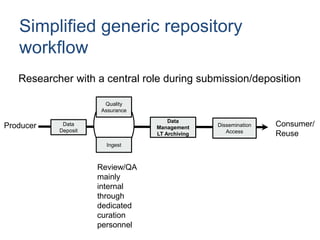
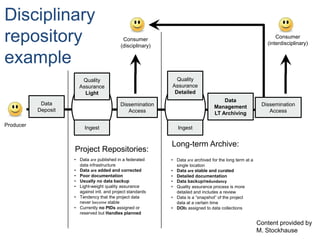
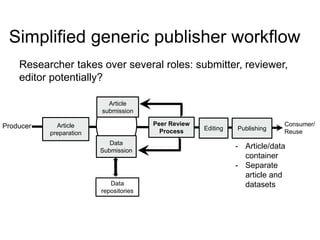
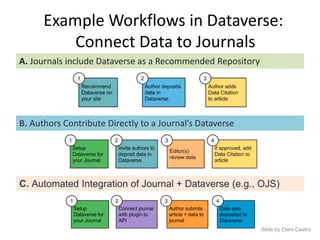
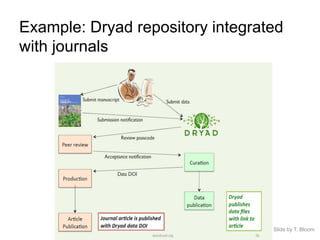
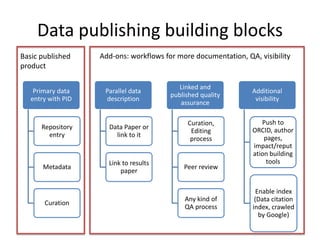
This document discusses data publishing models and workflows, emphasizing the importance of making research data available and discoverable online through dedicated repositories and journals. It outlines various components involved in data publishing, such as quality assurance, peer review, and persistent identification of data, and highlights the need for standardized practices to enhance the usability and interoperability of published data. The concluding sections focus on current challenges in data publishing, including discoverability, versioning, and the necessity for robust documentation and quality assurance processes.