Download to read offline

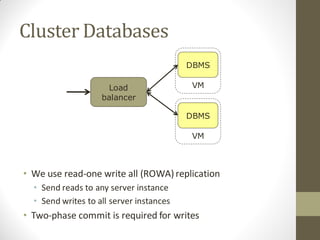
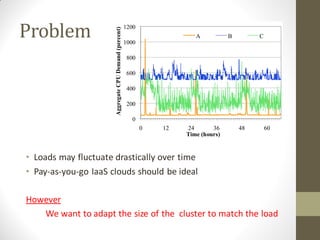


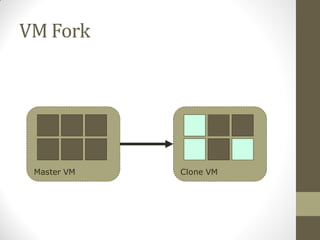
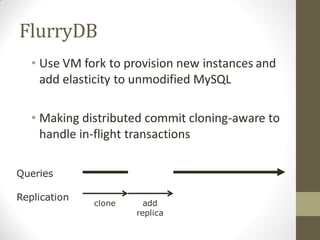



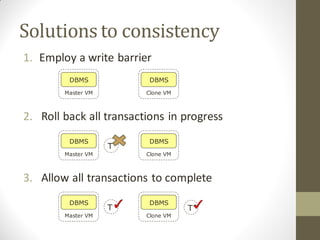

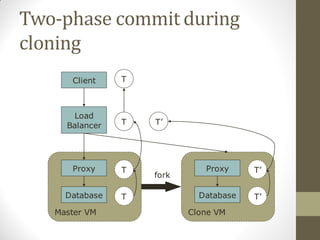




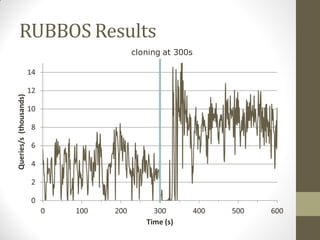





FlurryDB is a dynamically scalable relational database that uses virtual machine cloning to elastically scale database instances. It uses a two-phase commit protocol to maintain consistency when cloning database instances. The cloning process allows new database instances to be added in seconds, rather than hours, by copying the database state through virtual machine forking. FlurryDB addresses challenges in incorporating new workers into the cluster and preserving application semantics during cloning through the use of a cloning-aware proxy. It was shown to effectively scale a sample news website application under increasing load by cloning database instances.









































































