Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
moai kids
5,675 views
FluentdとRedshiftの素敵な関係
Technology
◦
Read more
15
Save
Share
Embed
Embed presentation
Download
Downloaded 23 times
1
/ 21
2
/ 21
3
/ 21
4
/ 21
5
/ 21
6
/ 21
7
/ 21
8
/ 21
9
/ 21
10
/ 21
11
/ 21
12
/ 21
13
/ 21
14
/ 21
15
/ 21
16
/ 21
17
/ 21
18
/ 21
19
/ 21
20
/ 21
21
/ 21
More Related Content
PDF
Programming Hive Reading #3
by
moai kids
PDF
Tez on EMRを試してみた
by
Satoshi Noto
PDF
ROMA のアーキテクチャと社内事例
by
Rakuten Group, Inc.
PDF
噛み砕いてKafka Streams #kafkajp
by
Yahoo!デベロッパーネットワーク
PDF
TokyoWebminig カジュアルなHadoop
by
Teruo Kawasaki
PPTX
スキーマ 付き 分散ストリーム処理 を実行可能な FlinkSQLClient の紹介
by
Sotaro Kimura
PDF
Lambdaによるクラウド型言語の実装
by
Sugawara Genki
PDF
"Programming Hive" Reading #1
by
moai kids
Programming Hive Reading #3
by
moai kids
Tez on EMRを試してみた
by
Satoshi Noto
ROMA のアーキテクチャと社内事例
by
Rakuten Group, Inc.
噛み砕いてKafka Streams #kafkajp
by
Yahoo!デベロッパーネットワーク
TokyoWebminig カジュアルなHadoop
by
Teruo Kawasaki
スキーマ 付き 分散ストリーム処理 を実行可能な FlinkSQLClient の紹介
by
Sotaro Kimura
Lambdaによるクラウド型言語の実装
by
Sugawara Genki
"Programming Hive" Reading #1
by
moai kids
What's hot
PDF
Apache Drill で見る Twitter の世界
by
Masaru Watanabe
PDF
わかってるフレームワーク Laravel
by
Masashi Shinbara
PDF
Impala データサイエンティストのための 高速大規模分散基盤 #tokyowebmining
by
Sho Shimauchi
PDF
Azure Websites で作るスケーラブルな PHP アプリケーション
by
Masashi Shinbara
PDF
EmbulkのGCS/BigQuery周りのプラグインについて
by
Satoshi Akama
PDF
Apache Arrow - A cross-language development platform for in-memory data
by
Kouhei Sutou
PDF
InfluxDB の概要 - sonots #tokyoinfluxdb
by
Naotoshi Seo
PDF
fluentd を利用した大規模ウェブサービスのロギング
by
Yuichi Tateno
PDF
serverless framework + AWS Lambda with Python
by
masahitojp
PDF
はじめてのAmazon Redshift
by
Jun Okubo
PDF
Lambda in java_20160121
by
Teruo Kawasaki
PDF
20160121 データサイエンティスト協会 木曜セミナー #5
by
Koichiro Sasaki
PDF
Kafka logをオブジェクトストレージに連携する方法まとめ
by
Keigo Suda
PDF
Kafkaを使った マイクロサービス基盤 part2 +運用して起きたトラブル集
by
matsu_chara
PDF
Apache Arrow Flight – ビッグデータ用高速データ転送フレームワーク #dbts2021
by
Kouhei Sutou
PDF
スキーマつきストリーム データ処理基盤、 Confluent Platformとは?
by
Sotaro Kimura
PDF
爆速クエリエンジン”Presto”を使いたくなる話
by
Kentaro Yoshida
PDF
Vagrant体験入門
by
Masashi Shinbara
PDF
最近のストリーム処理事情振り返り
by
Sotaro Kimura
PDF
Apache Arrow - データ処理ツールの次世代プラットフォーム
by
Kouhei Sutou
Apache Drill で見る Twitter の世界
by
Masaru Watanabe
わかってるフレームワーク Laravel
by
Masashi Shinbara
Impala データサイエンティストのための 高速大規模分散基盤 #tokyowebmining
by
Sho Shimauchi
Azure Websites で作るスケーラブルな PHP アプリケーション
by
Masashi Shinbara
EmbulkのGCS/BigQuery周りのプラグインについて
by
Satoshi Akama
Apache Arrow - A cross-language development platform for in-memory data
by
Kouhei Sutou
InfluxDB の概要 - sonots #tokyoinfluxdb
by
Naotoshi Seo
fluentd を利用した大規模ウェブサービスのロギング
by
Yuichi Tateno
serverless framework + AWS Lambda with Python
by
masahitojp
はじめてのAmazon Redshift
by
Jun Okubo
Lambda in java_20160121
by
Teruo Kawasaki
20160121 データサイエンティスト協会 木曜セミナー #5
by
Koichiro Sasaki
Kafka logをオブジェクトストレージに連携する方法まとめ
by
Keigo Suda
Kafkaを使った マイクロサービス基盤 part2 +運用して起きたトラブル集
by
matsu_chara
Apache Arrow Flight – ビッグデータ用高速データ転送フレームワーク #dbts2021
by
Kouhei Sutou
スキーマつきストリーム データ処理基盤、 Confluent Platformとは?
