Macromolecules
• Most arepolymers
• Polymer
• Large molecule consisting of many
identical or similar building blocks
linked by bonds
• Monomer
• Subunits that serve as building blocks
for polymers
4.
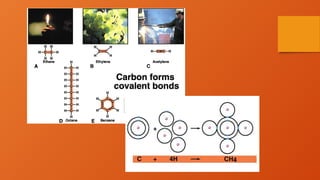
Organic Macromolecules ContainCarbon
Each carbon atom can make four
covalent bonds with other types of
atoms or additional carbons.
Question: How many
electrons does carbon need
to fill its outer energy level?
Answer: Four
6.
Comparison of Terms
MoleculeTwo or more atoms joined by chemical
bonds
Macromolecule Large polymer made of repeating
monomer units
Four types of organic macromolecules
are important in living systems.
7.
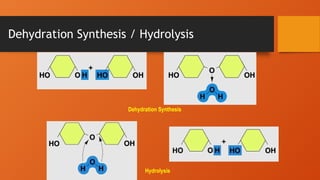
Synthesis and Breakdownof Macromolecules
Dehydration
Synthesis
Removal of water to add
monomer units
Hydrolysis Addition of OH and H groups of
water to break a bond between
monomers
• Large polymersform from smaller monomers.
• New properties emerge.
• Living cells require/synthesize:
• Carbohydrates
• Lipids
• Proteins
• Nucleic Acids
The Molecules of Life
10.
How Cells UseOrganic Compounds
• Biological organisms use the same
kinds of building blocks.
• All macromolecules (large, complex
molecules) have specific functions in
cells.
• Other than water, macromolecules
make up the largest percent mass of
a cell.
• Used asfuel and building material
• Carbs are sugars and their polymers
• Main types:
• Monosaccharides
• Disaccharides
• Polysaccharides
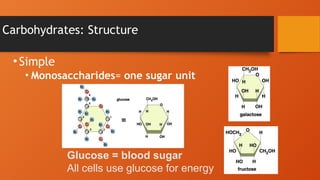
Carbohydrates
Monosaccharides (CH2O)
• Generallyhave molecular
formulas in some multiple of
CH2O
• Glucose (C6H12O6) is most
common
• In aqueous solution may form
rings
• Major nutrients for cells
Polysaccharides
• 10s to1000s of monosaccharides long
• Starch
• Storage poly. of plants
• Glycogen
• Storage poly. of animals
• Cellulose
• Structural poly. which is a major component of
tough plant cell walls
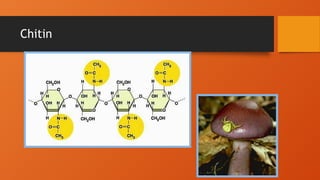
• Chitin
• Structural poly. used by arthropods to build
exoskeletons
21.
Carbohydrates: Structure
•Complex
• Polysaccharides=many sugar units
• Starch -- storage in plants
• Glycogen -- storage in animals
• Cellulose -- plant cell walls, indigestible
• Chitin -- exoskeletons of insects,
fungal cell walls
Lipids
• Mostly hydrophobicmolecules with
diverse functions
• Little or no affinity for water
• Used for energy storage and
structure
• Main types:
• Fats
• Phospholipids
• Steroids
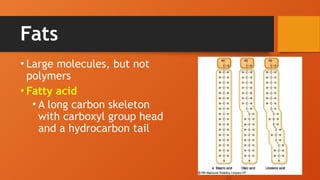
Fats
• Large molecules,but not
polymers
• Fatty acid
• A long carbon skeleton
with carboxyl group head
and a hydrocarbon tail
33
29.
Saturated & UnsaturatedFats
• Saturated fatty acids
• Fatty acid containing no
double bonds between the
carbon atoms composing
the tail
• Solids at room temp.
• Unsaturated fatty acids
• Has one or more double
bonded carbons in the tail
• Melts at room temp.
30.
Lipids: Structure
• Typesof Fatty Acids
• Saturated – 2H per internal carbon
• Unsaturated -- <2H per internal carbon
one or more double bonds
• Monounsaturated – one double bond
• Polyunsaturated – more than one double bond
31.
Which Is aSource of Unsaturated Fatty Acids?
Linseed Oil
Beef Fat
32.
