Download as PDF, PPTX








![How good is it?
11
vs.
How close is the synthetic data to the original?
What does it mean to be close for datasets?
And, then how close should it even be?
[there is surprisingly little consensus on answering this question]
Original Data Synthetic Data](https://image.slidesharecdn.com/guestlectureimperial-nov23-231122054950-ef6cabdf/85/Everything-You-Always-Wanted-to-Know-About-Synthetic-Data-11-320.jpg)


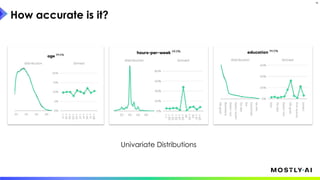
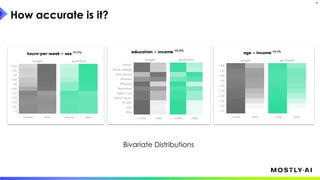

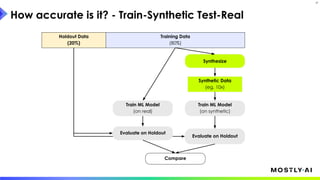
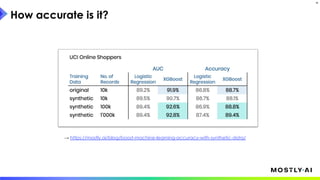


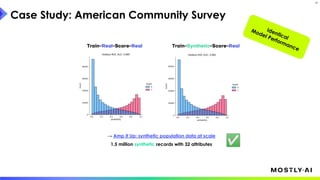
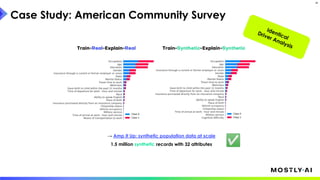



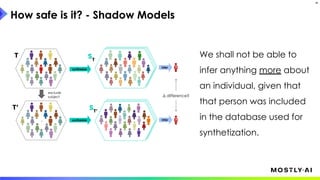


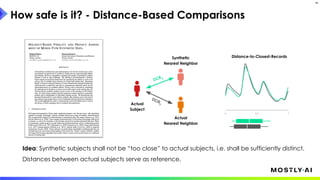







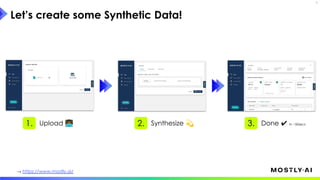
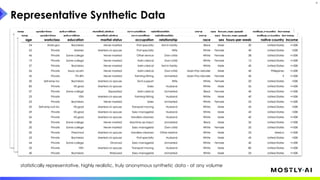
1. Dr. Michael Platzer gave a guest lecture at Imperial College London on synthetic data, covering what it is, how accurate it can be, and how safe it is. 2. He discussed how to generate synthetic data that is statistically representative of real data while being truly anonymous using MOSTLY AI's techniques. 3. Dr. Platzer evaluated the accuracy of synthetic data using measures like comparing machine learning model performance on synthetic versus real data as well as comparing marginal distributions, finding synthetic data can match real data closely.










































































