为什么选择 Hadoop ?Need to process huge datasets on large clusters of computers Very expensive to build reliability into each application. Nodes fail every day f ailure is expected, rather than exceptional. The number of nodes in a cluster is not constant. Need common infrastructure Efficient, reliable, easy to use Open Source, Apache License
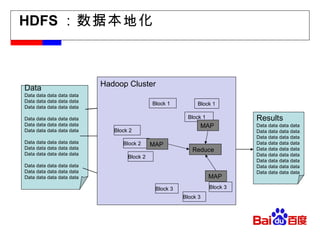
HDFS :数据本地化 DataData data data data data Data data data data data Data data data data data Data data data data data Data data data data data Data data data data data Data data data data data Data data data data data Data data data data data Data data data data data Data data data data data Data data data data data Results Data data data data Data data data data Data data data data Data data data data Data data data data Data data data data Data data data data Data data data data Data data data data Hadoop Cluster Block 1 Block 1 Block 2 Block 2 Block 2 Block 1 MAP MAP MAP Reduce Block 3 Block 3 Block 3
#7 按照当前各公司公布的数据来看,百度日处理规模居全球主要互联网公司第 2 名,仅次于 Google 的每日 30PB 左右的输入数据处理量。
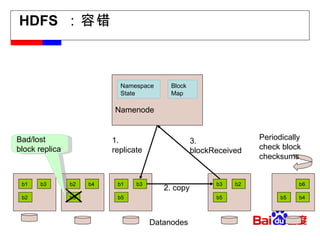
#15 – Chooses new DataNodes for new replicas – Balances disk usage – Balances communication traffic to DataNodes
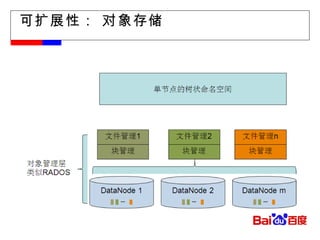
#21 Block (Object) Storage Subsystem Shared storage provided as pools of blocks Namespaces (HDFS, others) use one or more block-pools Note: HDFS has 2 layers today – we are generalizing/extending it.
![HDFS 原理与实现 刘景龙 [email_address]](https://image.slidesharecdn.com/hdfs-111017125449-phpapp02/85/Hdfs-introduction-1-320.jpg)
![HDFS 原理与实现 刘景龙 [email_address]](https://image.slidesharecdn.com/hdfs-111017125449-phpapp02/75/Hdfs-introduction-1-2048.jpg)











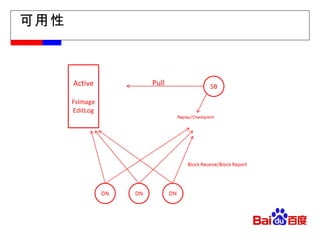


![求助热线: 邮件组: [email_address] Hi 群: 1199411 文档园地: http://wiki.babel.baidu.com/twiki/bin/view/Com/Inf/Peta%E6%96%87%E6%A1%A3%E5%BB%BA%E8%AE%BE%E8%AE%A1%E5%88%92](https://image.slidesharecdn.com/hdfs-111017125449-phpapp02/85/Hdfs-introduction-27-320.jpg)











































![Picasso[1]](https://cdn.slidesharecdn.com/ss_thumbnails/picasso1-12978056095994-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)