by
Sotaro Kimura
爆速クエリエンジン”Presto”を使いたくなる話
by
Kentaro Yoshida
Vagrant体験入門
by
Masashi Shinbara
最近のストリーム処理事情振り返り
by
Sotaro Kimura
Apache Arrow - データ処理ツールの次世代プラットフォーム
by
Kouhei Sutou
Viewers also liked
PDF
Logをs3とredshiftに格納する仕組み
by
Ken Morishita
PDF
Amazon Elasticsearch Serviceを利用したAWSのログ活用
by
真司 藤本
PDF
SmartNews の Webmining を支えるプラットフォーム
by
SmartNews, Inc.
PDF
大規模ログ分析におけるAmazon Web Servicesの活用
by
Shintaro Takemura
PDF
AWS Black Belt Techシリーズ リザーブドインスタンス & スポットインスタンス
by
Amazon Web Services Japan
PDF
Apache Mesos at Twitter (Texas LinuxFest 2014)
by
Chris Aniszczyk
PDF
Hadoop概要説明
by
Satoshi Noto
PDF
Amazon Redshiftによるリアルタイム分析サービスの構築
by
Minero Aoki
PDF
変わる!? リクルートグループのデータ解析基盤
by
Recruit Technologies
PDF
AWSでのビッグデータ分析
by
Amazon Web Services Japan
PDF
分散処理基盤ApacheHadoop入門とHadoopエコシステムの最新技術動向(OSC2015 Kansai発表資料)
by
NTT DATA OSS Professional Services
PPTX
Life of an Fluentd event
by
Kiyoto Tamura
PDF
Fluentdのお勧めシステム構成パターン
by
Kentaro Yoshida
PDF
【14-B-2】グリーを支えるデータ分析基盤の過去と現在(橋本泰一〔グリー〕)
by
Developers Summit
PDF
リアルタイム分析サービス『たべみる』を支える高可用性アーキテクチャ
by
Hiroyuki Inoue
PPTX
何故DeNAがverticaを選んだか?
by
Kenshin Yamada
PPTX
畳み込みLstm
by
tak9029
Logをs3とredshiftに格納する仕組み
by
Ken Morishita
Amazon Elasticsearch Serviceを利用したAWSのログ活用
by
真司 藤本
SmartNews の Webmining を支えるプラットフォーム
by
SmartNews, Inc.
大規模ログ分析におけるAmazon Web Servicesの活用
by
Shintaro Takemura
AWS Black Belt Techシリーズ リザーブドインスタンス & スポットインスタンス
by
Amazon Web Services Japan
Apache Mesos at Twitter (Texas LinuxFest 2014)
by
Chris Aniszczyk
Hadoop概要説明
by
Satoshi Noto
Amazon Redshiftによるリアルタイム分析サービスの構築
by
Minero Aoki
変わる!? リクルートグループのデータ解析基盤
by
Recruit Technologies
AWSでのビッグデータ分析
by
Amazon Web Services Japan
分散処理基盤ApacheHadoop入門とHadoopエコシステムの最新技術動向(OSC2015 Kansai発表資料)
by
NTT DATA OSS Professional Services
Life of an Fluentd event
by
Kiyoto Tamura
Fluentdのお勧めシステム構成パターン
by
Kentaro Yoshida
【14-B-2】グリーを支えるデータ分析基盤の過去と現在(橋本泰一〔グリー〕)
by
Developers Summit
リアルタイム分析サービス『たべみる』を支える高可用性アーキテクチャ
by
Hiroyuki Inoue
何故DeNAがverticaを選んだか?
