Recommended
PDF
JavaOne2015報告またはこれからのJava
PDF
これからのコンピューティングとJava(Hacker Tackle)
PDF
これからのコンピューティングの変化とJava-JJUG CCC 2015 Fall
PDF
Javaはどのように動くのか~スライドでわかるJVMの仕組み
PPTX
JEP280: Java 9 で文字列結合の処理が変わるぞ!準備はいいか!? #jjug_ccc
PDF
PPTX
「書ける」から「できる」になれる! ~Javaメモリ節約ノウハウ話~
PDF
Introduction to JShell: the Java REPL Tool #jjug_ccc #ccc_ab4
PDF
ODP
PDF
Kink: invokedynamic on a prototype-based language
PDF
PPTX
PDF
思ったほど怖くない! Haskell on JVM 超入門 #jjug_ccc #ccc_l8
PDF
PDF
Java8 コーディングベストプラクティス and NetBeansのメモリログから...
PPTX
KEY
関東GPGPU勉強会 LLVM meets GPU
PDF
PDF
Synthesijer and Synthesijer.Scala in HLS-friends 201512
PPTX
第六回渋谷Java Java8のJVM監視を考える
PPTX
JJUG CCC 2017 Fall オレオレJVM言語を作ってみる
PPTX
RLSを用いたマルチテナント実装 for Django
PDF
Introduction to JShell #JavaDayTokyo #jdt_jshell
KEY
関ジャバ JavaOne Tokyo 2012報告会
PDF
Synthesijer jjug 201504_01
KEY
JJUG CCC 2012 Real World Groovy/Grails
PDF
PDF
PPTX
More Related Content
PDF
JavaOne2015報告またはこれからのJava
PDF
これからのコンピューティングとJava(Hacker Tackle)
PDF
これからのコンピューティングの変化とJava-JJUG CCC 2015 Fall
PDF
Javaはどのように動くのか~スライドでわかるJVMの仕組み
PPTX
JEP280: Java 9 で文字列結合の処理が変わるぞ!準備はいいか!? #jjug_ccc
PDF
PPTX
「書ける」から「できる」になれる! ~Javaメモリ節約ノウハウ話~
PDF
Introduction to JShell: the Java REPL Tool #jjug_ccc #ccc_ab4
What's hot
PDF
ODP
PDF
Kink: invokedynamic on a prototype-based language
PDF
PPTX
PDF
思ったほど怖くない! Haskell on JVM 超入門 #jjug_ccc #ccc_l8
PDF
PDF
Java8 コーディングベストプラクティス and NetBeansのメモリログから...
PPTX
KEY
関東GPGPU勉強会 LLVM meets GPU
PDF
PDF
Synthesijer and Synthesijer.Scala in HLS-friends 201512
PPTX
第六回渋谷Java Java8のJVM監視を考える
PPTX
JJUG CCC 2017 Fall オレオレJVM言語を作ってみる
PPTX
RLSを用いたマルチテナント実装 for Django
PDF
Introduction to JShell #JavaDayTokyo #jdt_jshell
KEY
関ジャバ JavaOne Tokyo 2012報告会
PDF
Synthesijer jjug 201504_01
KEY
JJUG CCC 2012 Real World Groovy/Grails
PDF
Viewers also liked
PDF
PPTX
PDF
PDF
PDF
NetBeansのメモリ使用ログから機械学習できしだが働いてるかどうか判定する
PDF
Your code sucks, let's fix it - DPC UnCon
PDF
だれも教えてくれないJavaの世界。 あと、ぼくが会社員になったわけ。
PDF
JavaOne2017で感じた、Javaのいまと未来 in 大阪
PDF
PDF
PDF
PDF
PDF
デキるプログラマだけが知っているコードレビュー7つの秘訣
PDF
Similar to コンピューティングとJava~なにわTECH道
PDF
GPUをJavaで使う話(Java Casual Talks #1)
PDF
これからのコンピューティングの変化とこれからのプログラミング at 広島
PPTX
もしも… Javaでヘテロジニアスコアが使えたら…
PDF
PDF
PDF
PPTX
PDF
PDF
PEZY-SC programming overview
PDF
[Basic 7] OS の基本 / 割り込み / システム コール / メモリ管理
PDF
Maxwell と Java CUDAプログラミング
PDF
PDF
