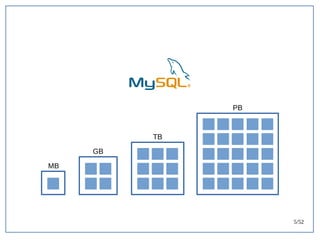
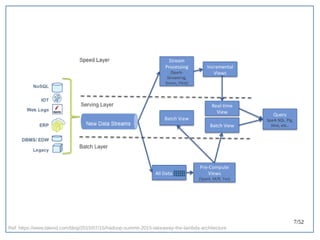
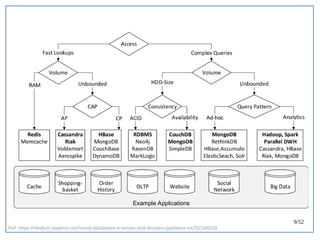
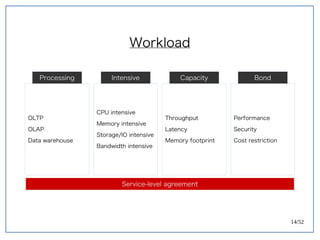
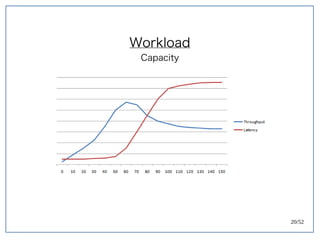
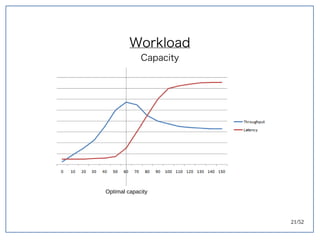
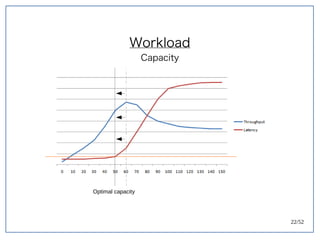
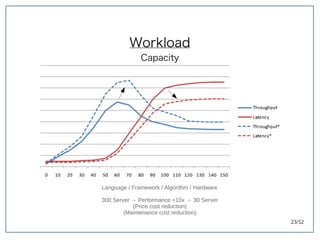
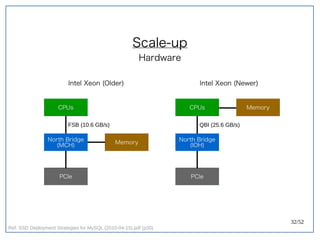
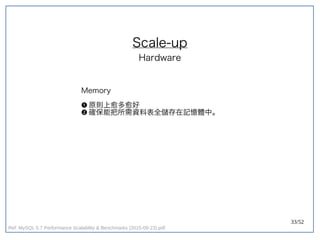
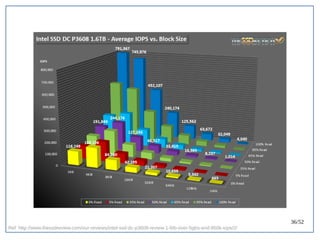
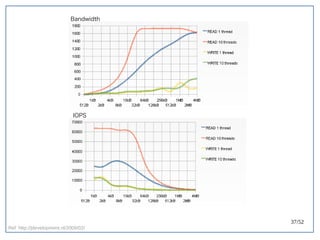
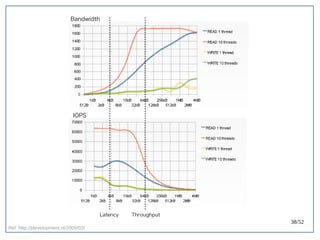
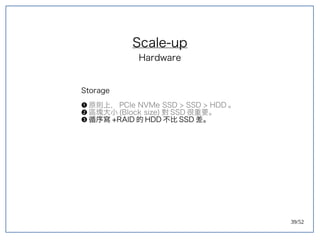
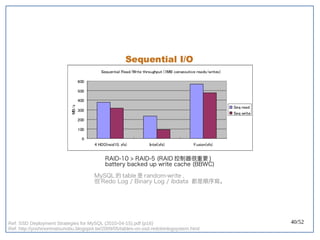
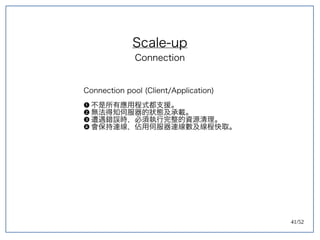
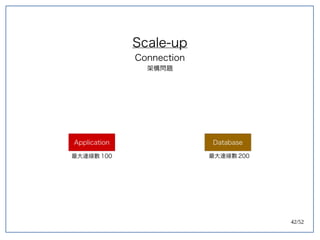
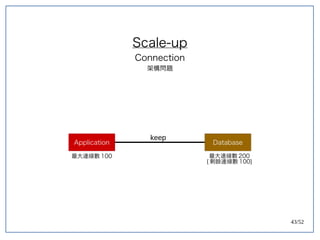
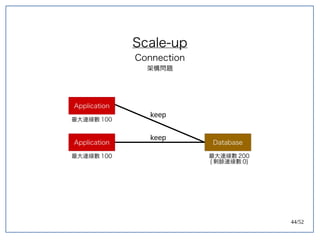
该文档探讨了在大数据架构中使用关系数据库管理系统(RDBMS)和新SQL(NewSQL)的重要性,强调优化数据和系统架构的重要性。提出了在各种工作负载(在线交易处理和在线分析处理)中应对不同要求的策略,以及如何在技术层面实现更好的性能和安全性。最后,文章着眼于数据库连接、应用性能和存储优化的关键因素。

































![恰如其分的 MySQL 設計技巧 [Modern Web 2016]](https://cdn.slidesharecdn.com/ss_thumbnails/2016-08-24modernweb-mysql-161019062706-thumbnail.jpg?width=640&height=640&fit=bounds)



































![[BizLePro] 主題講座 #5:台灣C2C第三方支付服務之發展_20130513_gillight](https://cdn.slidesharecdn.com/ss_thumbnails/c2c-130515050736-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BizLePro] 主題講座 #4:給資訊人的智財導論_20130429_richard](https://cdn.slidesharecdn.com/ss_thumbnails/bizlepro20130429richard-130430014156-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BizLePro] 主題講座 #7:商業利用怎麼行? - 從開源授權十個常見 FAQ 來了解](https://cdn.slidesharecdn.com/ss_thumbnails/20130610-130610200023-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)













