by
Kenshin Yamada
畳み込みLstm
by
tak9029
Similar to FluentdとRedshiftの素敵な関係
PDF
社内向けTech Talk資料~Fluentdの基本紹介~
by
Daisuke Ikeda
PDF
Fluentd Casual Talks LT #fluentd #fluentdcasual
by
Hitoshi Asai
PDF
Fluentd casual
by
oranie Narut
PDF
[よくわかるクラウドデータベース] リクルートにおけるRedshift導入・活用事例
by
Amazon Web Services Japan
PPTX
Fluentd+MongoDB+Groovy
by
Daisuke Ando
PDF
FluentdとAWSを使ったログの運用
by
Keisuke Izumiya
PPTX
Game Architecture Trends in Tokyo Kansai Social Game Study#5
by
Yasuhiro Matsuo
PDF
Webサーバ勉強会#5
by
oranie Narut
PDF
Amazon Kinesis Familyを活用したストリームデータ処理
by
Amazon Web Services Japan
PDF
Rails3+devise,nginx,fluent,S3構成でのアクセスログ収集と蓄積
by
Takeshi Mikami
PDF
Fluentd in #tkrk10
by
SATOSHI TAGOMORI
PDF
スマートニュースの世界展開を支えるログ解析基盤
by
Takumi Sakamoto
PDF
20分でわかるHBase
by
Sho Shimauchi
PDF
既存システムへの新技術活用法 ~fluntd/MongoDB~
by
じゅん なかざ
PDF
FluentdとGrothForecastをインストールする
by
regret raym
PDF
データマート対応した話
by
株式会社オプト 仙台ラボラトリ
PDF
Fluentdへようこそ
by
Manabu Shinsaka
PDF
新卒配属2ヶ月で 新規プロジェクトの インフラ構成を考えた話_20250124_FinaTech
by
ws060m
PPTX
Fluentd+elasticsearch+kibana(fluentd編)
by
Daisuke Kikuchi
PDF
新宿鮫もくもく勉強会第10回目
by
晋也 古渡
社内向けTech Talk資料~Fluentdの基本紹介~
by
Daisuke Ikeda
Fluentd Casual Talks LT #fluentd #fluentdcasual
by
Hitoshi Asai
Fluentd casual
by
oranie Narut
[よくわかるクラウドデータベース] リクルートにおけるRedshift導入・活用事例
by
Amazon Web Services Japan
Fluentd+MongoDB+Groovy
by
Daisuke Ando
FluentdとAWSを使ったログの運用
by
Keisuke Izumiya
Game Architecture Trends in Tokyo Kansai Social Game Study#5
by
Yasuhiro Matsuo
Webサーバ勉強会#5
by
oranie Narut
Amazon Kinesis Familyを活用したストリームデータ処理
by
Amazon Web Services Japan
Rails3+devise,nginx,fluent,S3構成でのアクセスログ収集と蓄積
by
Takeshi Mikami
Fluentd in #tkrk10
by
SATOSHI TAGOMORI
スマートニュースの世界展開を支えるログ解析基盤
by
Takumi Sakamoto
20分でわかるHBase
by
Sho Shimauchi
既存システムへの新技術活用法 ~fluntd/MongoDB~
by
じゅん なかざ
FluentdとGrothForecastをインストールする
by
regret raym
データマート対応した話
by
株式会社オプト 仙台ラボラトリ
Fluentdへようこそ
by
Manabu Shinsaka
新卒配属2ヶ月で 新規プロジェクトの インフラ構成を考えた話_20250124_FinaTech
by
ws060m
Fluentd+elasticsearch+kibana(fluentd編)
by
Daisuke Kikuchi
新宿鮫もくもく勉強会第10回目
by
晋也 古渡
More from moai kids
PDF
中国最新ニュースアプリ事情
by
moai kids
PDF
Twitterのsnowflakeについて
by
moai kids
PDF
Programming Hive Reading #4
by
moai kids
