Downloaded 27 times




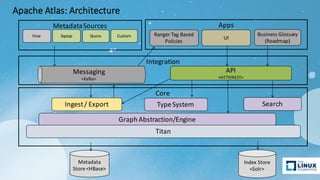


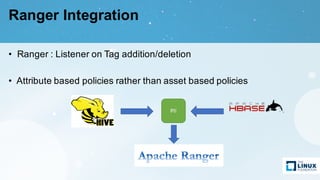

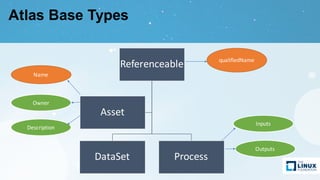

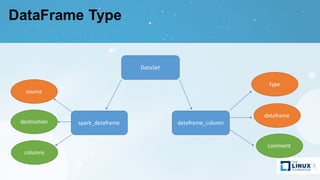
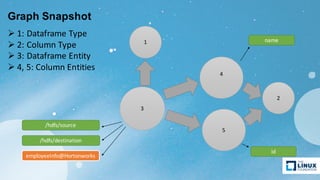
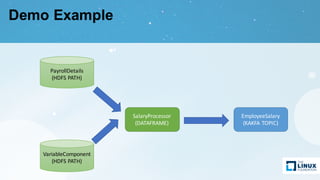




Apache Atlas is a governance and metadata framework for Hadoop, providing capabilities for data asset management and compliance tracking. It supports metadata modeling, classification, and lineage tracking while integrating with various data processing tools like Hive, Storm, and custom applications. The document outlines its architecture, use cases, and future roadmap, aiming to enhance data governance efficiency across organizations.










































![The Evolution of Metadata: LinkedIn's Story [Strata NYC 2019]](https://cdn.slidesharecdn.com/ss_thumbnails/metadatajourneylinkedinstratapublic-190930045839-thumbnail.jpg?width=640&height=640&fit=bounds)
