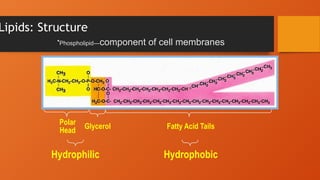
Phospholipids
• Two fattyacid tails linked to one glycerol molecule
• Ambivalent behavior toward water
• When in contact with water they form a micelle (cluster)
Protein
Proteins are nutrientswhich contain
materials the body uses for growth
and repair.
Proteins are made of Carbon,
Hydrogen, Oxygen and Nitrogen.
Proteins are large molecules made
up of combinations of amino acids.
36.
Proteins
• The moleculartools for most cellular functions
• Used for:
• Structural support
• Storage
• Transport of other substances
• Signaling from one part of the organism to the other
• Movement
• Defense against foreign substances
• Conformation
• Unique 3-D shape of a protein
37.
• Amino acidsare the building blocks of proteins.
• These building blocks bond together to form chains that are
called peptides.
• Proteins are formed of combinations of large peptides
chains, this is referred to as polypeptides.
Amino Acids Peptides Polypeptides
Protein
38.
Protein Polypeptides
• Polymersof amino acids
connected in a specific
sequence
• Amino acids
• Organic molecules
possessing both
carboxyl and amino
groups
• Acidity is determined by
side chains
Peptide Bonds
• Formedwhen an
enzyme joins amino
acids by means of
condensation
• Polypeptide
• Chains of amino
acids linked by
peptide bonds
41.
Essential and non-
essential
Essentialamino acids
(must be in the diet
because cells can’t
synthesize them) and
non-essential amino
acids (can be made by
cells).
42.
• Conformation (shape)determines function and is the
result of the linear sequence of amino acids in a
polypeptide.
• Folding, coiling and the interactions of multiple
polypeptide chains create a functional protein
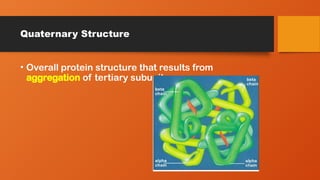
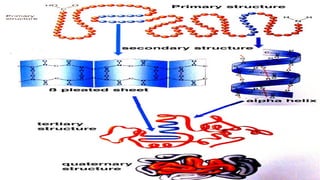
• 4 levels of conformation
• Primary
• Secondary
• Tertiary
• Quartinary
Protein Conformation
43.
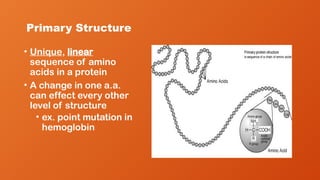
Primary Structure
• Unique,linear
sequence of amino
acids in a protein
• A change in one a.a.
can effect every other
level of structure
• ex. point mutation in
hemoglobin
44.
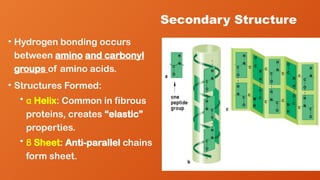
Secondary Structure
• Hydrogenbonding occurs
between amino and carbonyl
groups of amino acids.
• Structures Formed:
• α Helix: Common in fibrous
proteins, creates “elastic”
properties.
• β Sheet: Anti-parallel chains
form sheet.
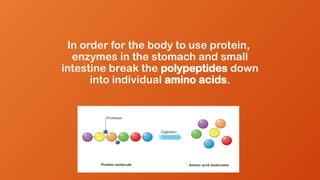
In order forthe body to use protein,
enzymes in the stomach and small
intestine break the polypeptides down
into individual amino acids.
49.
Making a protein
•In transcription, the DNA sequence of a gene is
"rewritten" in RNA. In eukaryotes, the RNA must go
through additional processing steps to become a
messenger RNA, or mRNA.
• In translation, the sequence of nucleotides in the
mRNA is "translated" into a sequence of amino
acids in a polypeptide (protein chain).
50.
