Download as PDF, PPTX












This document discusses Apache Atlas, an open source metadata management and governance framework for Hadoop ecosystems. It provides an overview of Atlas' features for modeling and classifying metadata, integrating with components like Hive and Ranger, and its architecture using a graph database and Kafka messaging. The document also outlines use cases for lineage tracking, compliance, and data governance as well as the roadmap for additional component integration and metadata export/import capabilities.
Overview of Apache Atlas, its inception in 2015, and its function as a governance framework for Hadoop.
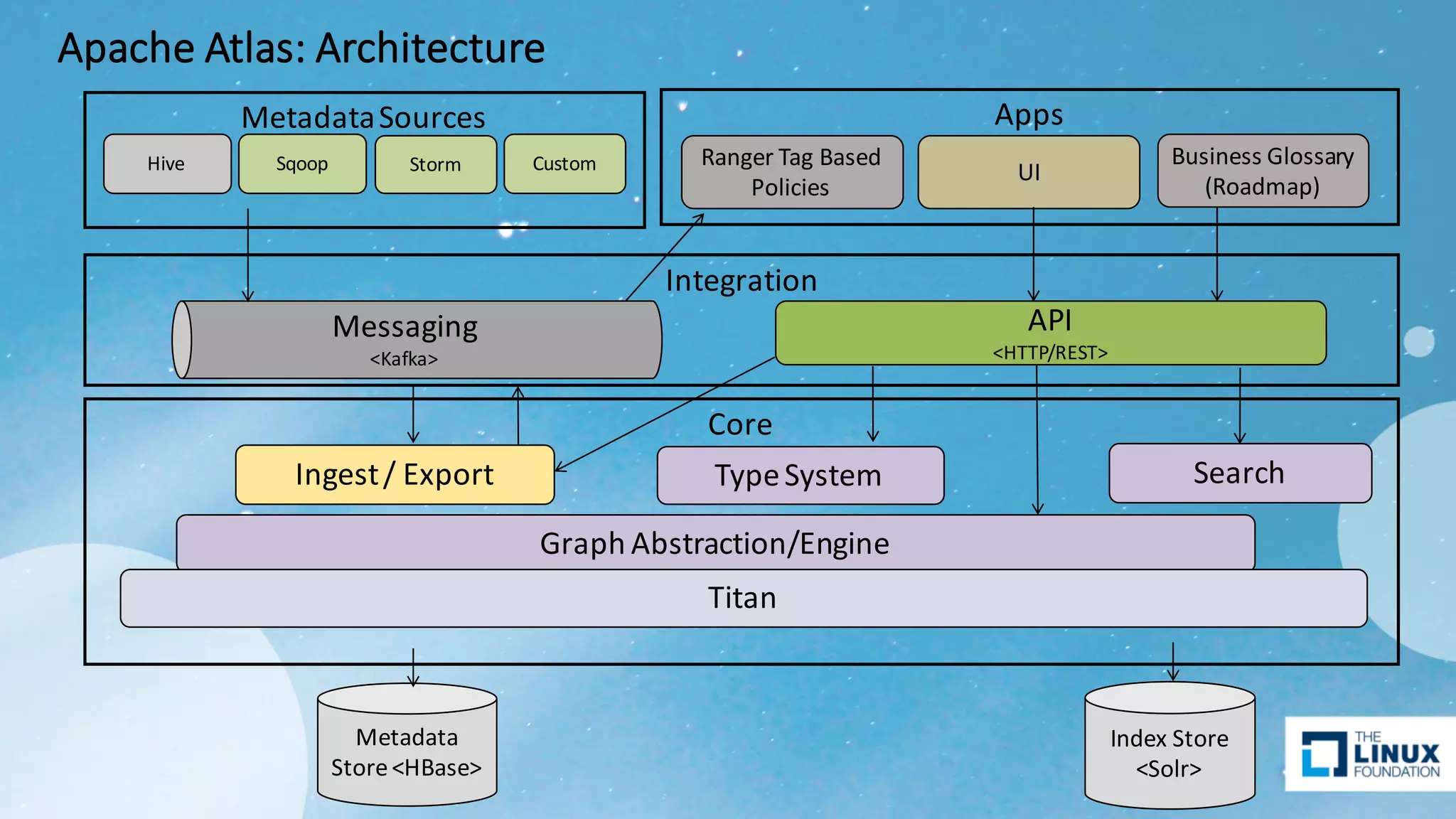
Details on Atlas architecture, core components, integrations, and common governance use cases in ETL scenarios.
