Downloaded 14 times




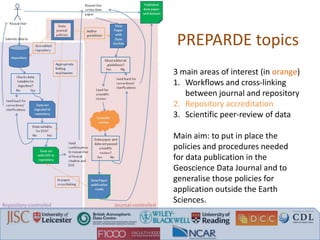




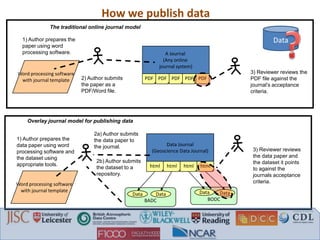












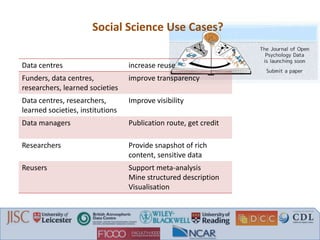






The document discusses recommendations from a workshop on peer review of research data. It focuses on three key areas: 1. Connecting data review with data management planning by requiring data sharing plans, ensuring adequate funding for data management, and refusing publication without clear data access. 2. Connecting scientific and technical review with data curation by linking articles and data with versioning, avoiding duplicate review efforts, and addressing issues found in data. 3. Connecting data review with article review by requiring methods/software information, providing review checklists, ensuring data access for reviewers, and permanent dataset identifiers from repositories.











































































