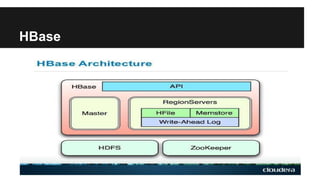
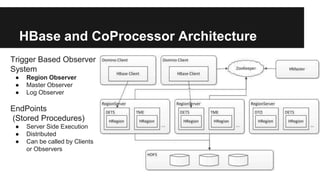
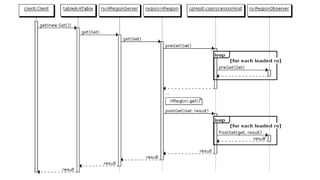
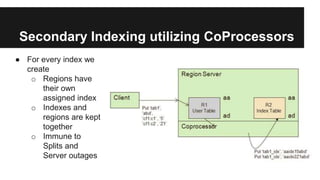
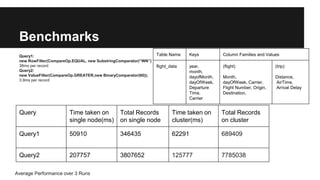
This document discusses secondary indexing in HBase. It introduces HBase and how scans work. Secondary indexes are created to avoid full table scans by storing row keys corresponding to indexed columns in a separate table. CoProcessors can be used to implement secondary indexes by assigning index regions and keeping them in sync with data regions. Benchmark results show secondary indexing improves query performance at the cost of extra storage and processing overhead from CoProcessors. Challenges include indexing across regions and handling region splits.