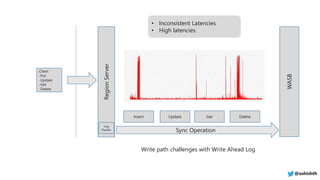
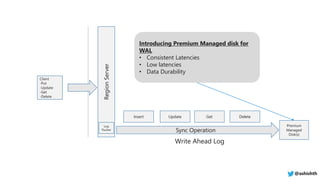
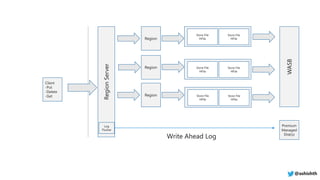
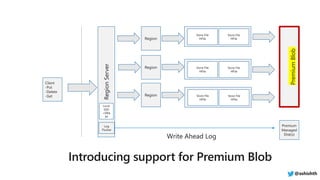
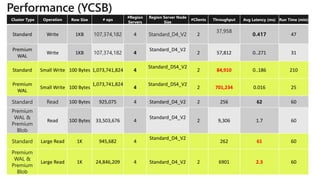
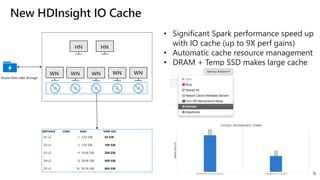
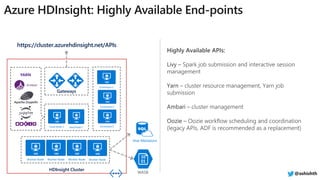
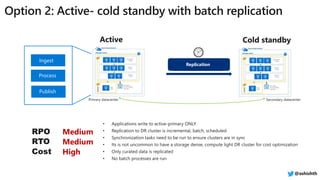
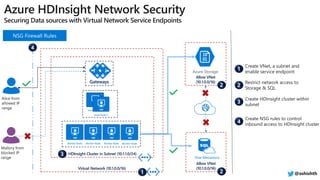
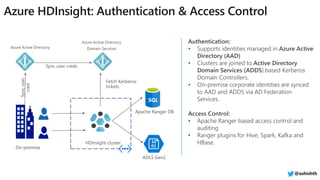
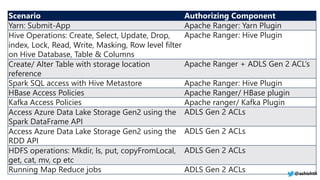
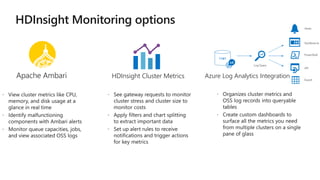
The document provides a comprehensive overview of Azure HDInsight, detailing its capabilities for building a secure and managed Apache Hadoop and Spark platform in the cloud. It discusses features such as data storage options, performance metrics, data ingestion and movement strategies, and integration with various tools and languages. Additionally, it highlights best practices for architecture, infrastructure, security, and DevOps in managing big data workloads.




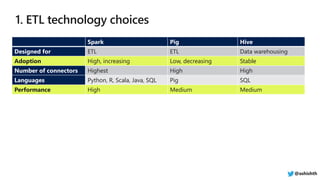
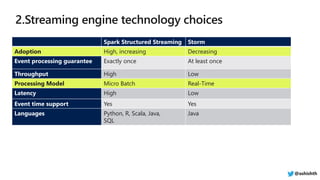
![Capability Hive LLAP Spark SQL Presto
Interactive Query Speed High High Medium
Scale High High Low
Caching Yes Yes Early Support
Result Caching Yes No No
Intelligent Cache
Eviction
Yes No No
Materialized Views Yes No No
Complex Fact to Fact Joins Yes Yes No
Transactions Yes No No
Query Concurrency High Low Low
Row , Column level
security
Yes [Apache Ranger+ AAD] Medium Medium
Rich end user Tools Yes Yes Yes
Language Support SQL, UDF SQL, Scala, Python SQL
Data Source Connector
Support
Storage Handlers Data Sources High number of
connectors @ashishth](https://image.slidesharecdn.com/dataarchitectsguideforsuccessfulopensourceanalyticsworkloadswithazurehdinsight-190215000328/85/HDInsight-for-Architects-9-320.jpg)














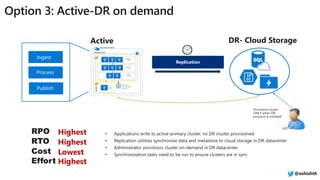
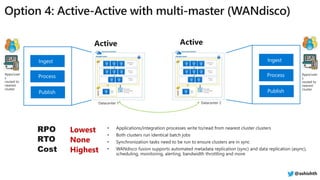
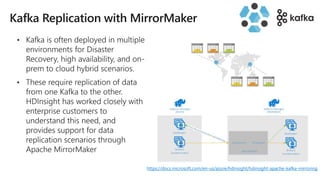






![[DSC Europe 22] Lakehouse architecture with Delta Lake and Databricks - Draga...](https://cdn.slidesharecdn.com/ss_thumbnails/draganberic-lakehousearchitecturewithdeltalakeanddatabricks-221130080712-6e817e95-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DSC Europe 22] Overview of the Databricks Platform - Petar Zecevic](https://cdn.slidesharecdn.com/ss_thumbnails/petarzecevic-databricksoverview-221130080703-c60d93de-thumbnail.jpg?width=640&height=640&fit=bounds)




































