PDF
Casual Compression on MongoDB
by
moai kids
PDF
Introduction to MongoDB
by
moai kids
PDF
Hadoop Conference Japan 2011 Fallに行ってきました
by
moai kids
PDF
HBase本輪読会資料(11章)
by
moai kids
PDF
snappyについて
by
moai kids
PDF
第四回月次セミナー(公開版)
by
moai kids
KEY
第三回月次セミナー(公開版)
by
moai kids
PDF
Pythonで自然言語処理
by
moai kids
PDF
HandlerSocket plugin Client for Javaとそれを用いたベンチマーク
by
moai kids
PDF
Yammer試用レポート(公開版)
by
moai kids
PDF
掲示板時間軸コーパスを用いたワードトレンド解析(公開版)
by
moai kids
PDF
中国と私(仮題)
by
moai kids
PDF
不自然言語処理コンテストLT資料
by
moai kids
PDF
n-gramコーパスを用いた類義語自動獲得手法について
by
moai kids
KEY
Analysis of ‘lang-8’
by
moai kids
PDF
Androidの音声認識とテキスト読み上げ機能について
by
moai kids
KEY
Amebaサーチ使用傾向
by
moai kids
中国最新ニュースアプリ事情
by
moai kids
Twitterのsnowflakeについて
by
moai kids
Programming Hive Reading #4
by
moai kids
Casual Compression on MongoDB
by
moai kids
Introduction to MongoDB
by
moai kids
Hadoop Conference Japan 2011 Fallに行ってきました
by
moai kids
HBase本輪読会資料(11章)
by
moai kids
snappyについて
by
moai kids
第四回月次セミナー(公開版)
by
moai kids
第三回月次セミナー(公開版)
by
moai kids
Pythonで自然言語処理
by
moai kids
HandlerSocket plugin Client for Javaとそれを用いたベンチマーク
by
moai kids
Yammer試用レポート(公開版)
by
moai kids
掲示板時間軸コーパスを用いたワードトレンド解析(公開版)
by
moai kids
中国と私(仮題)
by
moai kids
不自然言語処理コンテストLT資料
by
moai kids
n-gramコーパスを用いた類義語自動獲得手法について
by
moai kids
Analysis of ‘lang-8’
by
moai kids
Androidの音声認識とテキスト読み上げ機能について
by
moai kids
Amebaサーチ使用傾向
by
moai kids
FluentdとRedshiftの素敵な関係
1.
FluentdとRedshiftの 素敵な関係 第18回 AWS User
Group - Japan 東京勉強会 @just_do_neet
2.
第18回 AWS User
Group - Japan 東京勉強会 Redshiftは便利 •他の登壇者の方々が熱く語られていると想います ので割愛...... •とはいえ不満点もある •データをいかにS3/Redshiftまで運ぶか •大量のデータを一括登録すると時間がかかる •かといって細切れだと面倒 •自前でコントロールしようとすると手間 2
3.
第18回 AWS User
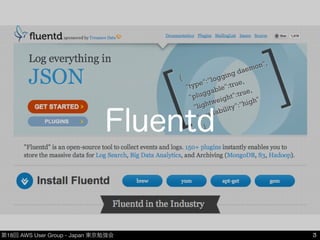
Group - Japan 東京勉強会 Fluentd 3
4.
第18回 AWS User
Group - Japan 東京勉強会 Fluentd •OSSのlog collector •導入のし易さ、性能、信頼性、拡張性++ •豊富なplugin •fluent-plugin-s3 •fluent-plugin-redshift 4
5.
第18回 AWS User
Group - Japan 東京勉強会 fluent-plugin-redshift 5 •https://github.com/hapyrus/fluent-plugin-redshift/ •Redshiftにデータを登録できるFluentd plugin •CSV/TSV/JSONなどに対応 •Redshiftへのデータ反映のタイミングを調整可能 (buffer_chunk_limit / flush_interval) •chunk単位でS3にデータ保存→copyコマンドでRedshift に反映
6.
