Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Shinya Okano
1,910 views
Hadoopとその周辺の紹介
Technology
◦
Read more
2
Save
Share
Embed
Embed presentation
Download
Downloaded 11 times
1
/ 21
2
/ 21
3
/ 21
4
/ 21
5
/ 21
6
/ 21
7
/ 21
8
/ 21
9
/ 21
10
/ 21
11
/ 21
12
/ 21
13
/ 21
14
/ 21
15
/ 21
16
/ 21
17
/ 21
18
/ 21
19
/ 21
20
/ 21
21
/ 21
More Related Content
PPTX
Hadoop
by
Atsushi Shimura
PPT
Hadoopの紹介
by
bigt23
PPTX
ATN No.1 MapReduceだけでない!? Hadoopとその仲間たち
by
AdvancedTechNight
PDF
オライリーセミナー Hive入門 #oreilly0724
by
Cloudera Japan
PDF
MapReduceプログラミング入門
by
Satoshi Noto
PDF
Hadoop入門
by
Preferred Networks
PDF
ただいまHadoop勉強中
by
Satoshi Noto
PPTX
Hdfsソースコードリーディング第2回
by
shunsuke Mikami
Hadoop
by
Atsushi Shimura
Hadoopの紹介
by
bigt23
ATN No.1 MapReduceだけでない!? Hadoopとその仲間たち
by
AdvancedTechNight
オライリーセミナー Hive入門 #oreilly0724
by
Cloudera Japan
MapReduceプログラミング入門
by
Satoshi Noto
Hadoop入門
by
Preferred Networks
ただいまHadoop勉強中
by
Satoshi Noto
Hdfsソースコードリーディング第2回
by
shunsuke Mikami
What's hot
PPTX
Hdfsソースコードリーディング第一回
by
shunsuke Mikami
PDF
MapReduce入門
by
Satoshi Noto
PDF
レッドハット グラスター ストレージ Red Hat Gluster Storage (Japanese)
by
Katsutoshi Kojima
PDF
コード読経会報告書
by
Masahiko Toyoshi
PDF
Hadoopことはじめ
by
均 津田
PDF
Hadoop 基礎
by
hideaki honda
PDF
Hadoopのシステム設計・運用のポイント
by
Cloudera Japan
PDF
Quick Introduction to GlusterFS
by
Etsuji Nakai
PDF
分散処理のすゝめ?
by
y oe
PDF
JavaOne2013報告会 LT資料 Hadoopの話を聞いてきた
by
Takashi Aoe
PPTX
データベース入門
by
拓 小林
PDF
Drill超簡単チューニング
by
MapR Technologies Japan
PDF
MapReduce解説
by
Shunsuke Aihara
PDF
Hadoop / MapReduce とは
by
Takeshi Matsuoka
PDF
Learning spaerk chapter03
by
Akimitsu Takagi
PPTX
SASとHadoopとの連携
by
SAS Institute Japan
PPT
はやわかりHadoop
by
Shinpei Ohtani
PDF
HDFS新機能総まとめin 2015 (日本Hadoopユーザー会 ライトニングトーク@Cloudera World Tokyo 2015 講演資料)
by
NTT DATA OSS Professional Services
PPTX
Apache Spark チュートリアル
by
K Yamaguchi
PDF
Dat009 クラウドでビック
by
Tech Summit 2016
Hdfsソースコードリーディング第一回
by
shunsuke Mikami
MapReduce入門
by
Satoshi Noto
レッドハット グラスター ストレージ Red Hat Gluster Storage (Japanese)
by
Katsutoshi Kojima
コード読経会報告書
by
Masahiko Toyoshi
Hadoopことはじめ
by
均 津田
Hadoop 基礎
by
hideaki honda
Hadoopのシステム設計・運用のポイント
by
Cloudera Japan
Quick Introduction to GlusterFS
by
Etsuji Nakai
分散処理のすゝめ?
