Downloaded 397 times








![© 2016 IBM Corporation11
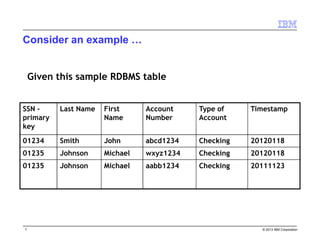
How are tables stored in HBase?
Rows
Table–LogicalView
A
.
.
K
.
.
T
.
.
Z
Keys:[A-D]
Keys:[E-H]
Keys:[S-V]
Keys:[N-R]
Keys:[I-M]
Keys:[W-Z]
Region Server 1 Region Server 2 Region Server 3
Region
Region
Region
Region
Region
Region
Auto-Sharded Regions
The data is “sharded”
Each shard contains all the data in a key-range](https://image.slidesharecdn.com/hbaseandbigsql-public-150401145240-conversion-gate01/85/Big-Data-Big-SQL-and-HBase-11-320.jpg)













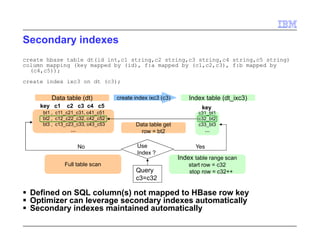


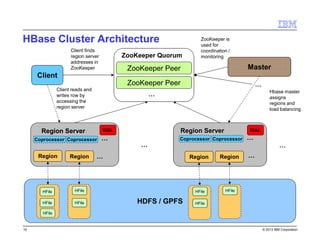
The document provides a technical introduction to Big SQL and HBase, detailing their integration with Hadoop for SQL professionals. It covers HBase as a NoSQL data store, supported operations like table creation and querying, and best practices for efficient database design. The document also addresses advanced topics like secondary indexing, salting to minimize hotspots, and various considerations for managing data storage and I/O.


















































































