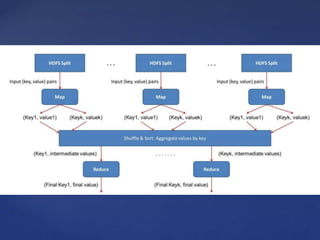
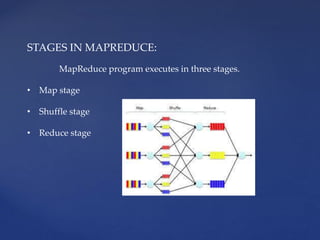
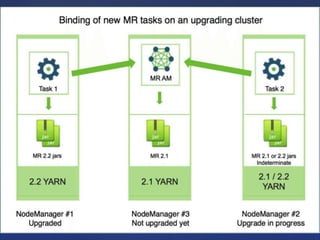
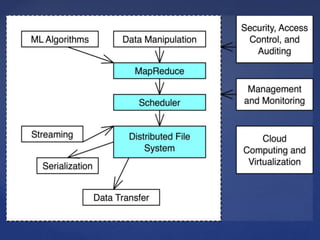
The document outlines the Hadoop, MapReduce, and YARN frameworks, emphasizing how MapReduce processes large datasets in parallel through its map and reduce stages. It details the execution of MapReduce programs in three phases: map, shuffle, and reduce, and explains YARN's role in resource management and application integration. Additionally, it covers serialization and deserialization processes for data transport and storage.