by
y oe
JavaOne2013報告会 LT資料 Hadoopの話を聞いてきた
by
Takashi Aoe
データベース入門
by
拓 小林
Drill超簡単チューニング
by
MapR Technologies Japan
MapReduce解説
by
Shunsuke Aihara
Hadoop / MapReduce とは
by
Takeshi Matsuoka
Learning spaerk chapter03
by
Akimitsu Takagi
SASとHadoopとの連携
by
SAS Institute Japan
はやわかりHadoop
by
Shinpei Ohtani
HDFS新機能総まとめin 2015 (日本Hadoopユーザー会 ライトニングトーク@Cloudera World Tokyo 2015 講演資料)
by
NTT DATA OSS Professional Services
Apache Spark チュートリアル
by
K Yamaguchi
Dat009 クラウドでビック
by
Tech Summit 2016
Similar to Hadoopとその周辺の紹介
PDF
Hadoop_startup
by
Yusuke Shimizu
PPT
Hadoop ~Yahoo! JAPANの活用について~
by
Yahoo!デベロッパーネットワーク
PDF
【17-E-3】Hadoop:黄色い象使いへの道 ~「Hadoop徹底入門」より~
by
Developers Summit
PDF
40分でわかるHadoop徹底入門 (Cloudera World Tokyo 2014 講演資料)
by
hamaken
PPT
Googleの基盤クローン Hadoopについて
by
Kazuki Ohta
PDF
Hadoop Compatible File Systems 2019 (db tech showcase 2019 Tokyo講演資料、2019/09/25)
by
NTT DATA Technology & Innovation
PDF
分散処理基盤ApacheHadoop入門とHadoopエコシステムの最新技術動向(OSC2015 Kansai発表資料)
by
NTT DATA OSS Professional Services
PDF
Hadoopエコシステムのデータストア振り返り
by
NTT DATA OSS Professional Services
PDF
Hadoop ecosystem NTTDATA osc15tk
by
NTT DATA OSS Professional Services
PDF
分散処理基盤Apache Hadoop入門とHadoopエコシステムの最新技術動向 (オープンソースカンファレンス 2015 Tokyo/Spring 講...
by
NTT DATA OSS Professional Services
PPT
Hadoop~Yahoo! JAPANの活用について~
by
Yahoo!デベロッパーネットワーク
PDF
Apache Hadoop & Hive 入門 (マーケティングデータ分析基盤技術勉強会)
by
Takeshi Mikami
PDF
OSC2012 Tokyo/Spring - Hadoop入門
by
Shinichi YAMASHITA
PDF
分散処理基盤Apache Hadoopの現状と、NTTデータのHadoopに対する取り組み
by
NTT DATA OSS Professional Services
PDF
Data-Intensive Text Processing with MapReduce(Ch1,Ch2)
by
Sho Shimauchi
PDF
Apache Hadoop HDFSの最新機能の紹介(2018)#dbts2018
by
Yahoo!デベロッパーネットワーク
PDF
ストリームデータ分散処理基盤Storm
by
NTT DATA OSS Professional Services
PDF
Hadoopによる大規模分散データ処理
by
Yoji Kiyota
PPTX
BigtopでHadoopをビルドする(Open Source Conference 2021 Online/Spring 発表資料)
by
NTT DATA Technology & Innovation
PPT
Hadoop~Yahoo!Japanの活用について
by
kaminashi
Hadoop_startup
by
Yusuke Shimizu
Hadoop ~Yahoo! JAPANの活用について~
by
Yahoo!デベロッパーネットワーク
【17-E-3】Hadoop:黄色い象使いへの道 ~「Hadoop徹底入門」より~
by
Developers Summit
40分でわかるHadoop徹底入門 (Cloudera World Tokyo 2014 講演資料)
by
hamaken
Googleの基盤クローン Hadoopについて
by
Kazuki Ohta
Hadoop Compatible File Systems 2019 (db tech showcase 2019 Tokyo講演資料、2019/09/25)
by
NTT DATA Technology & Innovation
分散処理基盤ApacheHadoop入門とHadoopエコシステムの最新技術動向(OSC2015 Kansai発表資料)
by
NTT DATA OSS Professional Services
Hadoopエコシステムのデータストア振り返り
by
NTT DATA OSS Professional Services
Hadoop ecosystem NTTDATA osc15tk
by
NTT DATA OSS Professional Services
分散処理基盤Apache Hadoop入門とHadoopエコシステムの最新技術動向 (オープンソースカンファレンス 2015 Tokyo/Spring 講...
