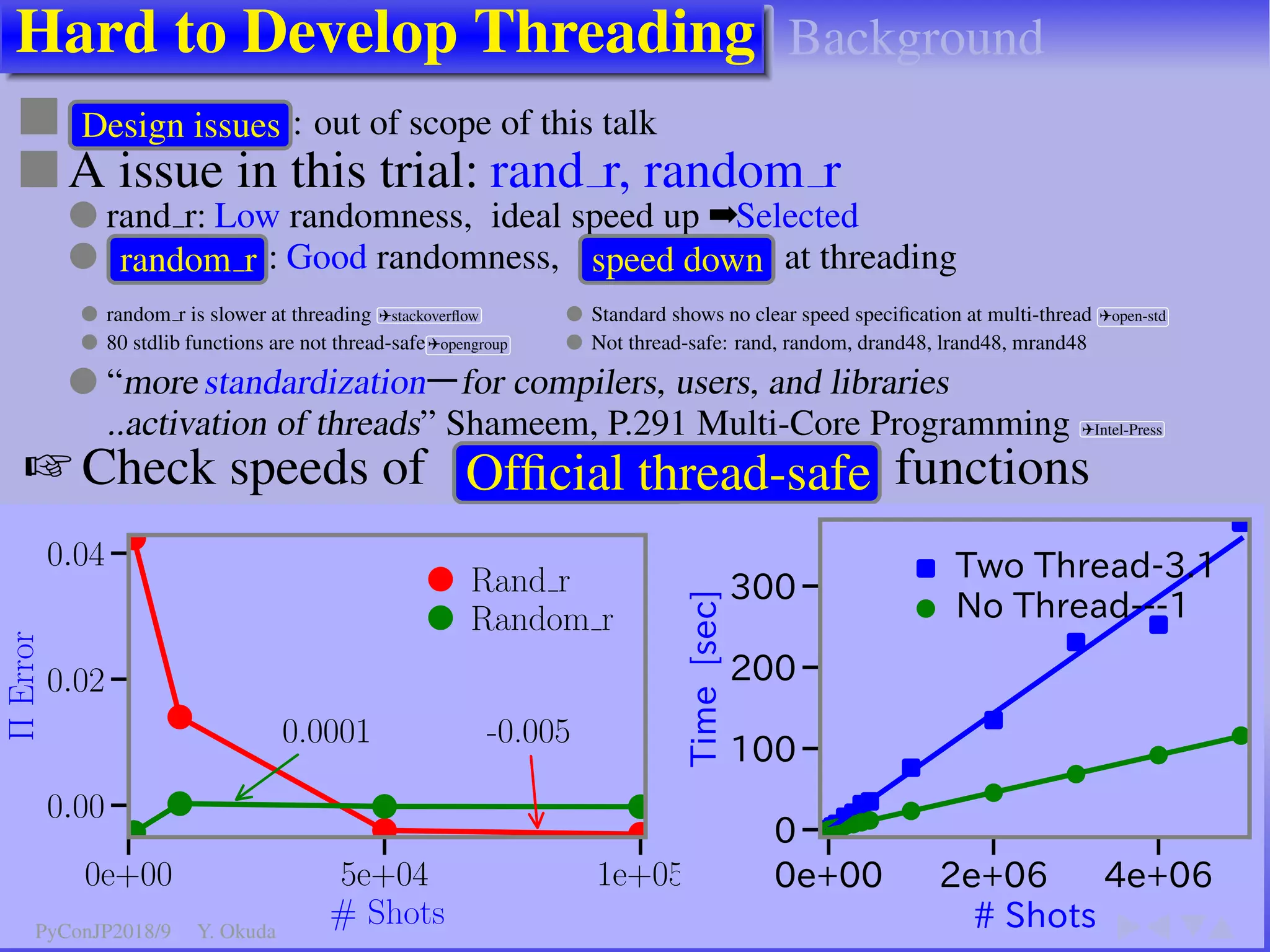
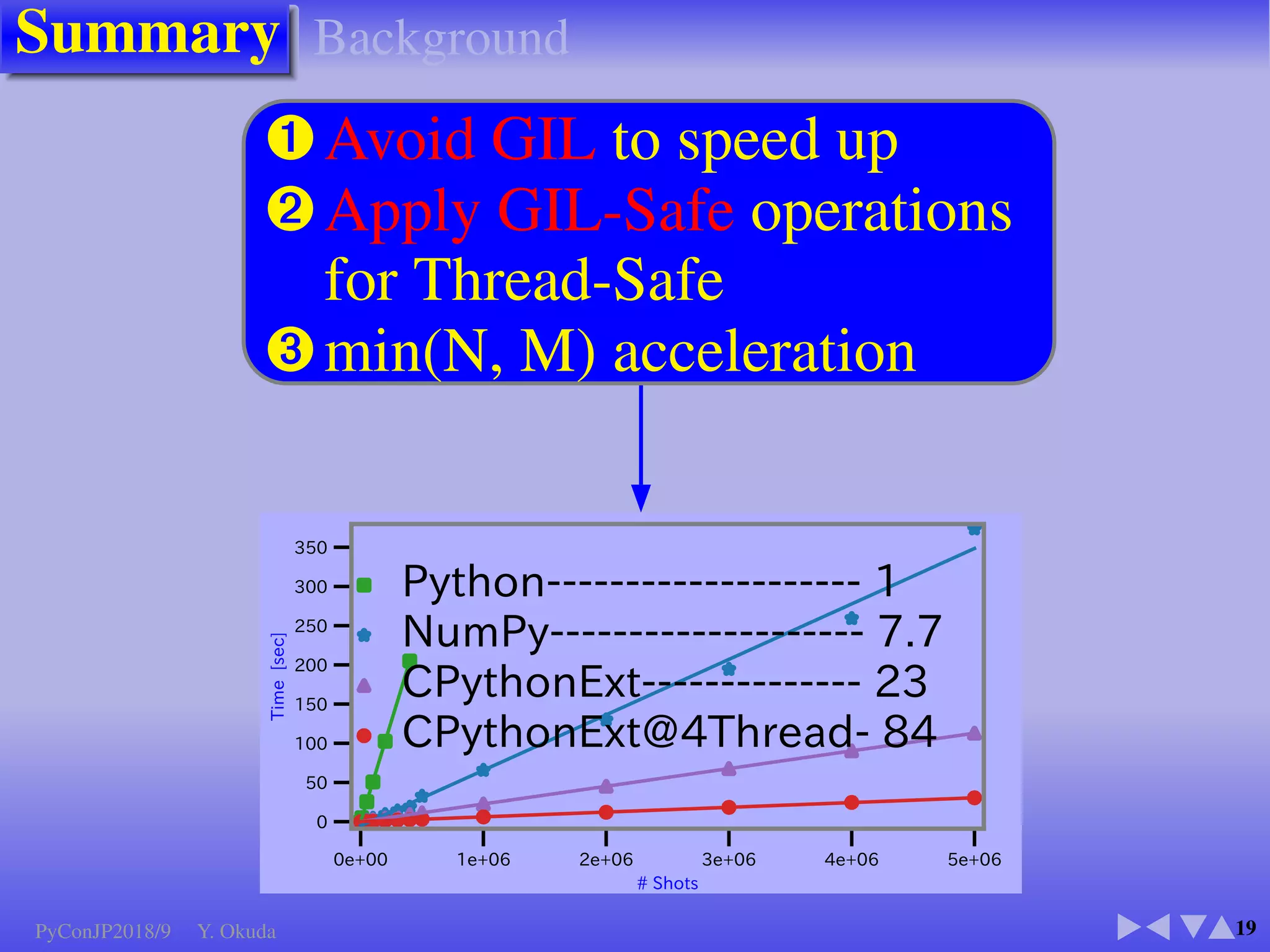
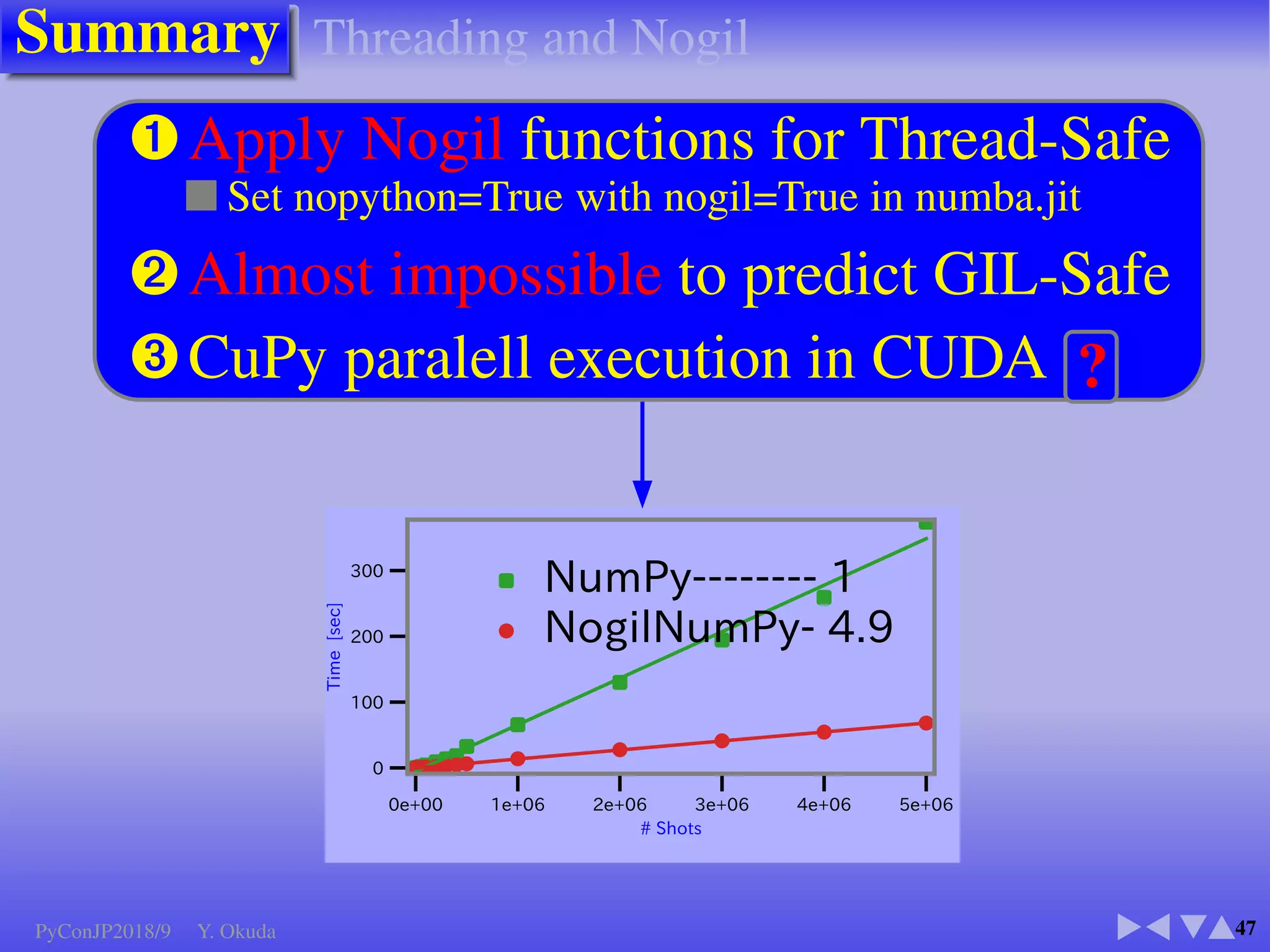
The document discusses techniques to accelerate CPU-bound Python code, focusing on avoiding the Global Interpreter Lock (GIL) using methods such as Cython, Numba, and multi-threading. It highlights various performance comparisons between threads and processes, the importance of thread safety, and includes examples of Monte Carlo simulations for π calculation. Additionally, it emphasizes the benefits of using Numpy for vectorized operations to enhance performance.

![[Sitcon2018] Analysis and Improvement of IOTA PoW Implementation](https://cdn.slidesharecdn.com/ss_thumbnails/sitcon2018analysisandimprovementofiotapowimplementation-180306085230-thumbnail.jpg?width=640&height=640&fit=bounds)