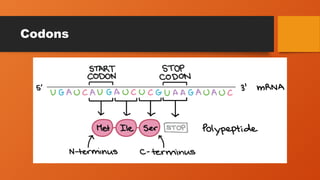
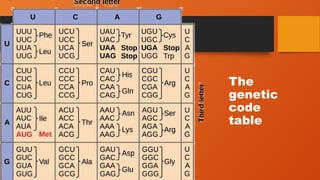
Codons
• Cells decodemRNAs by reading their nucleotides in groups of
three, called codons. Here are some features of codons:
• Most codons specify an amino acid
• Three "stop" codons mark the end of a protein
• One "start" codon, AUG, marks the beginning of a protein and also
encodes the amino acid methionine
• 64 codons
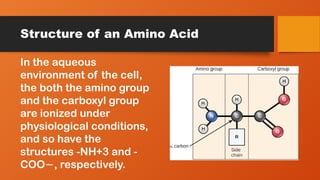
Structure of anAmino Acid
In the aqueous
environment of the cell,
the both the amino group
and the carboxyl group
are ionized under
physiological conditions,
and so have the
structures -NH+3 and -
COO , respectively.
−
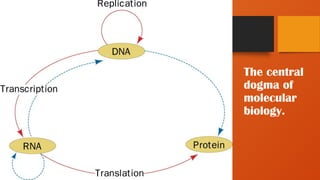
•Processes in thetransfer of genetic information:
•Replication: identical copies of DNA are made
•Transcription: genetic messages are read and carried
out of the cell nucleus to the ribosomes, where protein
synthesis occurs.
•Translation: genetic messages are decoded to make
proteins.
81
60.
Two types ofNucleotides
(depending on the sugar they contain)
1- Ribonucleic acids (RNA)
The pentose sugar is Ribose (has a
hydroxyl group in the 3rd
carbon---OH)
2- Deoxyribonucleic acids (DNA)
The pentose sugar is Deoxyribose (has
just an hydrogen in the same place--- H)
Deoxy = “minus oxygen”
61.
Nucleic acids arepolymers of nucleotides
In eukaryotic cells nucleic acids are either:
Deoxyribose nucleic acids (DNA)
Ribose nucleic acids (RNA) Messenger RNA (mRNA)
Transfer RNA (tRNA)
Ribosomal RNA (tRNA
Nucleotides are carbon ring structures containing
nitrogen linked to a 5-carbon sugar (a ribose)
5-carbon sugar is either a ribose or a deoxy-
ribose making the nucleotide either a
ribonucleotide or a deoxyribonucleotide
62.
NUCLEIC ACIDS (DNAand RNA)
DNA – Deoxyribonucleic Acid
• DNA controls all living processes including
production of new cells – cell division
• DNA carries the genetic code – stores and transmits
genetic information from one generation to the next
• Chromosomes are made of DNA
• DNA is located in the nucleus of the cell
64.
Nucleic Acids
• Nucleicacids are molecules that store
information for cellular growth and
reproduction
• There are two types of nucleic acids:
- deoxyribonucleic acid (DNA) and
ribonucleic acid (RNA)
• These are polymers consisting of long
chains of monomers called nucleotides
• A nucleotide consists of a nitrogenous base,
a pentose sugar and a phosphate group:
65.
All nucleotides containthree components:
1. A nitrogen heterocyclic base
2. A pentose sugar
3. A phosphate residue
Nucleic Acids
DNA and RNA are nucleic acids, long, thread-like
polymers
made up of a linear array of monomers called
nucleotides
66.
• It isthe order of these base pairs that determines genetic
makeup
• One phosphate + one sugar + one base = one nucleotide
• Nucleotides are the building blocks of DNA – thus, each strand
of DNA is a string of nucleotides
68.
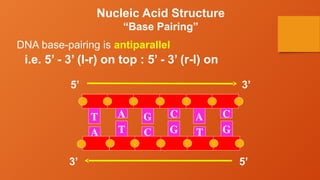
Nucleic Acid Structure
“BasePairing”
T A A
G C C
3’
T C G
G T
A
3’ 5’
5’
DNA base-pairing is antiparallel
i.e. 5’ - 3’ (l-r) on top : 5’ - 3’ (r-l) on
69.
Nucleic Acid Structure
“BasePairing”
RNA [normally] exists as a single stranded polymer
DNA exists as a double stranded polymer
DNA double strand is created by hydrogen bonds between
nucleotides
Nucleotides always bind to complementary nucleotides
A T
C
G
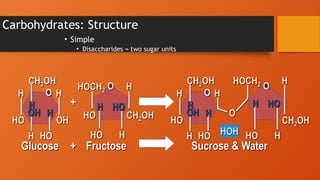
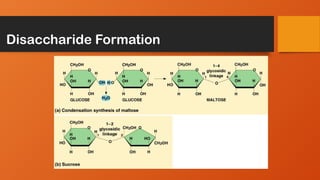
#18 Oligosaccharides (“oligo-” means few or scant).