by
NTT DATA OSS Professional Services
Hadoop~Yahoo! JAPANの活用について~
by
Yahoo!デベロッパーネットワーク
Apache Hadoop & Hive 入門 (マーケティングデータ分析基盤技術勉強会)
by
Takeshi Mikami
OSC2012 Tokyo/Spring - Hadoop入門
by
Shinichi YAMASHITA
分散処理基盤Apache Hadoopの現状と、NTTデータのHadoopに対する取り組み
by
NTT DATA OSS Professional Services
Data-Intensive Text Processing with MapReduce(Ch1,Ch2)
by
Sho Shimauchi
Apache Hadoop HDFSの最新機能の紹介(2018)#dbts2018
by
Yahoo!デベロッパーネットワーク
ストリームデータ分散処理基盤Storm
by
NTT DATA OSS Professional Services
Hadoopによる大規模分散データ処理
by
Yoji Kiyota
BigtopでHadoopをビルドする(Open Source Conference 2021 Online/Spring 発表資料)
by
NTT DATA Technology & Innovation
Hadoop~Yahoo!Japanの活用について
by
kaminashi
More from Shinya Okano
PDF
Djangoエンジニアの観点から見たHue
by
Shinya Okano
PDF
Djangoフレームワークのユーザーモデルと認証
by
Shinya Okano
PDF
Djangoフレームワークの紹介
by
Shinya Okano
PDF
Pyconjp2016 pyftplib
by
Shinya Okano
PDF
Python入門 コードリーディング - PyConJP2016
by
Shinya Okano
PDF
Djangoフレームワークの紹介
by
Shinya Okano
PDF
Djangoのエントリポイントとアプリケーションの仕組み
by
Shinya Okano
PDF
Djangoフレームワークの紹介 OSC2015北海道
by
Shinya Okano
PPTX
Python札幌201406
by
Shinya Okano
PPTX
Spring4Dの紹介
by
Shinya Okano
ODP
Delphi ideを使わない開発スタイルの紹介
by
Shinya Okano
PDF
2011.06.01 和歌山高専
by
Shinya Okano
PDF
電子書籍の話
by
Shinya Okano
PDF
写真共有アプリのバックエンドサーバー
by
Shinya Okano
PDF
Python札幌 2012/06/17
by
Shinya Okano
PDF
XenServerによるお手軽開発サーバ運用
by
Shinya Okano
PDF
mixiアプリ『the Actress』運用にあたっての課題へのチャレンジ
by
Shinya Okano
Djangoエンジニアの観点から見たHue
by
Shinya Okano
Djangoフレームワークのユーザーモデルと認証
by
Shinya Okano
Djangoフレームワークの紹介
by
Shinya Okano
Pyconjp2016 pyftplib
by
Shinya Okano
Python入門 コードリーディング - PyConJP2016
by
Shinya Okano
Djangoフレームワークの紹介
by
Shinya Okano
Djangoのエントリポイントとアプリケーションの仕組み
by
Shinya Okano
Djangoフレームワークの紹介 OSC2015北海道
by
Shinya Okano
Python札幌201406
by
Shinya Okano
Spring4Dの紹介
by
Shinya Okano
Delphi ideを使わない開発スタイルの紹介
by
Shinya Okano
2011.06.01 和歌山高専
by
Shinya Okano
電子書籍の話
by
Shinya Okano
写真共有アプリのバックエンドサーバー
by
Shinya Okano
Python札幌 2012/06/17
by
Shinya Okano
XenServerによるお手軽開発サーバ運用
by
Shinya Okano
mixiアプリ『the Actress』運用にあたっての課題へのチャレンジ
by
Shinya Okano
Recently uploaded
PDF
Team Topology Adaptive Organizational Design for Rapid Delivery of Valuable S...
by
akipii ogaoga
PDF
ST2024_PM1_2_Case_study_of_local_newspaper_company.pdf
by
akipii ogaoga
PDF
TomokaEdakawa_職種と講義の関係推定に基づく履修支援システムの基礎検討_HCI2026
by
Matsushita Laboratory
PDF
maisugimoto_曖昧さを含む仕様書の改善を目的としたアノテーション支援ツールの検討_HCI2025.pdf
by
Matsushita Laboratory
PDF
アジャイル導入が止まる3つの壁 ─ 文化・他部門・組織プロセスをどう乗り越えるか
by
Graat(グラーツ)
PDF
自転車ユーザ参加型路面画像センシングによる点字ブロック検出における性能向上方法の模索 (20260123 SeMI研)
by
Yuto Matsuda
PDF
20260119_VIoTLT_vol22_kitazaki_v1___.pdf
by
Ayachika Kitazaki
Team Topology Adaptive Organizational Design for Rapid Delivery of Valuable S...
by
akipii ogaoga
ST2024_PM1_2_Case_study_of_local_newspaper_company.pdf
by
akipii ogaoga
TomokaEdakawa_職種と講義の関係推定に基づく履修支援システムの基礎検討_HCI2026
by
Matsushita Laboratory
maisugimoto_曖昧さを含む仕様書の改善を目的としたアノテーション支援ツールの検討_HCI2025.pdf
by
Matsushita Laboratory
アジャイル導入が止まる3つの壁 ─ 文化・他部門・組織プロセスをどう乗り越えるか
by
Graat(グラーツ)
自転車ユーザ参加型路面画像センシングによる点字ブロック検出における性能向上方法の模索 (20260123 SeMI研)
by
Yuto Matsuda
20260119_VIoTLT_vol22_kitazaki_v1___.pdf
by
Ayachika Kitazaki
Hadoopとその周辺の紹介
1.
