Download to read offline



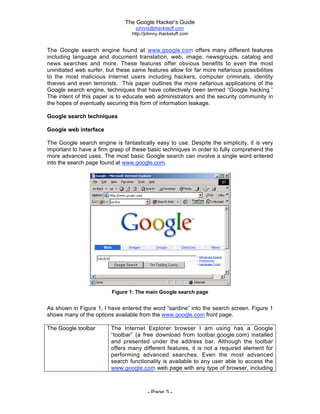
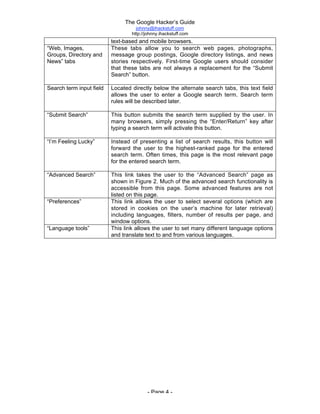
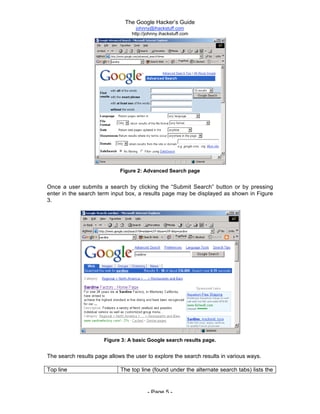

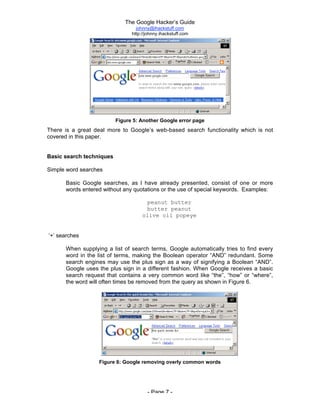






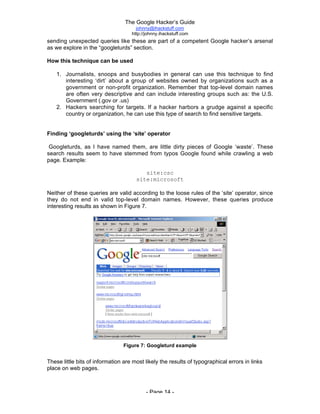

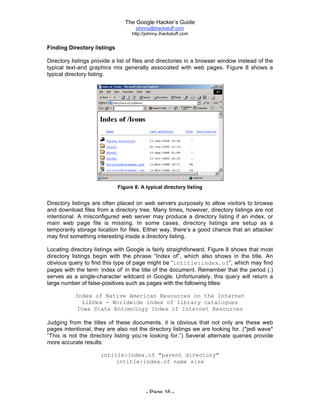



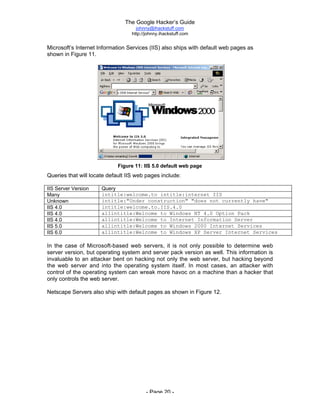


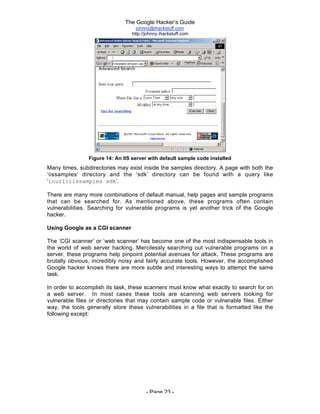
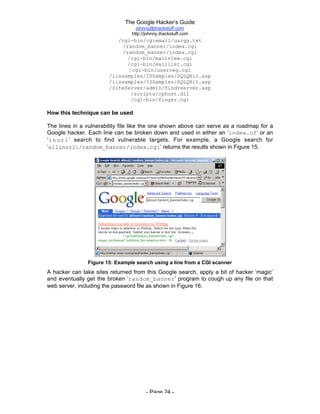




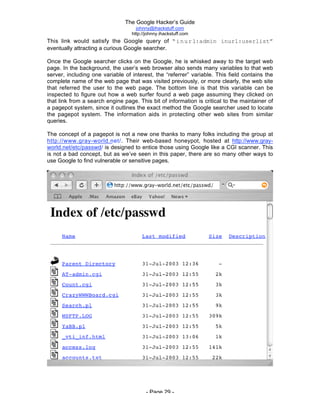




The document is titled 'The Google Hacker's Guide' by Johnny Long and provides insights into using Google search techniques, including basic and advanced operators, while highlighting the potential for misuse by malicious users. It aims to educate web administrators and security professionals on 'google hacking' and protecting against it. Various search strategies and operator functionalities are detailed to help users refine and enhance their Google search capabilities.





