Several monosaccharides joined together.
Sucrose (table sugar) is disaccharide of one glucose and one fructose (Fig 3-1, p39).
Often combined with other molecules.
Many larger molecules have oligosaccharides attached for various purposes.
Sometimes used for cell ID.
The cell membrane has many proteins in it, some of which have attached oligosaccharides projecting away from the cell. Sometimes these are used as chemical labels for cell type.
#38 This shows how water is removed from three fatty acids and glycerol to make a fat and water.
#43 Complex ring forms
Some hormones, especially those produced by the adrenal gland and sex hormones.
Cholesterol
Natural substance; not necessarily bad for you.
Found in membranes in between the fatty acid tails of phospholipids.
Athletes beware of androgenics!
Dangerous chemicals.
Please reconsider your value system if you use these.
If you use them, you WILL regret it!
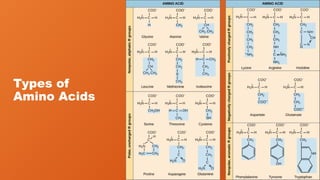
#57 It is useful to classify amino acids based on their R-groups, because it is these side chains that give each amino acid its characteristic properties.
#58 Alanine (Ala/A) is one of the most abundant amino acids found in proteins, ranking second only to leucine in occurrence. A D-form of the amino acid is also found in bacterial cell walls. Alanine is non-essential, being readily synthesized from pyruvate. It is coded for by GCU, GCC, GCA, and GCG.
Glycine (Gly/G) is the amino acid with the shortest side chain, having an R-group consistent only of a single hydrogen. As a result, glycine is the only amino acid that is not chiral. Its small side chain allows it to readily fit into both hydrophobic and hydrophilic environments.
Glycine is specified in the genetic code by GGU, GGC, GGA, and GGG. It is nonessential to humans.
Isoleucine (Ile/I) is an essential amino acid encoded by AUU, AUC, and AUA. It has a hydrophobic side chain and is also chiral in its side chain.
Leucine (Leu/L) is a branched-chain amino acid that is hydrophobic and essential. Leucine is the only dietary amino acid reported to directly stimulate protein synthesis in muscle, but caution is in order, as 1) there are conflicting studies and 2) leucine toxicity is dangerous, resulting in "the four D's": diarrhea, dermatitis, dementia and death . Leucine is encoded by six codons: UUA,UUG, CUU, CUC, CUA, CUG.
Methionine (Met/M) is an essential amino acid that is one of two sulfurcontaining amino acids - cysteine is the other. Methionine is non-polar and encoded solely by the AUG codon. It is the “initiator” amino acid in protein synthesis, being the first one incorporated into protein chains. In prokaryotic cells, the first methionine in a protein is formylated.
Proline (Pro/P) is the only amino acid found in proteins with an R-group that joins with its own α-amino group, making a secondary amine and a ring. Proline is a non-essential amino acid and is coded by CCU, CCC, CCA, and CCG. It is the least flexible of the protein amino acids and thus gives conformational rigidity when present in a protein. Proline’s presence in a protein affects its secondary structure. It is a disrupter of α-helices and β-strands. Proline is often hydroxylated in collagen (the reaction requires Vitamin C - ascorbate) and this has the effect of increasing the protein’s conformational stability. Proline hydroxylation of hypoxia-inducible factor (HIF) serves as a sensor of oxygen levels and targets HIF for destruction when oxygen is plentiful.
Valine (Val/V) is an essential, non-polar amino acid synthesized in plants. It is noteworthy in hemoglobin, for when it replaces glutamic acid at position number six, it causes hemoglobin to aggregate abnormally under low oxygen conditions, resulting in sickle cell disease. Valine is coded in the genetic code by GUU, GUC, GUA, and GUG.
#59 Aspartic acid (Asp/D) is a non-essential amino acid with a carboxyl group in its Rgroup. It is readily produced by transamination of oxaloacetate. With a pKa of 3.9, aspartic acid’s side chain is negatively charged at physiological pH. Aspartic acid is specified in the genetic code by the codons GAU and GAC.