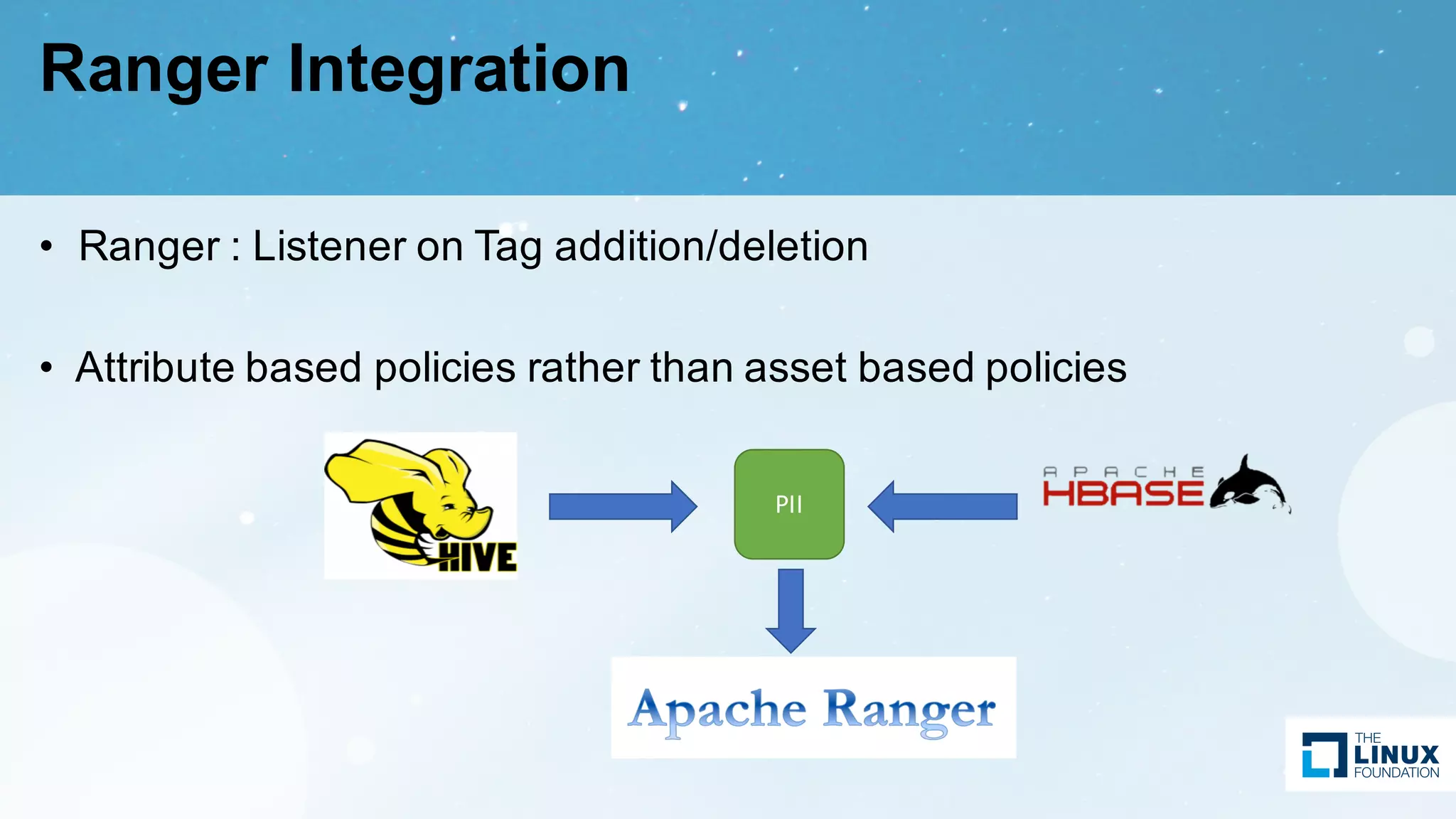
Discussed use cases for compliance, security policies, lineage, and integration with Ranger for metadata management.