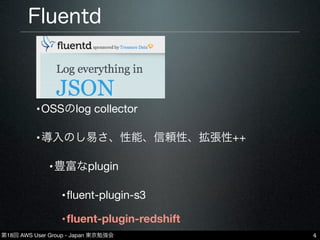
第18回 AWS User
Group - Japan 東京勉強会 fluent-plugin-redshift 6 •https://github.com/hapyrus/fluent-plugin-redshift/ •Fluentdを介してRedshiftにデータを登録できる plugin •CSV/TSV/JSONなどに対応 •Redshiftへのデータ反映のタイミングを調整可能 (buffer_chunk_limit / flush_interval) •chunk単位でS3にデータ保存→copyコマンドで Redshiftに反映 <match my.tag> type redshift # s3 (for copying data to redshift) aws_key_id YOUR_AWS_KEY_ID aws_sec_key YOUR_AWS_SECRET_KEY s3_bucket YOUR_S3_BUCKET s3_endpoint YOUR_S3_BUCKET_END_POINT path YOUR_S3_PATH timestamp_key_format year=%Y/month=%m/day=%d/hour=%H/%Y%m%d-‐%H%M # redshift redshift_host YOUR_AMAZON_REDSHIFT_CLUSTER_END_POINT redshift_port YOUR_AMAZON_REDSHIFT_CLUSTER_PORT redshift_dbname YOUR_AMAZON_REDSHIFT_CLUSTER_DATABASE_NAME redshift_user YOUR_AMAZON_REDSHIFT_CLUSTER_USER_NAME redshift_password YOUR_AMAZON_REDSHIFT_CLUSTER_PASSWORD redshift_schemaname YOUR_AMAZON_REDSHIFT_CLUSTER_TARGET_SCHEMA_NAME redshift_tablename YOUR_AMAZON_REDSHIFT_CLUSTER_TARGET_TABLE_NAME file_type [tsv|csv|json|msgpack] # buffer buffer_type file buffer_path /var/log/fluent/redshift flush_interval 15m buffer_chunk_limit 1g </match> redshift plugin 設定例
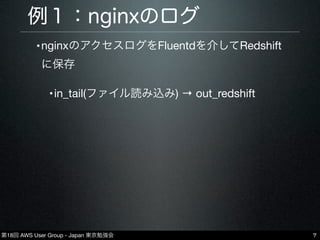
7.
第18回 AWS User
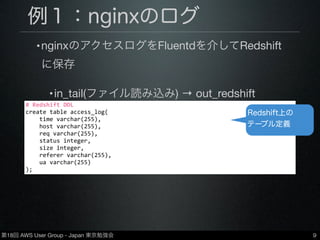
Group - Japan 東京勉強会 例1:nginxのログ •nginxのアクセスログをFluentdを介してRedshift に保存 •in_tail(ファイル読み込み) → out_redshift 7
8.
第18回 AWS User
Group - Japan 東京勉強会 例1:nginxのログ •nginxのアクセスログをFluentdを介してRedshift に保存 •in_tail(ファイル読み込み) → out_redshift 8 log_format ltsv 'time:$time_localt' 'host:$remote_addrt' 'req:$requestt' 'status:$statust' 'size:$body_bytes_sentt' 'referer:$http_referert' 'ua:$http_user_agentt'; time:02/Oct/2013:20:32:31 +0900 host:xxx.xxx.xxx.xxx req:GET /musicians/ famous/ HTTP/1.1 status:200 size:2172 referer:http://www.sada.co.jp/ index.html ua:Mozilla/5.0 (iPhone; CPU iPhone OS 7_0_2 like Mac OS X) AppleWebKit/537.51.1 (KHTML, like Gecko) Version/7.0 Mobile/11A501 Safari/ 9537.53 nginxのログフォー マット
9.
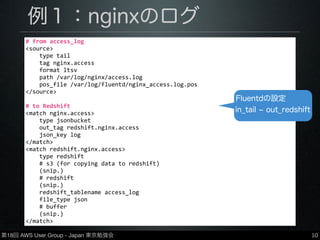
第18回 AWS User
Group - Japan 東京勉強会 例1:nginxのログ •nginxのアクセスログをFluentdを介してRedshift に保存 •in_tail(ファイル読み込み) → out_redshift 9 # Redshift DDL create table access_log( time varchar(255), host varchar(255), req varchar(255), status integer, size integer, referer varchar(255), ua varchar(255) ); Redshift上の テーブル定義
10.
第18回 AWS User
Group - Japan 東京勉強会 例1:nginxのログ •nginxのアクセスログをFluentdを介してRedshift に保存 •in_tail(ファイル読み込み) → out_redshift 10 # from access_log <source> type tail tag nginx.access format ltsv path /var/log/nginx/access.log pos_file /var/log/fluentd/nginx_access.log.pos </source> # to Redshift <match nginx.access> type jsonbucket out_tag redshift.nginx.access json_key log </match> <match redshift.nginx.access> type redshift # s3 (for copying data to redshift) (snip.) # redshift (snip.) redshift_tablename access_log file_type json # buffer (snip.) </match> Fluentdの設定 in_tail out_redshift
11.
