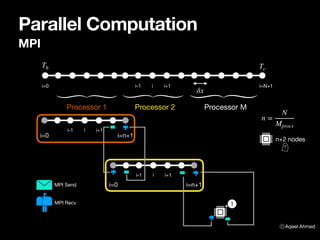
The document provides an introduction to parallel computing in Fortran, focusing on solving a one-dimensional steady-state heat transfer problem through a discretized system of equations. It details the implementation of both direct and iterative methods, specifically using the Jacobi and Gauss-Seidel techniques, along with MPI for parallel computation. A sample Fortran program is included, which demonstrates the structure of the code for implementing the solution with MPI communications and iterative processing of data across multiple processors.



![Single domain
Solution of the System
• Solve directly!
• Or use Jacobi or Gauss Seidel method
• For a given system of linear equations
• The iterative solution is
a11x1 + a12x2 + a13x3 = b1
a21x1 + a22x2 + a23x3 = b2
a31x1 + a32x2 + a33x3 = b3
xnew
1 = xold
1 +
1
a11
[b1 − (a11xold
1 + a12xold
2 + a13xold
3 )]
xnew
2 = xold
2 +
1
a21
[b2 − (a21xold
1 + a22xold
2 + a23xold
3 )]
xnew
3 = xold
3 +
1
a31
[b3 − (a31xold
1 + a32xold
2 + a33xold
3 )]
a11 a12 a13
a21 a22 a23
a31 a32 a33
x1
x2
x3
=
b1
b2
b3
x1 x2 x3](https://image.slidesharecdn.com/mpifortranparallel-240826201322-8e298af7/85/Hands-on-Intro-to-parallel-computing-in-FORTRAN-4-320.jpg)