Hadoopとその周辺の紹介 BPStyle #41 tokibito
2.
Apache Hadoopとは ● 分散処理基盤 ○
HDFS - 分散ファイルシステム ○ MapReduce - 分散処理フレームワーク ● Apache財団のプロジェクト ● Javaで作られている ● http://hadoop.apache.org/
3.
HDFSとは ● 分散ファイルシステムのサービス ● Unixのファイルシステムのように、ディレクトリや パーミッション、所有者の概念がある ●
大きく分けて2つのコンポーネントで構成 ○ NameNode - 各ファイルのメタ情報を管理 ○ DataNode - 実データを持つ
4.
NameNodeとDataNodeのイメージ NameNode DataNode DataNode DataNode HDD HDD HDD NameNodeが1台でDataNodeが複数台
5.
HDFSの操作 $ hdfs dfs
-ls /user/tokibito Found 3 items drwx------ tokibito tokibito 0 drwxrwxrwx - tokibito tokibito 0 -rw-r--r-3 tokibito tokibito 419 $ hdfs dfs -put test.txt /user/tokibito/ $ hdfs dfs -ls /user/tokibito/ Found 4 items drwx------ tokibito tokibito 0 drwxrwxrwx - tokibito tokibito 0 -rw-r--r-3 tokibito tokibito 419 -rw-r--r-3 tokibito tokibito 5 $ hdfs dfs -cat /user/tokibito/test.txt hoge hdfs dfsコマンドを使ってファイルを操作できる put get mv rm ls mkdirなどのサブコマンドがある 2013-12-06 09:00 /user/tokibito/.Trash 2013-12-04 18:18 /user/tokibito/tab1 2013-12-06 15:34 /user/tokibito/test.tsv 2013-12-06 2013-12-04 2013-12-06 2014-01-08 09:00 18:18 15:34 11:18 /user/tokibito/.Trash /user/tokibito/tab1 /user/tokibito/test.tsv /user/tokibito/test.txt
6.
MapReduceとは ● 分散処理フレームワーク ● 大きく分けて2つのコンポーネントで構成 ○
JobTracker ○ TaskTracker ● ジョブ(Job) ○ Map処理とReduce処理の組み合わせ ■ org.apache.hadoop.mapreduce.Mapper ● 分割された入力データを並列処理 ■ org.apache.hadoop.mapreduce.Reducer ● Mapperの処理結果を一つにまとめる ○ jarパッケージにしてJobTrackerに登録する
7.
JobTrackerとTaskTrackerのイメージ JobTracker TaskTracker TaskTracker JobTrackerが1台でTaskTrackerが複数台 TaskTrackerでMap/Reduce処理が実行される TaskTracker
8.
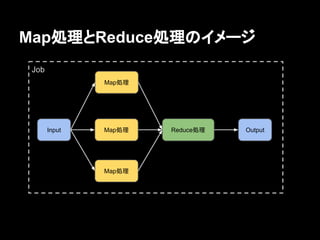
Map処理とReduce処理のイメージ Job Map処理 Input Map処理 Map処理 Reduce処理 Output
9.
MapReduceを使うのは面倒くさい ● Javaで処理を書く必要がある ● jarを作ってJobTrackerに登録しないといけない ●
SQL使いたい →そこでApache Hive
10.
Apache Hive ● Hadoop上のクエリエンジン ●
SQLで問い合わせ ○ SQLからMapReduceタスクを生成して実行 ● Javaで実装されている ● http://hive.apache.org/
11.
Hiveの操作 hiveコマンドで対話シェルを起動する hive> show databases; OK default tokibito Time
taken: 2.379 seconds hive> use tokibito; OK Time taken: 0.047 seconds hive> show tables; OK tab1 Time taken: 0.143 seconds hive> select * from tab1; OK 7 NULL 1 NULL 1 foo 2 hoge 3 bar 4 5 NULL Time taken: 1.971 seconds
12.
