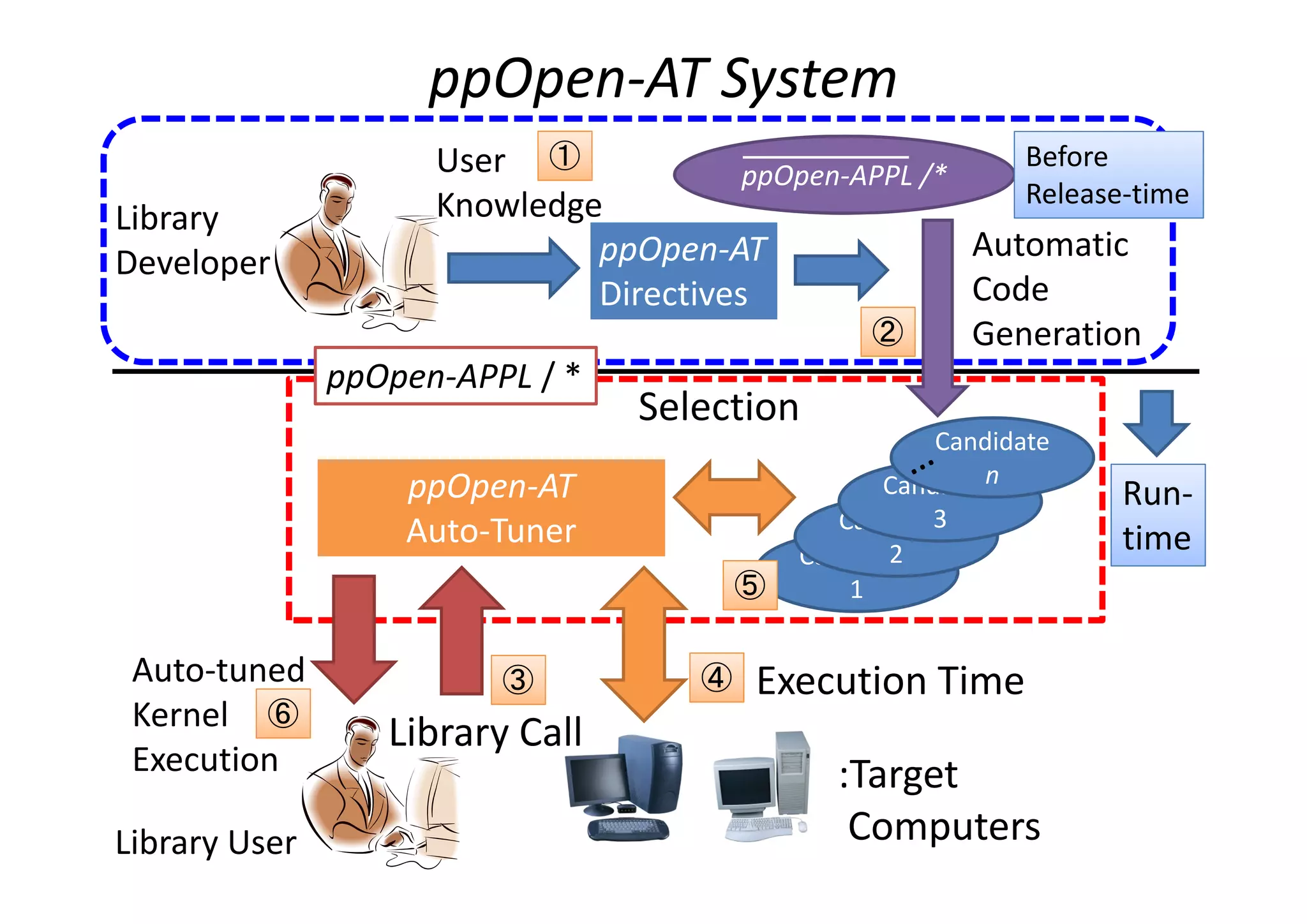
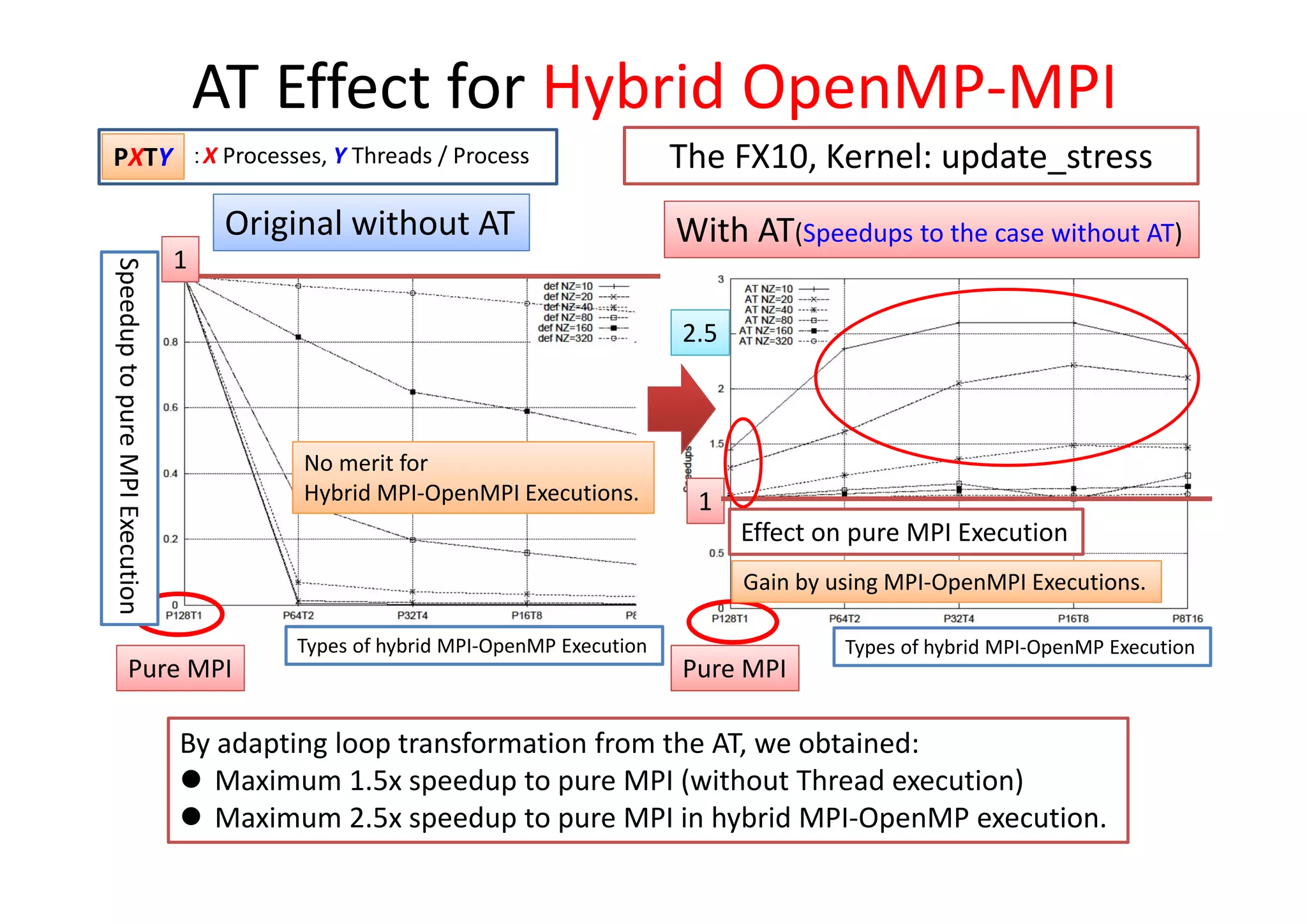
The document discusses the development and challenges of automatic application tuning (AT) for high-performance computing (HPC) architectures, focusing on the ppopen-hpc and ppopen-at projects at the University of Tokyo. Key topics include the need for performance portability across different computer environments, the importance of run-time information, and the adaptation of AT to enhance scientific applications like seismic wave analysis. Future directions emphasize the standardization of AT functions and the establishment of support for supercomputers in operation.












![An Example of Seism_3D Simulation
West part earthquake in Tottori prefecture in Japan
at year 2000. ([1], pp.14)
The region of 820km x 410km x 128 km is discretized with 0.4km.
NX x NY x NZ = 2050 x 1025 x 320 ≒ 6.4 : 3.2 : 1.
[1] T. Furumura, “Large-scale Parallel FDM Simulation for Seismic Waves and Strong Shaking”, Supercomputing News,
Information Technology Center, The University of Tokyo, Vol.11, Special Edition 1, 2009. In Japanese.
Figure : Seismic wave translations in west part earthquake in Tottori prefecture in Japan.