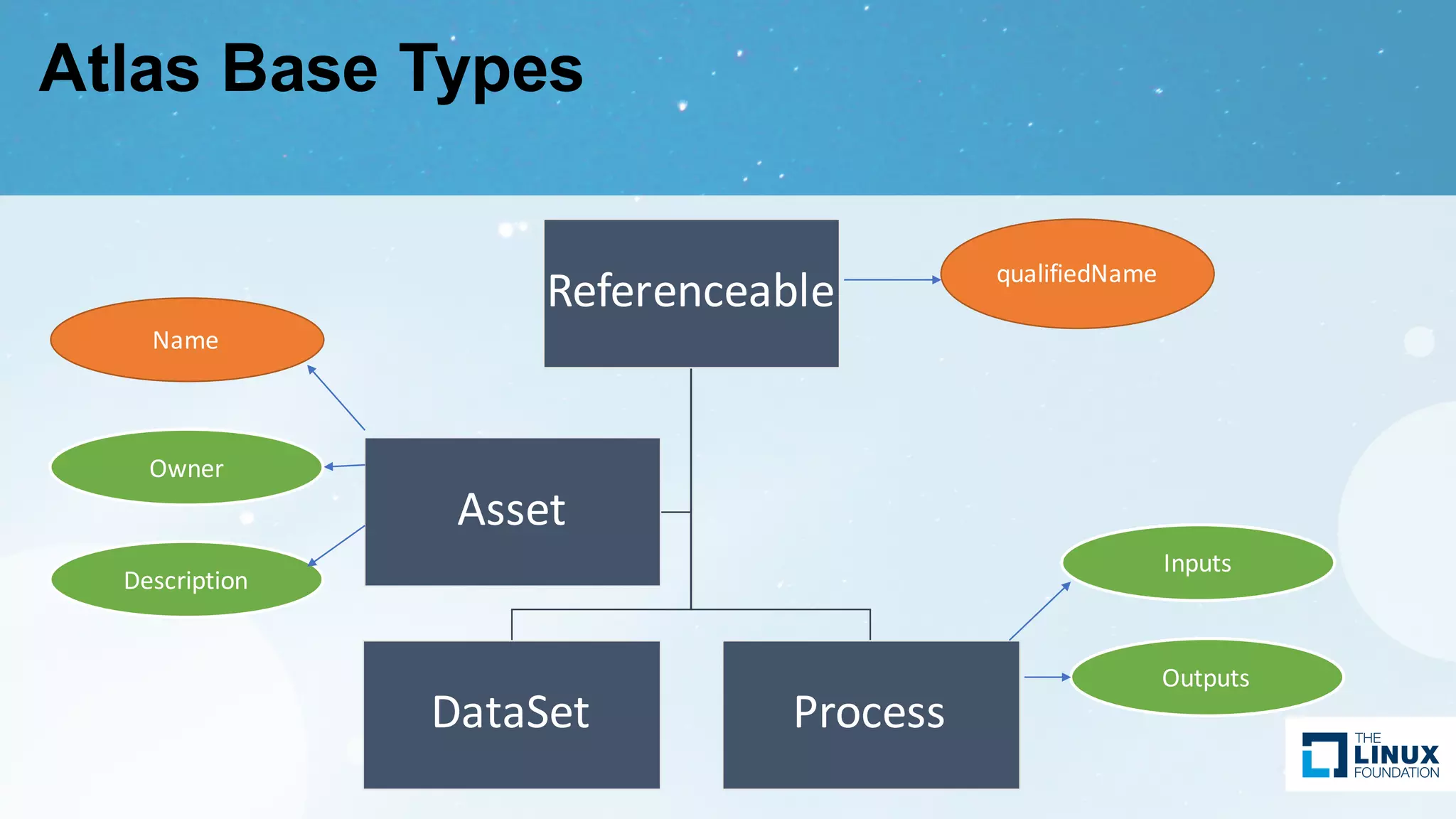
Explanation of the type system for metadata in Atlas, along with base types and attributes to be stored.