Glutamic acid (Glu/E), which is coded by GAA and GAG, is a non-essential amino acid readily made by transamination of α- ketoglutarate. It is a neurotransmitter and has an R-group with a carboxyl group that readily ionizes (pKa = 4.1) at physiological pH.
#60 Arginine (Arg/R) is an amino acid that is, in some cases, essential, but non-essential in others. Premature infants cannot synthesize arginine. In addition, surgical trauma, sepsis, and burns increase demand for arginine. Most people, however, do not need arginine supplements. Arginine’s side chain contains a complex guanidinium group with a pKa of over 12, making it positively charged at cellular pH. It is coded for by six codons - CGU, CGC, CGA, CGG, AGA, and AGG.
Histidine (His/H) is the only one of the proteinaceous amino acids to contain an imidazole functional group. It is an essential amino acid in humans and other mammals. With a side chain pKa of 6, it can easily have its charge changed by a slight change in pH. Protonation of the ring results in two NH structures which can be drawn as two equally important resonant structures.
Lysine (Lys/K) is an essential amino acid encoded by AAA and AAG. It has an Rgroup that can readily ionize with a charge of +1 at physiological pH and can be posttranslationally modified to form acetyllysine, hydroxylysine, and methyllysine. It can also be ubiquitinated, sumoylated, neddylated, biotinylated, carboxylated, and pupylated, and. O-Glycosylation of hydroxylysine is used to flag proteins for export from the cell. Lysine is often added to animal feed because it is a limiting amino acid and is necessary for optimizing growth of pigs and chickens.
#61 Phenylalanine (Phe/ F) is a non-polar, essential amino acid coded by UUU and UUC. It is a metabolic precursor of tyrosine. Inability to metabolize phenylalanine arises from the genetic disorder known as phenylketonuria. Phenylalanine is a component of the aspartame artificial sweetener.
Tryptophan (Trp/W) is an essential amino acid containing an indole functional group. It is a metabolic precursor of serotonin, niacin, and (in plants) the auxin phytohormone. Though reputed to serve as a sleep aid, there are no clear research results indicating this.
Tyrosine (Tyr/Y) is a non-essential amino acid coded by UAC and UAU. It is a target for phosphorylation in proteins by tyrosine protein kinases and plays a role in signaling processes. In dopaminergic cells of the brain, tyrosine hydroxylase converts tyrosine to l-dopa, an immediate precursor of dopamine. Dopamine, in turn, is a precursor of norepinephrine and epinephrine. Tyrosine is also a precursor of thyroid hormones and melanin.
#62 Serine (Ser/S) is one of three amino acids having an R-group with a hydroxyl in it (threonine and tyrosine are the others). It is coded by UCU, UCC, UCA, UGC, AGU, and AGC. Being able to hydrogen bond with water, it is classified as a polar amino acid. It is not essential for humans. Serine is precursor of many important cellular compounds, including purines, pyrimidines, sphingolipids, folate, and of the amino acids glycine, cysteine, and tryptophan. The hydroxyl group of serine in proteins is a target for phosphorylation by certain protein kinases. Serine is also a part of the catalytic triad of serine proteases.
Threonine (Thr/T) is a polar amino acid that is essential. It is one of three amino acids bearing a hydroxyl group (serine and tyrosine are the others) and, as such, is a target for phosphorylation in proteins. It is also a target for Oglycosylation of proteins. Threonine proteases use the hydroxyl group of the amino acid in their catalysis and it is a precursor in one biosynthetic pathway for making glycine. In some applications, it is used as a pro-drug to increase brain glycine levels. Threonine is encoded in the genetic code by ACU, ACC, ACA, and ACG.
#63 Asparagine (Asn/N) is a non-essential amino acid coded by AAU and AAC. Its carboxyamide in the R-group gives it polarity. Asparagine is implicated in formation of acrylamide in foods cooked at high temperatures (deep frying) when it reacts with carbonyl groups. Asparagine can be made in the body from aspartate by an amidation reaction with an amine from glutamine. Breakdown of asparagine produces malate, which can be oxidized in the citric acid cycle.