Javaヂカラ #Java最新動向 -Java 11 の新機能やOracle Code One 2018 発の最新技術トレンドを一気にキャッチアップ-
PDF
clu2cは64ビットOSでも使えます (OSC 2012 Hiroshima LT用資料)
PDF
PPTX
PDF
PDF
PDF
2011.09.18 v7から始めるunix まとめ
PDF
2011.06.11 v7から始めるunix まとめ
More from なおき きしだ
PDF
GraalVMの紹介とTruffleでPHPぽい言語を実装したら爆速だった話
PDF
PDF
これからのコンピューティングの変化とこれからのプログラミング in 福岡 2018/12/8
PDF
PDF
PDF
PDF
PDF
Java新機能観察日記 - JJUGナイトセミナー
PDF
プログラマになるためになにを勉強するか at 九州学生エンジニアLT大会
PDF
Summary of JDK10 and What will come into JDK11
PDF
Summary of JDK10 and What will come into JDK11
PDF
Java10 and Java11 at JJUG CCC 2018 Spr
PPTX
New thing in JDK10 even that scala-er should know
PPTX
Java Release Model (on Scala Matsuri)
PDF
PPTX
PDF
PPTX
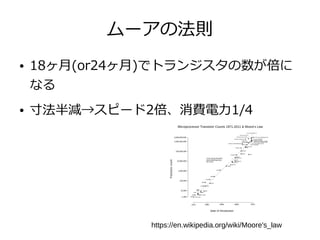
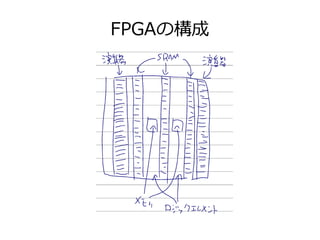
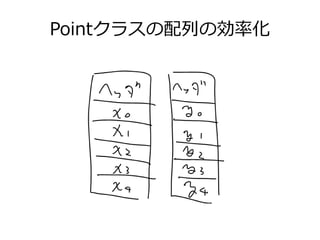
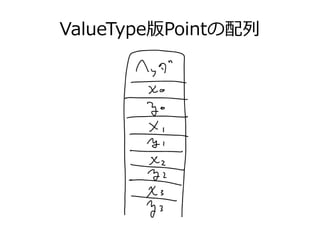
コンピューティングとJava~なにわTECH道 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 23. 24. 25. 26. 27. 28. JavaでCPU(並列)
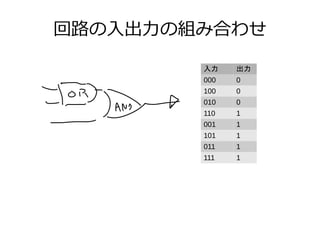
● Java8 Stream
int elementCount = 1_444_477;
float[] inputA = new float[elementCount];
float[] inputB = new float[elementCount];
float[] output = new float[elementCount];
IntStream.range(0, elementCount).parallel().forEach(i -> {
output[i] = inputA[i] * inputB[i];
});
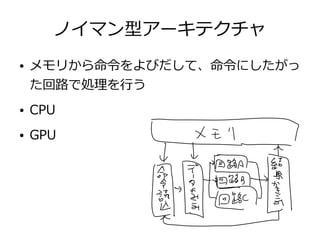
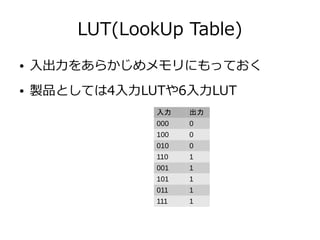
29. 30. 31. Aparapiコード
public class AparapiKernel extends Kernel{
float[] inputA;
float[] inputB;
float[] output;
@Override
public void run() {
int gid = getGlobalId();
output[gid] = inputA[gid] * inputB[gid];
}
public static void main(String[] args) {
AparapiKernel kernel = new AparapiKernel();
int elementCount = 1_444_477;
kernel.inputA = new float[elementCount];
kernel.inputB = new float[elementCount];
kernel.output = new float[elementCount];
fillBuffer(kernel.inputA);
fillBuffer(kernel.inputB);
kernel.execute(elementCount);
}
}
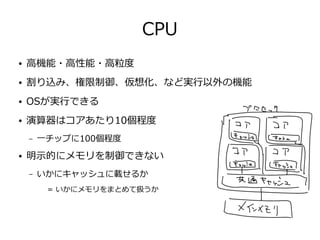
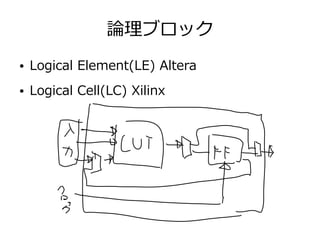
32. 33. JOCLのコード
String KERNEL_CODE =
"kernel void add(global const float* inputA,"
+ " global const float* inputB,"
+ " global float* output,"
+ " uint numElements){"
+ " size_t gid = get_global_id(0);"
+ " if(gid >= numElements){"
+ " return;"
+ " }"
+ " output[gid] = inputA[gid] + inputB[gid];"
+ "}";
CLContext ctx = CLContext.create();
CLDevice device = ctx.getMaxFlopsDevice();
