Downloaded 41 times




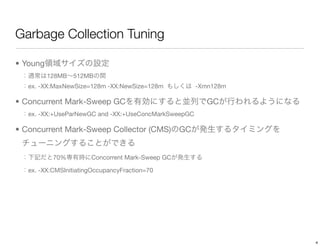




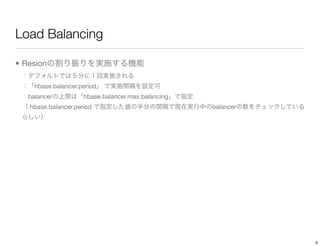


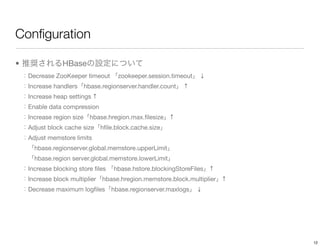

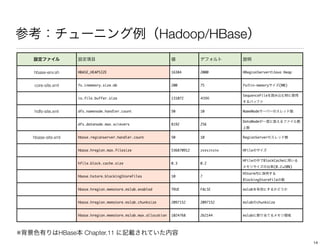
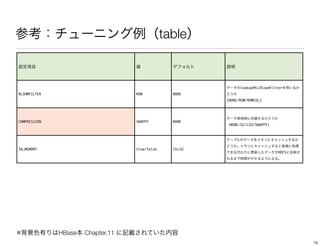
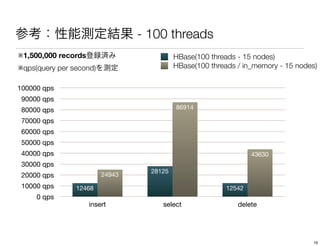
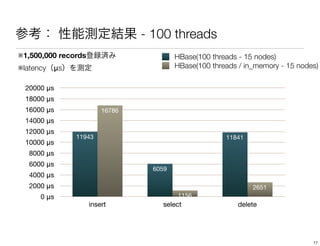
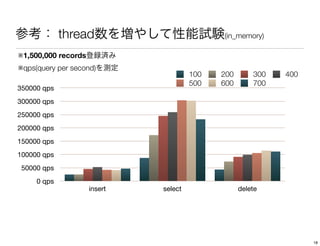
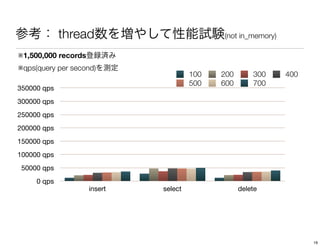

The document discusses performance tuning for HBase. It provides tips for garbage collection tuning, using memstore local allocation buffers, compression, optimizing splits and compactions, load balancing, merging regions, best client API practices, and configuration settings. It also recommends using tools like the HBase PerformanceEvaluation tool and YCSB for load testing HBase.



























































































