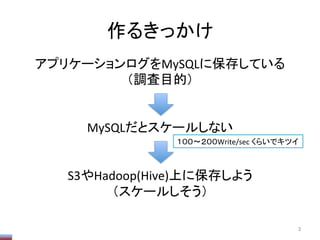
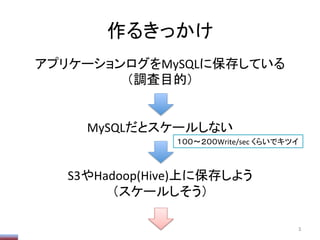
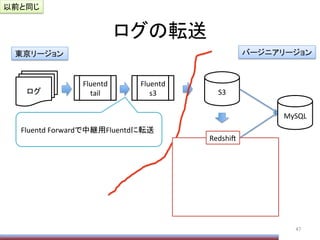
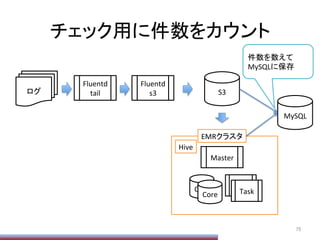
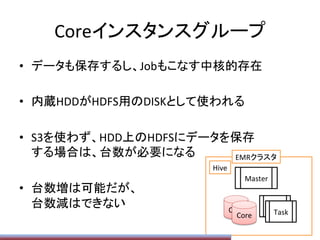
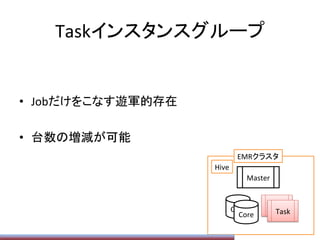
Hiveの動的ParPPonの上限
ParPPon数の上限がデフォで1000なので、
SET
hive.exec.dynamic.parPPon=true;
SET
hive.exec.dynamic.parPPon.mode=nonstrict;
SET
hive.exec.max.dynamic.parPPons=1000000;
SET
hive.exec.max.dynamic.parPPons.pernode=1000000;
SET
hive.exec.max.created.files=15000000;
みたいにして増やしておく必要がある
(数は適当。デメリット等は不明。単に増えると遅いのだ
と思う)
105
106.
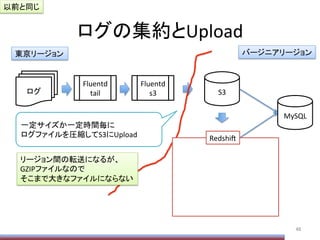
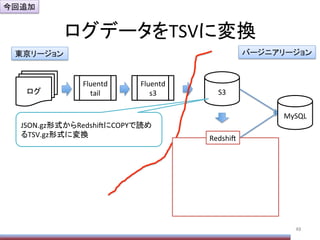
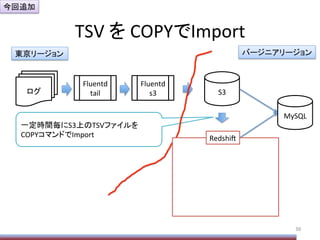
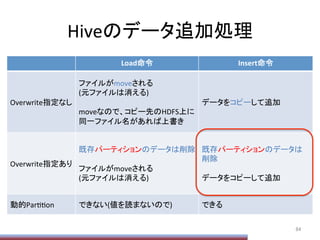
Hive実行時のOpPonメモ
106
SET
hive.exec.dynamic.parPPon=true;
SET
hive.exec.dynamic.parPPon.mode=nonstrict;
SET
hive.exec.max.dynamic.parPPons=1000000;
SET
hive.exec.max.dynamic.parPPons.pernode=1000000;
SET
hive.exec.max.created.files=15000000;
SET
hive.exec.compress.output=true;
SET
io.seqfile.compression.type=BLOCK;
SET
hive.exec.compress.intermediate=true;
SET
hive.intermediate.compression.type=BLOCK;
SET
mapred.output.compress=true;
SET
mapred.output.compression.type=BLOCK;
SET
mapred.output.compression.codec=org.apache.hadoop.io.compress.SnappyCodec;
SET
hive.merge.mapfiles=true;
SET
hive.merge.mapredfiles=true;
SET
hive.merge.size.per.task=256000000;
SET
hive.merge.size.smallfiles.avgsize=16000000;

















































































![[Oracle DBA & Developer Day 2012] 高可用性システムに適した管理性と性能を向上させるASM と RMAN の魅力](https://cdn.slidesharecdn.com/ss_thumbnails/ma-4print20121205-200702094006-thumbnail.jpg?width=640&height=640&fit=bounds)


![[20171019 三木会] データベース・マイグレーションについて by 株式会社シー・エス・イー 藤井 元雄 氏](https://cdn.slidesharecdn.com/ss_thumbnails/dbmigration-171030091652-thumbnail.jpg?width=640&height=640&fit=bounds)




















![[db tech showcase Tokyo 2015] A14:Amazon Redshiftの元となったスケールアウト型カラムナーDB徹底解説 その...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015a14actian-matrix-insight-technology-150618094408-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)














![[db tech showcase Tokyo 2015] A32:Amazon Redshift Deep Dive by アマゾン データ サービス ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015a32amazon-redshiftamazondataservicejapan-150623010123-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)