CLCommandQueue queue = device.createCommandQueue();
CLProgram program = ctx.createProgram(KERNEL_CODE).build();
int elementCount = 1_444_477;
int localWorkSize = Math.min(device.getMaxWorkGroupSize(), 256);
int globalWorkSize = ((elementCount + localWorkSize - 1) /
localWorkSize) * localWorkSize;
CLBuffer<FloatBuffer> clBufferA = ctx.createFloatBuffer(
elementCount, CLMemory.Mem.READ_ONLY);
CLBuffer<FloatBuffer> clBufferB = ctx.createFloatBuffer(
elementCount, CLMemory.Mem.READ_ONLY);
CLBuffer<FloatBuffer> clBufferC = ctx.createFloatBuffer(
elementCount, CLMemory.Mem.READ_WRITE);
fillBuffer(clBufferA.getBuffer());
fillBuffer(clBufferB.getBuffer());
CLKernel kernel = program.createCLKernel("add");
kernel
.putArgs(clBufferA, clBufferB, clBufferC)
.putArg(elementCount);
queue.putWriteBuffer(clBufferA, false)
.putWriteBuffer(clBufferB, false)
.put1DRangeKernel(kernel, 0, globalWorkSize, localWorkSize)
.putReadBuffer(clBufferC, true);
34. 35. 36. 37. 38. 39. 40. 41. 42. 43. 44. 45. 46. 47. と思ったら
● 「Sumatra is not in active development for
now.(2015/5/1) 」
http://mail.openjdk.java.net/pipermail/sumatra-dev/2015-May/000310.html
48. 49. 50. Synthesijerが出力したコード
module Test
(
input clk,
input reset,
input flag_in,
input flag_we,
output flag_out,
output run_busy,
input run_req
);
wire clk_sig;
wire reset_sig;
wire flag_in_sig;
wire flag_we_sig;
wire flag_out_sig;
reg run_busy_sig = 1'b1;
wire run_req_sig;
reg class_flag_0000 = 1'b0;
wire class_flag_0000_mux;
wire tmp_0001;
reg signed [32-1 : 0] class_count_0001 = 0;
reg signed [32-1 : 0] unary_expr_00005 = 0;
reg binary_expr_00007 = 1'b0;
reg unary_expr_00011 = 1'b0;
wire run_req_flag;
reg run_req_local = 1'b0;
wire tmp_0002;
localparam run_method_IDLE = 32'd0;
localparam run_method_S_0000 = 32'd1;
localparam run_method_S_0001 = 32'd2;
localparam run_method_S_0002 = 32'd3;
localparam run_method_S_0003 = 32'd4;
localparam run_method_S_0004 = 32'd5;
すごく長い
51. 52. 53. 54. モジュールシステム
● いままでの可視性制御
– public, package private, private
– public見えすぎ問題
● これからの可視性制御
– module export, public, package private, private
● Java自体のモジュール化
– フットプリントの最適化
55. 56. 57. 58. 59. 60. 61. 62. 63. 64. 65. 66. 67. 68. 69. 70. 71. 72. 73. 74. 75. 76. 77. 78. 79. 80. 既存コードは省略形
● iload → vload :I
● daload → vaload :D
– さらにinvokeinterface Array.getElementの略に
できるかも!
81. 82.



