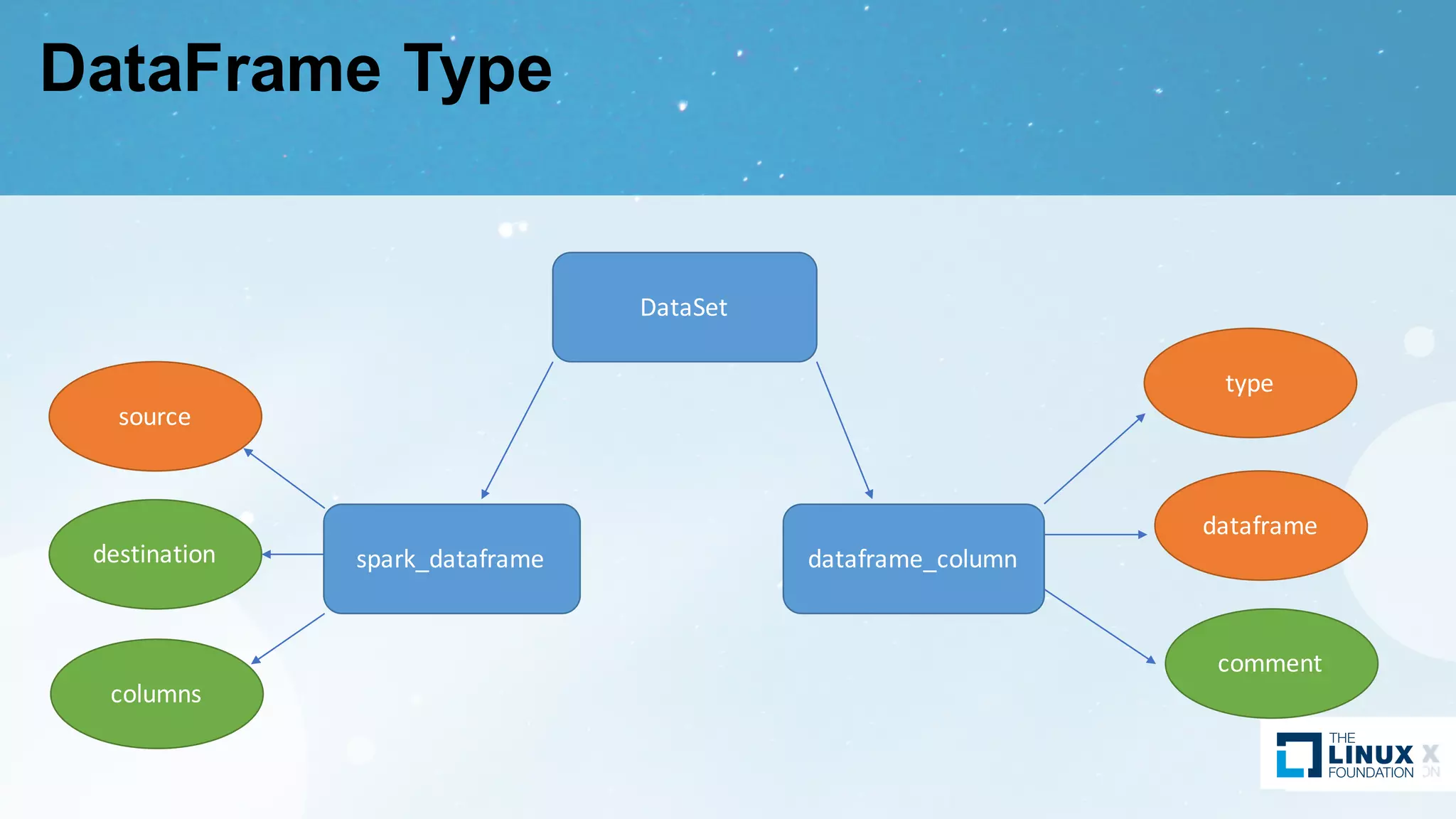
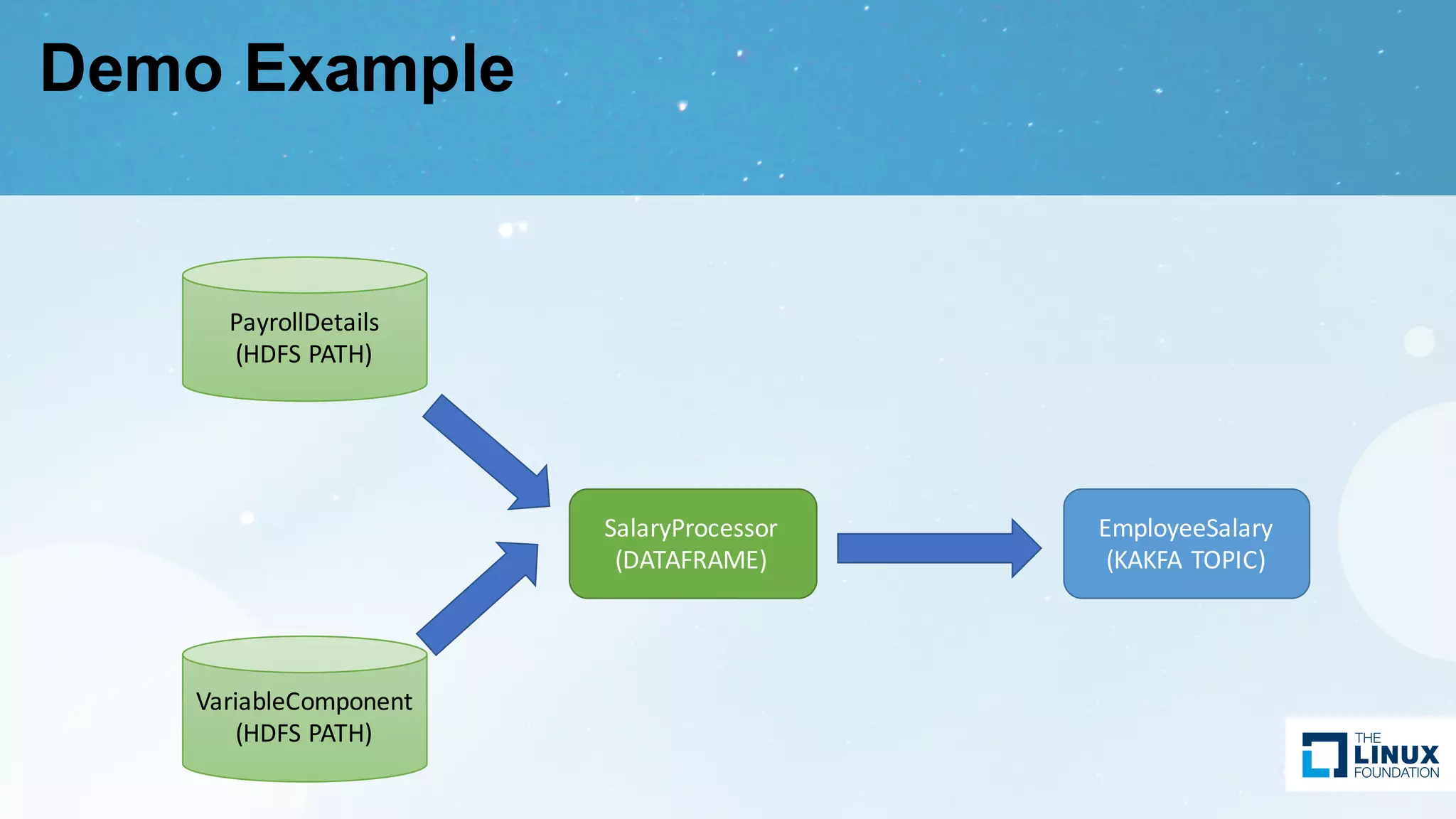
Introduction to DataFrames in Spark and modeling their type, including graphical examples of DataFrame types and entities.
