Downloaded 74 times


![What is Parallel Computing?
A form of computation in which many calculations are
carried out simultaneously, operating on the principle
that large problems can often be divided into smaller
ones, which are then solved concurrently ("in parallel").
1
[Almasi and Gottlieb, 1989]
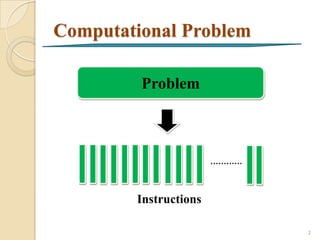
Problem
Task Problem
Task Task Task
Instructions
… … … …
CPU CPU CPU CPU
4](https://image.slidesharecdn.com/fullintroductiontoparallelcomputing-130121042528-phpapp01/85/Full-introduction-to_parallel_computing-4-320.jpg)
![Pattern of Parallelism
Data parallelism [Quinn, 2003] 2
There are independent tasks applying the same
operation to different elements of a data set.
for i ← 0 to 99 do
a[i] = b[i] + c[i]
endfor
Functional Parallelism [Quinn, 2003] 2
There are independent tasks applying different
operations to different data elements.
a = 2, b=3
m = (a + b) / 2
n = a 2 + b2
5](https://image.slidesharecdn.com/fullintroductiontoparallelcomputing-130121042528-phpapp01/85/Full-introduction-to_parallel_computing-5-320.jpg)


![What is Cluster?
A group of linked computers, working together
closely so that in many respects they from a single
computer
To improve performance and/or availability over
that provided by a single computer 3
[Webopedia computer dictionary, 2007]
High-Performance High-Availability
10](https://image.slidesharecdn.com/fullintroductiontoparallelcomputing-130121042528-phpapp01/85/Full-introduction-to_parallel_computing-10-320.jpg)
![Message-Passing model
The system is assumed to be a collection of processors,
each with its own local memory (Distributed memory
system)
A processor has direct access only to the instructions
and data stored in its local memory
An interconnection network supports message passing
between processors
MPI Standard
2
[Quinn, 2003] 12](https://image.slidesharecdn.com/fullintroductiontoparallelcomputing-130121042528-phpapp01/85/Full-introduction-to_parallel_computing-12-320.jpg)
![Performance metrics
for parallel computing
• Speedup [Kumar et al., 1994] 4
How much performance gain is achieved
parallelizing a given application over a sequential
implementation
SP - speedup with p processors
TS
Sp = P Ts Tp Sp
TP
4 40 15 2.67
where
TS - a sequential execution time
P - a number of processors
TP - a parallel execution time
with p processors
13](https://image.slidesharecdn.com/fullintroductiontoparallelcomputing-130121042528-phpapp01/85/Full-introduction-to_parallel_computing-13-320.jpg)
![Speedup
5
[Eijkhout, 2011]
14](https://image.slidesharecdn.com/fullintroductiontoparallelcomputing-130121042528-phpapp01/85/Full-introduction-to_parallel_computing-14-320.jpg)
![Efficiency
A measure of processor utilization [Quinn, 2003] 2
EP - Efficiency with p processors
SP P Sp Ep
Ep =
P 4 2 0.5
8 3 0.375
In practice, speedup is less than p and efficiency is
between zero and one, depending on the degree of
effectiveness with which the processors are utilized
5
[Eijkhout, 2011]
15](https://image.slidesharecdn.com/fullintroductiontoparallelcomputing-130121042528-phpapp01/85/Full-introduction-to_parallel_computing-15-320.jpg)
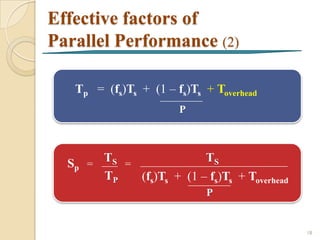
![Effective factors of
Parallel Performance
• Portion of computation [Quinn, 2003]
2
Computations that must be performed sequentially
Computations that can be performed in parallel
fs - Serial fraction of computation
fp - Parallel fraction of computation
TS TS 1
Sp = = =
TP fs(Ts) + fp(Ts) fs + fp
P P
TS fs fp fs(TS) fp(Ts)
100 10% 90% 10 90 16](https://image.slidesharecdn.com/fullintroductiontoparallelcomputing-130121042528-phpapp01/85/Full-introduction-to_parallel_computing-16-320.jpg)
![Effective factors of
Parallel Performance (1)
• Parallel Overhead [Barney, 2011]
6
The amount of time required to coordinate
parallel tasks, as opposed to doing useful
work
o Task start-up time
o Synchronizations
o Data communications
o Task termination time
• Load balancing, etc.
17](https://image.slidesharecdn.com/fullintroductiontoparallelcomputing-130121042528-phpapp01/85/Full-introduction-to_parallel_computing-17-320.jpg)



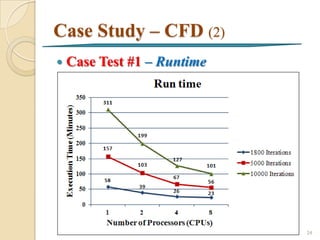
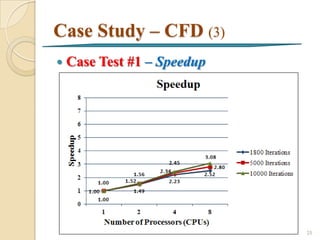
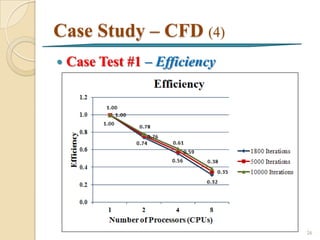
![Case Study - CFD
Parallel Fluent Processing [Junhong, 2004] 7
Run Fluent solver on two or more CPUs
simultaneously to calculate a computational
fluid dynamics (CFD) job
22](https://image.slidesharecdn.com/fullintroductiontoparallelcomputing-130121042528-phpapp01/85/Full-introduction-to_parallel_computing-22-320.jpg)



1. This document introduces parallel computing, which involves dividing large problems into smaller concurrent tasks that can be solved simultaneously using multiple processors to reduce computation time. 2. Parallel computing systems include single machines with multi-core CPUs and computer clusters consisting of multiple interconnected machines. Common parallel programming models involve message passing between distributed memory processors. 3. Performance of parallel programs is measured by metrics like speedup and efficiency. Factors like load balancing, serial fractions of problems, and parallel overhead affect how well a problem can scale with additional processors.




















































![[Harvard CS264] 03 - Introduction to GPU Computing, CUDA Basics](https://cdn.slidesharecdn.com/ss_thumbnails/cs264201103-cudabasicsshare-110209024624-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)






