Download to read offline









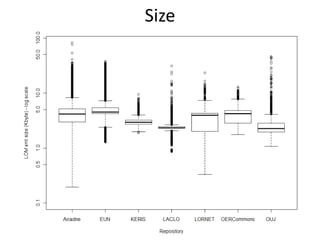
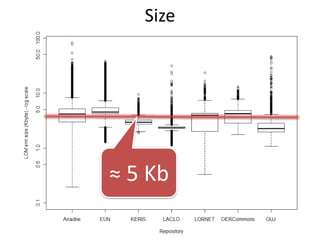

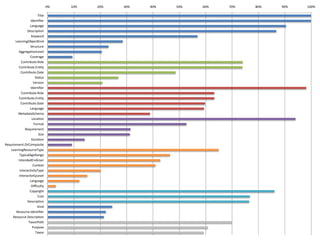
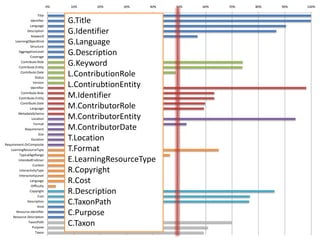

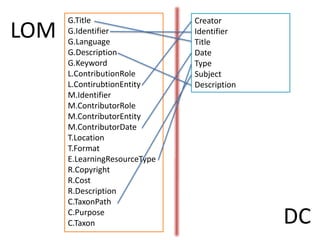

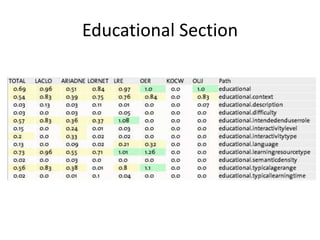


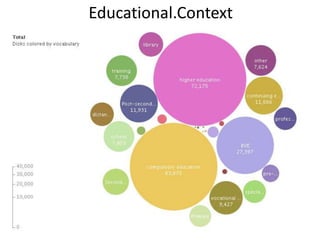
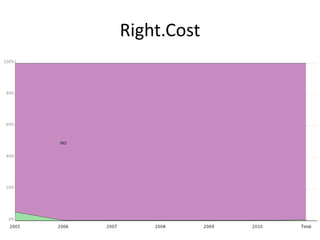
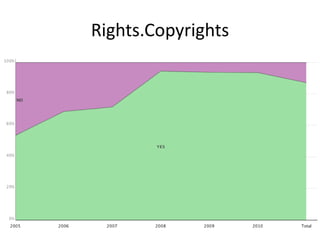





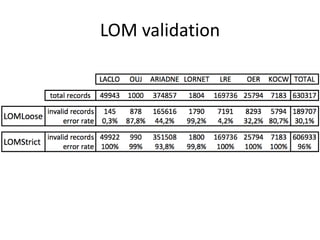
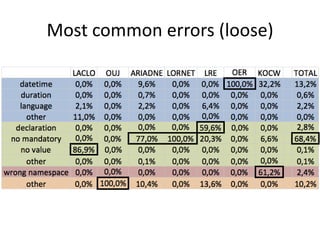




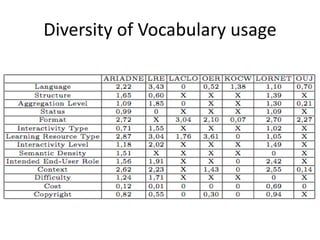
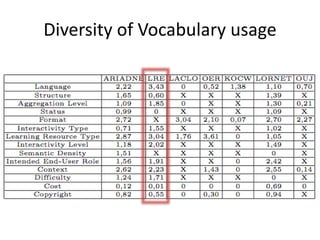
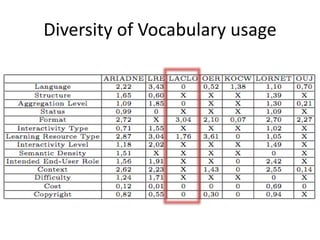
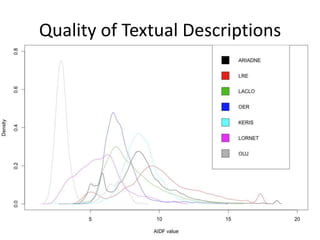
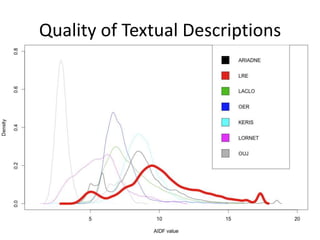
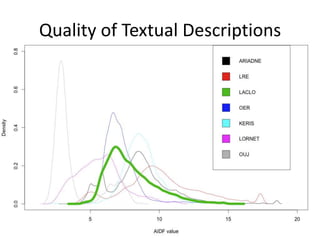
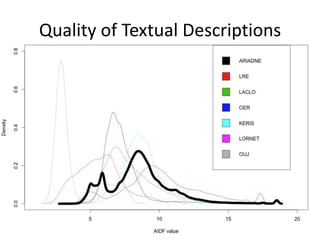





This document summarizes research analyzing metadata from over 630,000 learning objects using the Learning Object Metadata (LOM) standard. The analysis found that LOM instances take up around 5KB of storage space on average. Only 20 of LOM's 50 elements are used frequently, capturing similar information to the Dublin Core standard. Educational elements are underused and dependent on individual communities. Validation found loose implementation of LOM's XML structure results in good interoperability despite unclear value spaces. Metadata quality is varied, showing a need for quality assurance processes. The conclusion advocates for more studies of this kind to improve metadata standards and learning technologies.























































