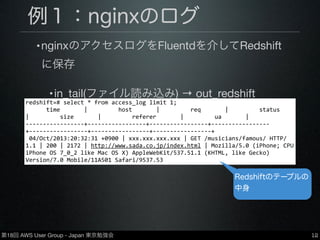
第18回 AWS User
Group - Japan 東京勉強会 例1:nginxのログ •nginxのアクセスログをFluentdを介してRedshift に保存 •in_tail(ファイル読み込み) → out_redshift 11 #Fluentd log_file 2013-‐10-‐04 20:33:16 +0900 [info]: completed copying to redshift. s3_uri=s3:// xxxxxx/redshift/access_log/year=2013/month=10/day=04/ hour=20/20131004-‐2033_01.gz Fluentdのlog Redshiftへの書き込 み成功時に出力
12.
第18回 AWS User
Group - Japan 東京勉強会 例1:nginxのログ •nginxのアクセスログをFluentdを介してRedshift に保存 •in_tail(ファイル読み込み) → out_redshift 12 redshift=# select * from access_log limit 1; time | host | req | status | size | referer | ua | -‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐+-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐+-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐+-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐ +-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐+-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐+-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐+ 04/Oct/2013:20:32:31 +0900 | xxx.xxx.xxx.xxx | GET /musicians/famous/ HTTP/ 1.1 | 200 | 2172 | http://www.sada.co.jp/index.html | Mozilla/5.0 (iPhone; CPU iPhone OS 7_0_2 like Mac OS X) AppleWebKit/537.51.1 (KHTML, like Gecko) Version/7.0 Mobile/11A501 Safari/9537.53 Redshiftのテーブルの 中身
13.
第18回 AWS User
Group - Japan 東京勉強会 例2:地域情報の付与 •元のデータはそのまま、Fluentd内でデータを加 工してRedshiftに保存したい •fluent-plugin-record-modifier •fluent-plugin-time_parser •fluent-plugin-reassemble •fluent-plugin-geoip 13
14.
第18回 AWS User
Group - Japan 東京勉強会 例2:地域情報の付与 •https://github.com/y-ken/fluent-plugin-geoip •MaxMind社提供のgeoipデータベースを用いて、 IPアドレスから地域情報(緯度・経度・都市名) を取得しデータに付与 •データベースは有償・無償ともに使用可 14
15.
第18回 AWS User
Group - Japan 東京勉強会 例2:地域情報の付与 •https://github.com/y-ken/fluent-plugin-geoip •MaxMind社提供のgeoipデータベースを用いて、 IPアドレスから地域情報(緯度・経度・都市名) を取得しデータに付与 •データベースは有償・無償ともに使用可 15 # Redshift DDL create table access_log( time varchar(255), host varchar(255), req varchar(255), status integer, size integer, referer varchar(255), ua varchar(255), city varchar(100), latitude real, longitude real ); Redshift上の テーブル定義 (地域情報を拡張)
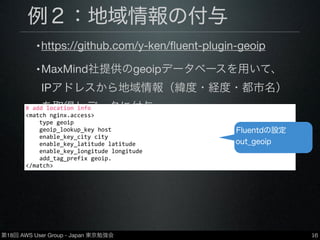
16.
第18回 AWS User
Group - Japan 東京勉強会 例2:地域情報の付与 •https://github.com/y-ken/fluent-plugin-geoip •MaxMind社提供のgeoipデータベースを用いて、 IPアドレスから地域情報(緯度・経度・都市名) を取得しデータに付与 •データベースは有償・無償ともに使用可 16 # add location info <match nginx.access> type geoip geoip_lookup_key host enable_key_city city enable_key_latitude latitude enable_key_longitude longitude add_tag_prefix geoip. </match> Fluentdの設定 out_geoip
17.
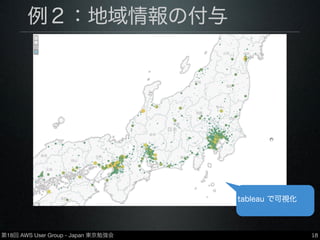
第18回 AWS User
Group - Japan 東京勉強会 例2:地域情報の付与 •https://github.com/y-ken/fluent-plugin-geoip •MaxMind社提供のgeoipデータベースを用いて、 IPアドレスから地域情報(緯度・経度・都市名) を取得しデータに付与 •データベースは有償・無償ともに使用可 17 redshift=# select * from get_background_links limit 1; time | host | req | status | size | referer | ua | city | latitude | longitude | -‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐+-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐+-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐+-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐ +-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐+-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐+-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐+-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐ +-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐+-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐+ 04/Oct/2013:20:32:31 +0900 | xxx.xxx.xxx.xxx | GET /musicians/famous/ HTTP/ 1.1 | 200 | 2172 | http://www.sada.co.jp/index.html | Mozilla/5.0 (iPhone; CPU iPhone OS 7_0_2 like Mac OS X) AppleWebKit/537.51.1 (KHTML, like Gecko) Version/7.0 Mobile/11A501 Safari/9537.53 | Osaki | 38.5887 | 140.973 Redshiftのテーブルの 中身(地域情報を拡張)
18.