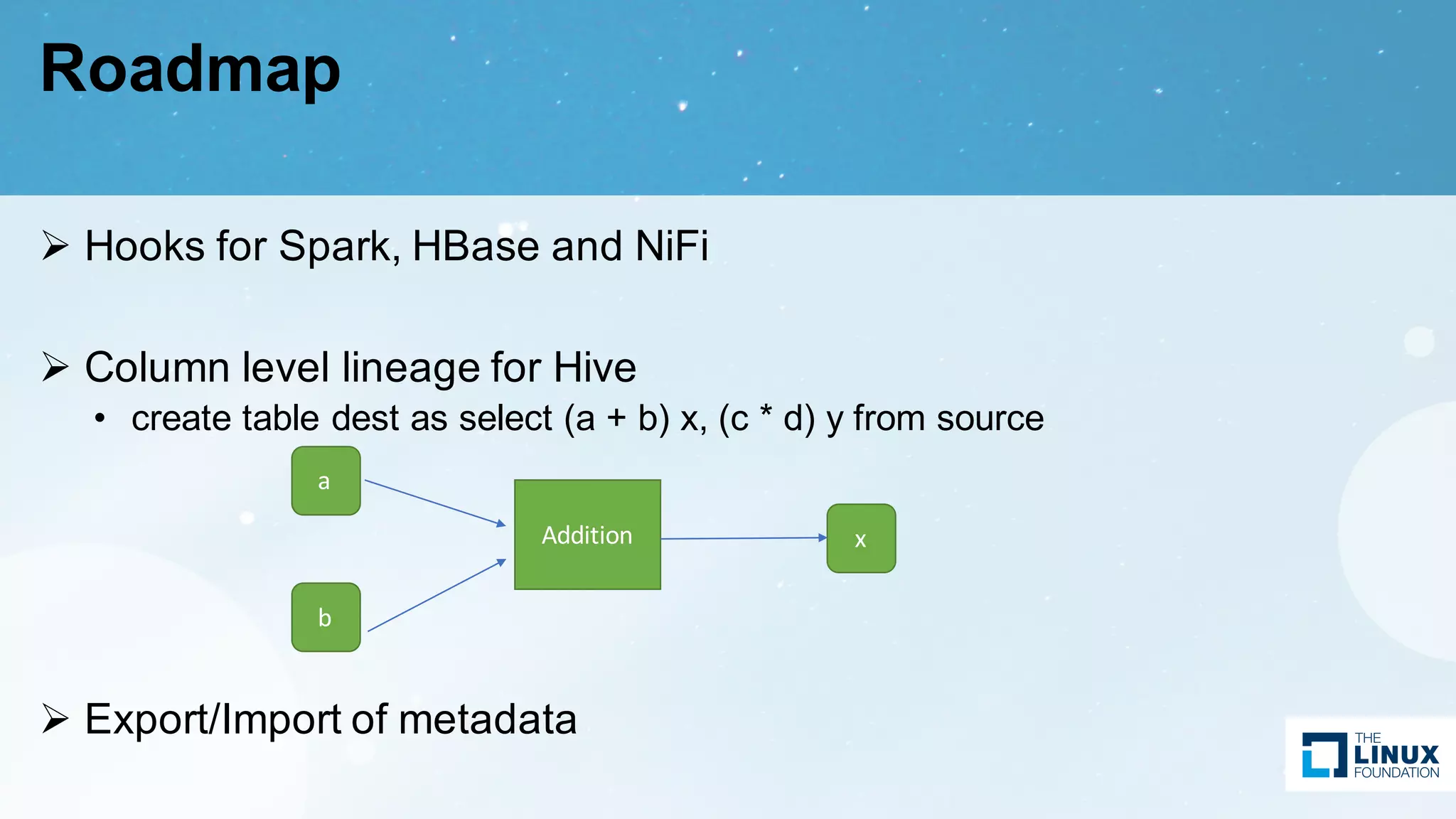
Design considerations of data hooks, roadmap for future improvements in services such as Spark and Hive.
Information on how to contribute to the Apache Atlas project, including links to resources and opening the floor for questions.












































![The Evolution of Metadata: LinkedIn's Story [Strata NYC 2019]](https://cdn.slidesharecdn.com/ss_thumbnails/metadatajourneylinkedinstratapublic-190930045839-thumbnail.jpg?width=640&height=640&fit=bounds)






