Cysteine (Cys/C) is the only amino acid with a sulfhydryl group in its side chain. It is nonessential for most humans, but may be essential in infants, the elderly and individuals who suffer from certain metabolic diseases. Cysteine’s sulfhydryl group is readily oxidized to a disulfide when reacted with another one. In addition to being found in proteins, cysteine is also a component of the tripeptide, glutathione. Cysteine is specified by the codons UGU and UGC.
Glutamine (Gln/Q) is an amino acid that is not normally essential in humans, but may be in individuals undergoing intensive athletic training or with gastrointestinal disorders. It has a carboxyamide side chain which does not normally ionize under physiological pHs, but which gives polarity to the side chain. Glutamine is coded for by CAA and CAG and is readily made by amidation of glutamate. Glutamine is the most abundant amino acid in circulating blood and is one of only a few amino acids that can cross the blood-brain barrier.
Selenocysteine (Sec/U) is a component of selenoproteins found in all kingdoms of life. It is a component in several enzymes, including glutathione peroxidases and thioredoxin reductases. Selenocysteine is incorporated into proteins in an unusual scheme involving the stop codon UGA. Cells grown in the absence of selenium terminate protein synthesis at UGAs. However, when selenium is present, certain mRNAs which contain a selenocysteine insertion sequence (SECIS), insert selenocysteine when UGA is encountered. The SECIS element has characteristic nucleotide sequences and secondary structure base-pairing patterns. Twenty five human proteins contain selenocysteine.
Pyrrolysine (Pyl/O) is a twenty second amino acid, but is rarely found in proteins. Like selenocysteine, it is not coded for in the genetic code and must be incorporated by unusual means. This occurs at UAG stop codons. Pyrrolysine is found in methanogenic archaean organisms and at least one methane-producing bacterium. Pyrrolysine is a component of methane-producing enzymes.
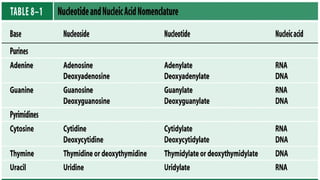
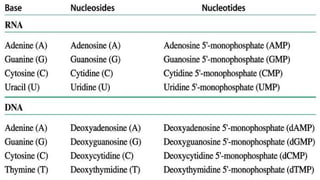
#103 FIGURE 8-2 (part 1) Major purine and pyrimidine bases of nucleic acids. Some of the common names of these bases reflect the circumstances of their discovery. Guanine, for example, was first isolated from guano (bird manure), and thymine was first isolated from thymus tissue.
#105 FIGURE 8-2 (part 2) Major purine and pyrimidine bases of nucleic acids. Some of the common names of these bases reflect the circumstances of their discovery. Guanine, for example, was first isolated from guano (bird manure), and thymine was first isolated from thymus tissue.
#117 “Gattaca” is a science fiction movie starring Uma Thurman, Ethan Hawke, and Jude Law
















































![Nucleic Acid Structure
“Base Pairing”
RNA [normally] exists as a single stranded polymer
DNA exists as a double stranded polymer
DNA double strand is created by hydrogen bonds between
nucleotides
Nucleotides always bind to complementary nucleotides
A T
C
G](https://image.slidesharecdn.com/g-12-biological-molecules-260203103344-cd759ad6/85/G-12-Biological-Molecules-Presentation-pptx-69-320.jpg)































![CTEV [ clubfoot] DR ARUN LAL ,DR MOHAMED ASHRAF travancore medical college k...](https://cdn.slidesharecdn.com/ss_thumbnails/ctevclubfootdrarunlaldrmohamedashraftravancoremedicalcollegekollamkeralaindia-260208063247-18fc466c-thumbnail.jpg?width=640&height=640&fit=bounds)





![ONFH[AVN HIP] -TRIPLE REGIME -A NOVAL SURGICAL CONCEPT .pptx](https://cdn.slidesharecdn.com/ss_thumbnails/onfhavnhip2026koaconcalicutdrgokuldevdrmashraf-260210064517-213ec005-thumbnail.jpg?width=640&height=640&fit=bounds)










