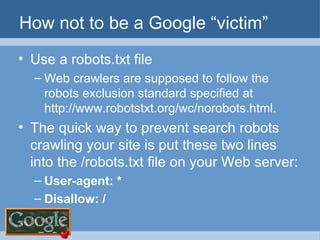
The document provides an overview of techniques for using Google to perform reconnaissance and searches. It discusses using Google to find information about people by searching for files containing personal details. It also describes using advanced Google search operators and techniques like crawling domains to find additional pages. The document warns that exposing sensitive information or vulnerabilities online could enable malicious activities.








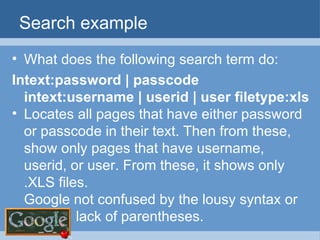









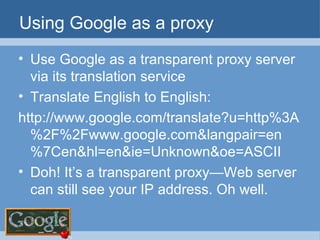






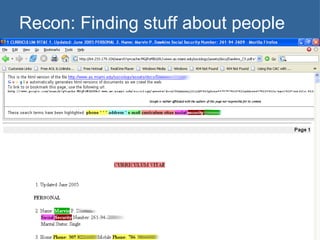

![Scraping domain names with shell script trIpl3-H> trIpl3-H> lynx –dump \ "http://www.google.com/search?q=site:usf.edu+-www.usf.edu&num=100" > sites.txt trIpl3-H> trIpl3-H> sed -n 's/\. http:\/\/[[:alpha:]]*.usf.edu\//& /p' sitejunk.txt >> sites.out trIpl3-H> trIpl3-H> trIpl3-H>](https://image.slidesharecdn.com/google-1230355883654463-2/85/Google-34-320.jpg)