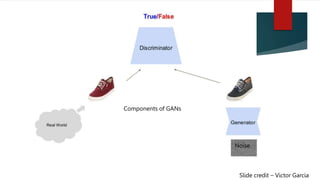
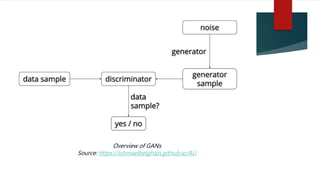
Generative Adversarial Networks (GANs) are a system of two neural networks competing against each other, where one network generates new samples (the generator) and the other evaluates them to determine if they are real or generated (the discriminator). GANs can learn the training data distribution to generate new samples similar to the training data. The generator learns to produce more realistic samples to fool the discriminator while the discriminator learns to better distinguish real and generated samples. GANs have been applied to image generation and other unsupervised learning tasks.