![JavaでCPU(並列)
● Java8 Stream
int elementCount = 1_444_477;
float[] inputA = new float[elementCount];
float[] inputB = new float[elementCount];
float[] output = new float[elementCount];
IntStream.range(0, elementCount).parallel().forEach(i -> {
output[i] = inputA[i] * inputB[i];
});](https://image.slidesharecdn.com/java20160903-160903082521/85/Java-TECH-28-320.jpg)


![Aparapiコード
public class AparapiKernel extends Kernel{
float[] inputA;
float[] inputB;
float[] output;
@Override
public void run() {
int gid = getGlobalId();
output[gid] = inputA[gid] * inputB[gid];
}
public static void main(String[] args) {
AparapiKernel kernel = new AparapiKernel();
int elementCount = 1_444_477;
kernel.inputA = new float[elementCount];
kernel.inputB = new float[elementCount];
kernel.output = new float[elementCount];
fillBuffer(kernel.inputA);
fillBuffer(kernel.inputB);
kernel.execute(elementCount);
}
}](https://image.slidesharecdn.com/java20160903-160903082521/85/Java-TECH-31-320.jpg)

![JOCLのコード
String KERNEL_CODE =
"kernel void add(global const float* inputA,"
+ " global const float* inputB,"
+ " global float* output,"
+ " uint numElements){"
+ " size_t gid = get_global_id(0);"
+ " if(gid >= numElements){"
+ " return;"
+ " }"
+ " output[gid] = inputA[gid] + inputB[gid];"
+ "}";
CLContext ctx = CLContext.create();
CLDevice device = ctx.getMaxFlopsDevice();
CLCommandQueue queue = device.createCommandQueue();
CLProgram program = ctx.createProgram(KERNEL_CODE).build();
int elementCount = 1_444_477;
int localWorkSize = Math.min(device.getMaxWorkGroupSize(), 256);
int globalWorkSize = ((elementCount + localWorkSize - 1) /
localWorkSize) * localWorkSize;
CLBuffer<FloatBuffer> clBufferA = ctx.createFloatBuffer(
elementCount, CLMemory.Mem.READ_ONLY);
CLBuffer<FloatBuffer> clBufferB = ctx.createFloatBuffer(
elementCount, CLMemory.Mem.READ_ONLY);
CLBuffer<FloatBuffer> clBufferC = ctx.createFloatBuffer(
elementCount, CLMemory.Mem.READ_WRITE);
fillBuffer(clBufferA.getBuffer());
fillBuffer(clBufferB.getBuffer());
CLKernel kernel = program.createCLKernel("add");
kernel
.putArgs(clBufferA, clBufferB, clBufferC)
.putArg(elementCount);
queue.putWriteBuffer(clBufferA, false)
.putWriteBuffer(clBufferB, false)
.put1DRangeKernel(kernel, 0, globalWorkSize, localWorkSize)
.putReadBuffer(clBufferC, true);](https://image.slidesharecdn.com/java20160903-160903082521/85/Java-TECH-33-320.jpg)















![Synthesijerが出力したコード
module Test
(
input clk,
input reset,
input flag_in,
input flag_we,
output flag_out,
output run_busy,
input run_req
);
wire clk_sig;
wire reset_sig;
wire flag_in_sig;
wire flag_we_sig;
wire flag_out_sig;
reg run_busy_sig = 1'b1;
wire run_req_sig;
reg class_flag_0000 = 1'b0;
wire class_flag_0000_mux;
wire tmp_0001;
reg signed [32-1 : 0] class_count_0001 = 0;
reg signed [32-1 : 0] unary_expr_00005 = 0;
reg binary_expr_00007 = 1'b0;
reg unary_expr_00011 = 1'b0;
wire run_req_flag;
reg run_req_local = 1'b0;
wire tmp_0002;
localparam run_method_IDLE = 32'd0;
localparam run_method_S_0000 = 32'd1;
localparam run_method_S_0001 = 32'd2;
localparam run_method_S_0002 = 32'd3;
localparam run_method_S_0003 = 32'd4;
localparam run_method_S_0004 = 32'd5;
すごく長い](https://image.slidesharecdn.com/java20160903-160903082521/85/Java-TECH-50-320.jpg)















































































![[Basic 7] OS の基本 / 割り込み / システム コール / メモリ管理](https://cdn.slidesharecdn.com/ss_thumbnails/basic-07-180228134341-thumbnail.jpg?width=640&height=640&fit=bounds)



