第18回 AWS User
Group - Japan 東京勉強会 例2:地域情報の付与 •https://github.com/y-ken/fluent-plugin-geoip •MaxMind社提供のgeoipデータベースを用いて、 IPアドレスから地域情報(緯度・経度・都市名) を取得しデータに付与 •データベースは有償・無償ともに使用可 18 tableau で可視化
19.
まとめ
20.
第18回 AWS User
Group - Japan 東京勉強会 •Fluentd x Redshiftについて。 •Fluentdを使うとデータの登録や加工が思いのまま です。 •便利なので使いましょう。 •環境構築が面倒な方向けには「flydata」という便 利なサービスがあるらしいですよ まとめ 20
21.
Thanks for your
listening :)
Download





![第18回 AWS User Group - Japan 東京勉強会
fluent-plugin-redshift
6
•https://github.com/hapyrus/fluent-plugin-redshift/
•Fluentdを介してRedshiftにデータを登録できる
plugin
•CSV/TSV/JSONなどに対応
•Redshiftへのデータ反映のタイミングを調整可能
(buffer_chunk_limit / flush_interval)
•chunk単位でS3にデータ保存→copyコマンドで
Redshiftに反映
<match
my.tag>
type
redshift
#
s3
(for
copying
data
to
redshift)
aws_key_id
YOUR_AWS_KEY_ID
aws_sec_key
YOUR_AWS_SECRET_KEY
s3_bucket
YOUR_S3_BUCKET
s3_endpoint
YOUR_S3_BUCKET_END_POINT
path
YOUR_S3_PATH
timestamp_key_format
year=%Y/month=%m/day=%d/hour=%H/%Y%m%d-‐%H%M
#
redshift
redshift_host
YOUR_AMAZON_REDSHIFT_CLUSTER_END_POINT
redshift_port
YOUR_AMAZON_REDSHIFT_CLUSTER_PORT
redshift_dbname
YOUR_AMAZON_REDSHIFT_CLUSTER_DATABASE_NAME
redshift_user
YOUR_AMAZON_REDSHIFT_CLUSTER_USER_NAME
redshift_password
YOUR_AMAZON_REDSHIFT_CLUSTER_PASSWORD
redshift_schemaname
YOUR_AMAZON_REDSHIFT_CLUSTER_TARGET_SCHEMA_NAME
redshift_tablename
YOUR_AMAZON_REDSHIFT_CLUSTER_TARGET_TABLE_NAME
file_type
[tsv|csv|json|msgpack]
#
buffer
buffer_type
file
buffer_path
/var/log/fluent/redshift
flush_interval
15m
buffer_chunk_limit
1g
</match>
redshift plugin
設定例](https://image.slidesharecdn.com/20131004redshiftpublic-131004025923-phpapp01/85/Fluentd-Redshift-6-320.jpg)
![第18回 AWS User Group - Japan 東京勉強会
例1:nginxのログ
•nginxのアクセスログをFluentdを介してRedshift
に保存
•in_tail(ファイル読み込み) → out_redshift
11
#Fluentd
log_file
2013-‐10-‐04
20:33:16
+0900
[info]:
completed
copying
to
redshift.
s3_uri=s3://
xxxxxx/redshift/access_log/year=2013/month=10/day=04/
hour=20/20131004-‐2033_01.gz
Fluentdのlog
Redshiftへの書き込
み成功時に出力](https://image.slidesharecdn.com/20131004redshiftpublic-131004025923-phpapp01/85/Fluentd-Redshift-11-320.jpg)


















































![[よくわかるクラウドデータベース] リクルートにおけるRedshift導入・活用事例](https://cdn.slidesharecdn.com/ss_thumbnails/20140117aws-140128175458-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)



