Hiveは遅い? ● 小さなデータに対してクエリした場合でも数十秒 かかったりすることがある ○ HDFSへのアクセスのオーバーヘッドが大きい ○
MapReduce処理が遅い →そこでCloudera Impala
13.
Cloudera Impala ● Hadoop上のクエリエンジン ●
SQLで問い合わせ ○ ImpalaDaemonがSQLをコンパイルして実行(LLVM) ● MapReduce処理の最適化 ○ Impaladのノードと同じマシンのDataNodeを直接参照 ■ ネットワーク転送のオーバーヘッド軽減 ● C++で実装 ● Hiveのメタ情報を利用 ○ hiveのテーブルを参照できる ● 現状ではHiveの全機能はカバーできてない ● http://impala.io/
14.
Impalaの操作 impala-shellコマンドで対話シェルを起動する [slave1:21000] > use
tokibito; Query: use tokibito [slave1:21000] > select * from tab1; Query: select * from tab1 Query finished, fetching results ... +----+-------+ | id | col_1 | +----+-------+ | 7 | NULL | | 1 | foo | | 2 | hoge | | 3 | bar | | 4 | | | 5 | NULL | | 1 | NULL | +----+-------+ Returned 7 row(s) in 2.46s
15.
他のHadoop関連のプロダクト ● ● ● ● Apache HBase -
KVS Apache Flume - ログ収集 Apache Oozie - ワークフローエンジン Cloudera Hue - Hadoopのフロントエンド など
16.
Hadoopは大変 ● コンポーネントの数が多い ● 依存関係の解決が面倒(バージョンも気にする 必要ある) ●
複数台のサーバー管理が必要(HA構成なら最 低でも7〜11台以上) →そこでCDHとCloudera Manager
17.
CDH ● Cloudera's Distribution
Including Apache Hadoop ● 米Cloudera社 ● Hadoopのパッケージ ○ rpm ○ 依存関係が解決されている ○ 安定したバージョンのパッケージ ● http://www.cloudera. com/content/cloudera/en/products-andservices/cdh.html
18.
Cloudera Manager ● Hadoopクラスタの管理ツール ●
Webベース ● ホストの管理 ○ 対象の各ホストにagentをインストールする ● ホストへのCDHのインストール ○ 一括で自動インストール可能 ● サービスの管理 ○ どのホストでどのサービスを動かすかをWebUIから一括 設定可能 ● http://www.cloudera. com/content/cloudera/en/products-and-
19.
Hadoopの利点は? ● 一台で処理できないような量のデータを扱える ○ MapReduce ●
一台で保存できないような量のデータを扱える ○ HDFS ○ 容量が足りなければ台数を増やせばよい ○ 台数を増やせばパフォーマンスも上がる ● メモリに載り切らないようなデータを現実的な時 間で処理できる ● 正規化されていないデータを処理できる
20.
Hadoopの欠点は? ● 速くはない ○ メモリに乗る程度のデータ量ならRDBMSを使ったほう がかなり速い ●
推奨マシンスペックは低くない ○ Impalaの推奨メモリは128GB以上 ■ コモディティサーバー≠安価なサーバー ○ 最低でも1ノードあたり4〜8GB程度ないと、まともに動 かない ● 最小構成のサーバー台数が多い ○ HA構成ならマスター3台、スレーブ4〜8台以上 ● コンポーネント数が多く、複雑なのでトラブル シューティングは大変
21.
http://www.slideshare.net/Cloudera_jp/cloudera-manager-5-hadoop-cwt2013
Download













![Impalaの操作
impala-shellコマンドで対話シェルを起動する
[slave1:21000] > use tokibito;
Query: use tokibito
[slave1:21000] > select * from tab1;
Query: select * from tab1
Query finished, fetching results ...
+----+-------+
| id | col_1 |
+----+-------+
| 7 | NULL |
| 1 | foo
|
| 2 | hoge |
| 3 | bar
|
| 4 |
|
| 5 | NULL |
| 1 | NULL |
+----+-------+
Returned 7 row(s) in 2.46s](https://image.slidesharecdn.com/hadoop-140108100729-phpapp02/85/Hadoop-14-320.jpg)














































