(a) Measured waves; (b) Simulation results; (Reference : [1] in pp.13)](https://image.slidesharecdn.com/dagstuhl2013-t-141226161629-conversion-gate01/75/ppOpen-AT-Yet-Another-Directive-base-AT-Language-14-2048.jpg)


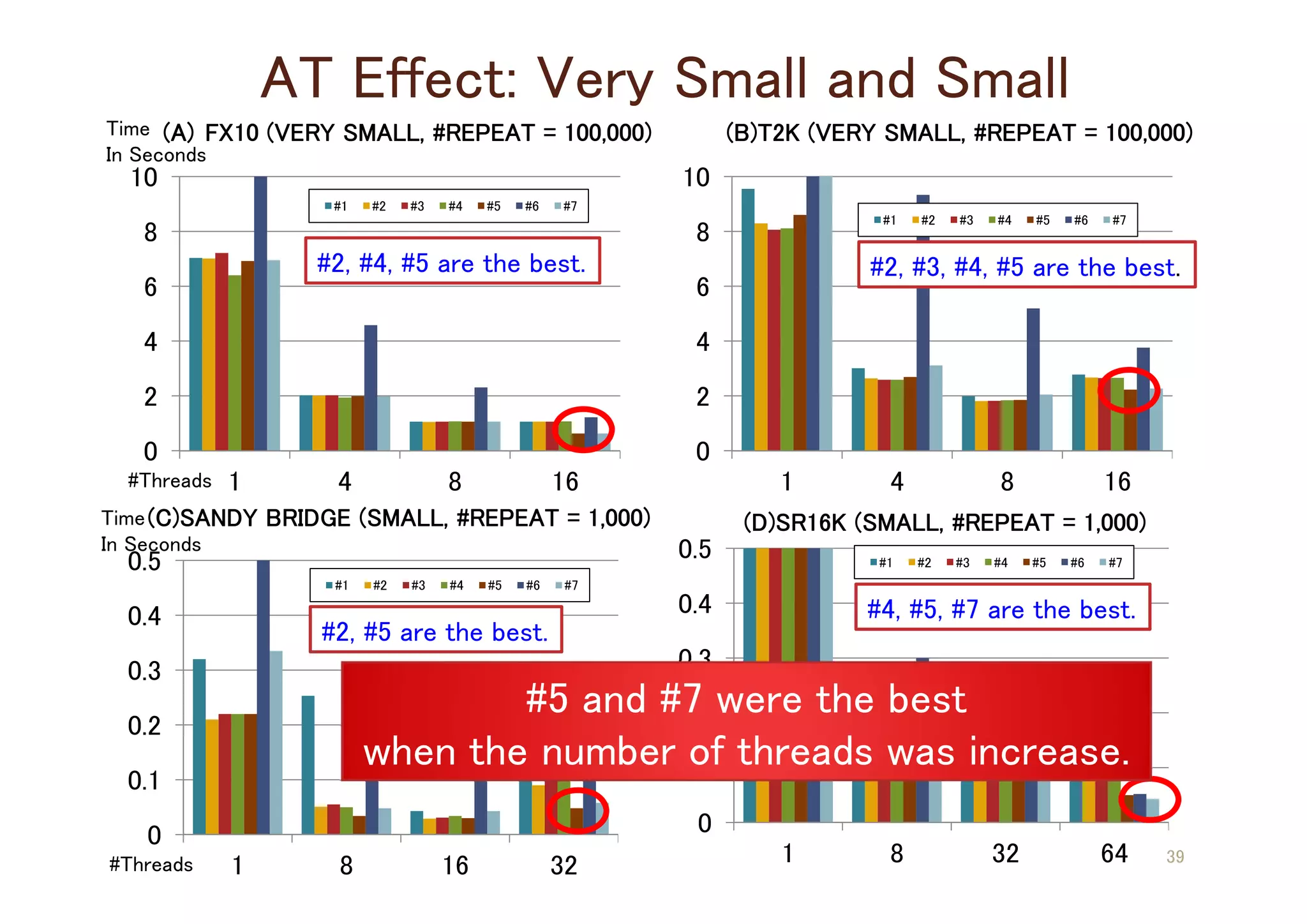
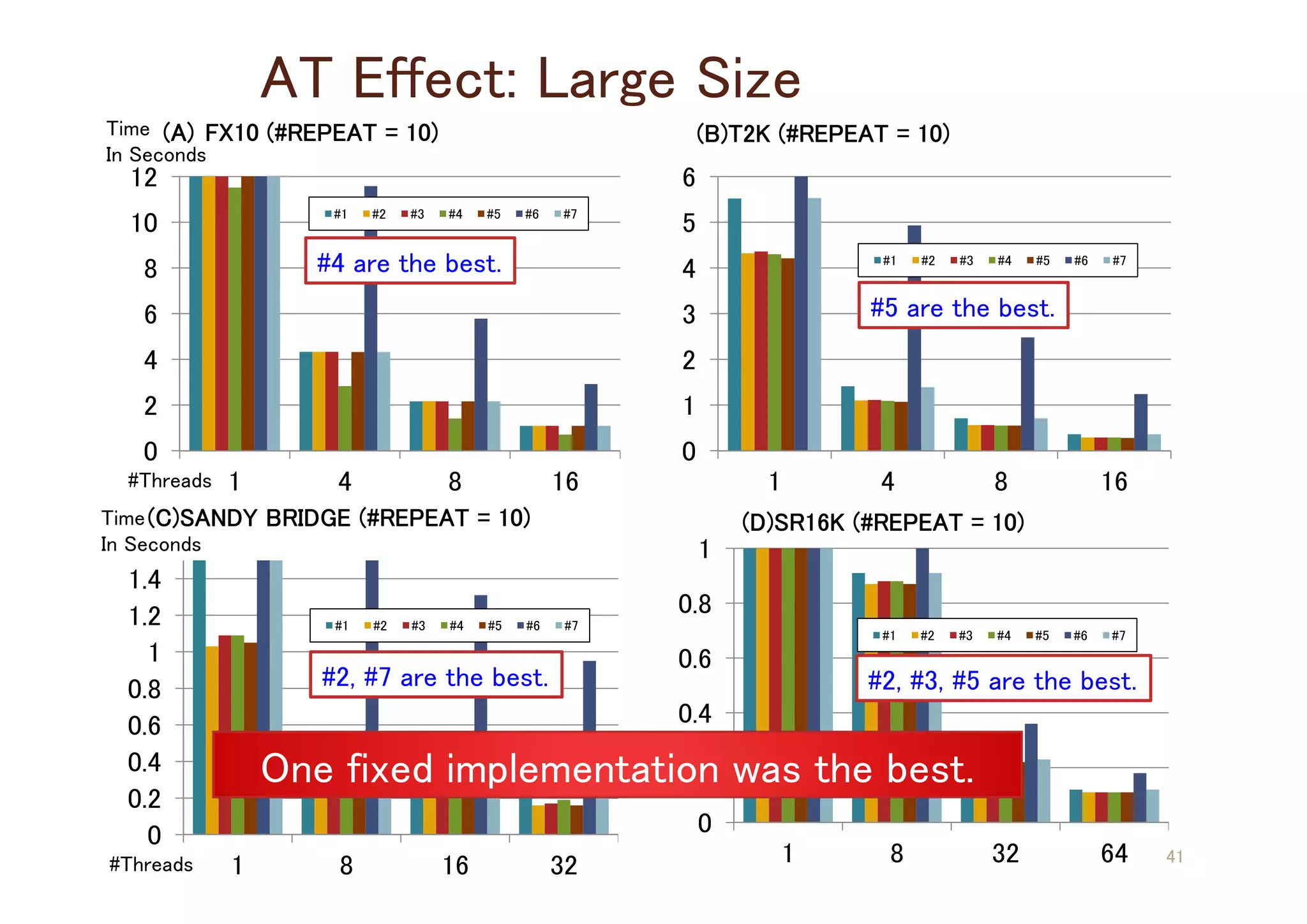
![Candidates of Auto-generated Codes
#1 [Baseline]: Original 3-nested Loop
#2 [Split]: Loop Splitting with I-loop
#3 [Split]: Loop Splitting with J-loop
#4 [Split]: Loop Splitting with K-loop
(Separated, two 3-nested loops)
#5 [Split&Fusion]: Loop Fusion with #2
(2-nested loop)
#6 [Fusion]: Loop Fusion with #1
(loop collapse)
#7 [Fusion]: Loop Fusion with #1
(2-nested loop) 34](https://image.slidesharecdn.com/dagstuhl2013-t-141226161629-conversion-gate01/75/ppOpen-AT-Yet-Another-Directive-base-AT-Language-17-2048.jpg)





































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)














