Download to read offline






![Aggregations
The library contains books.
10
Library Book
Specific
Patterns
Requirements with patterns,“contains”, “made up of”,
“include”, […]](https://image.slidesharecdn.com/models16presentationv2-161013094918/75/Extracting-Domain-Models-from-Natural-Language-Requirements-Approach-and-Industrial-Evaluation-10-2048.jpg)



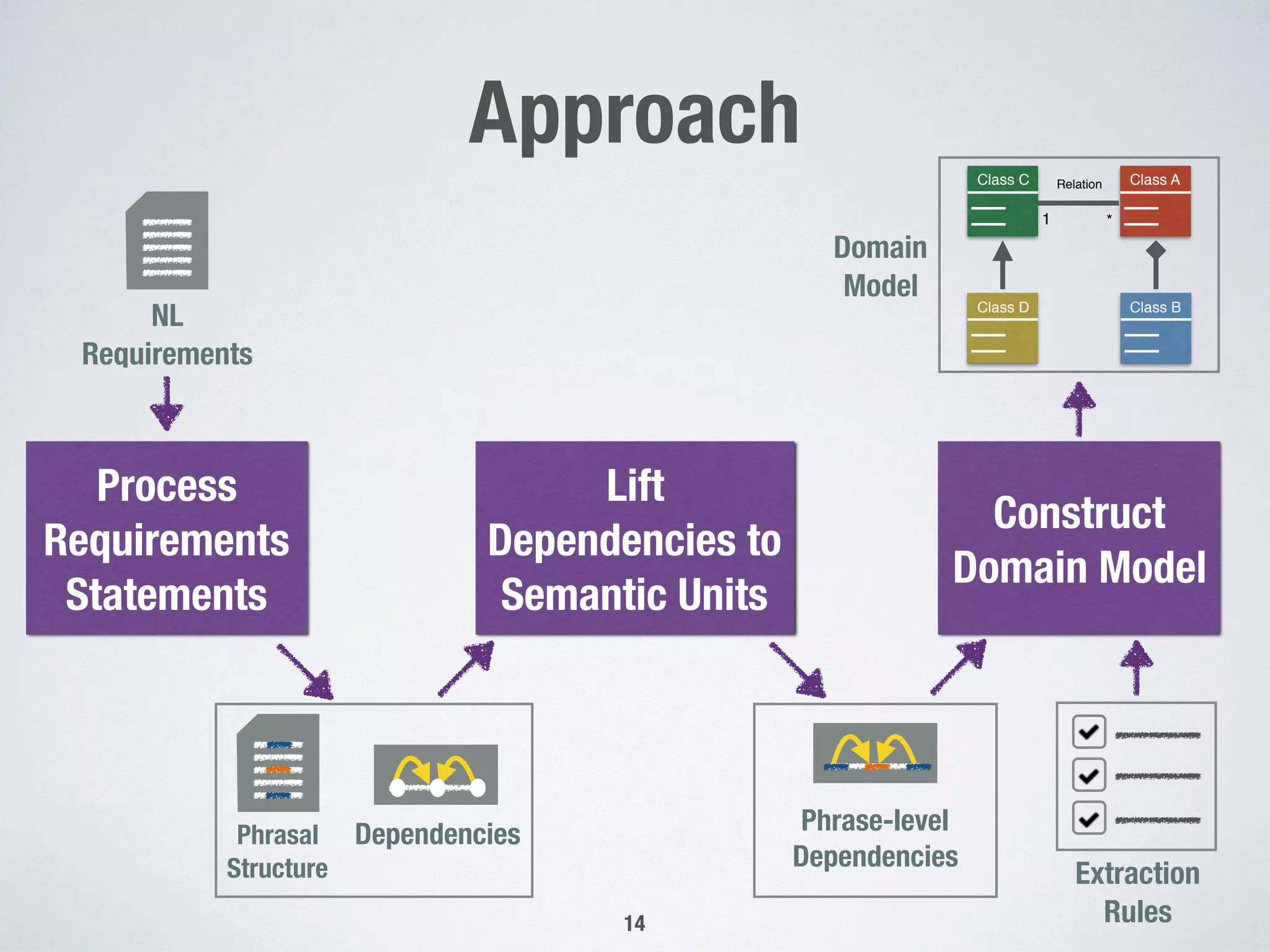

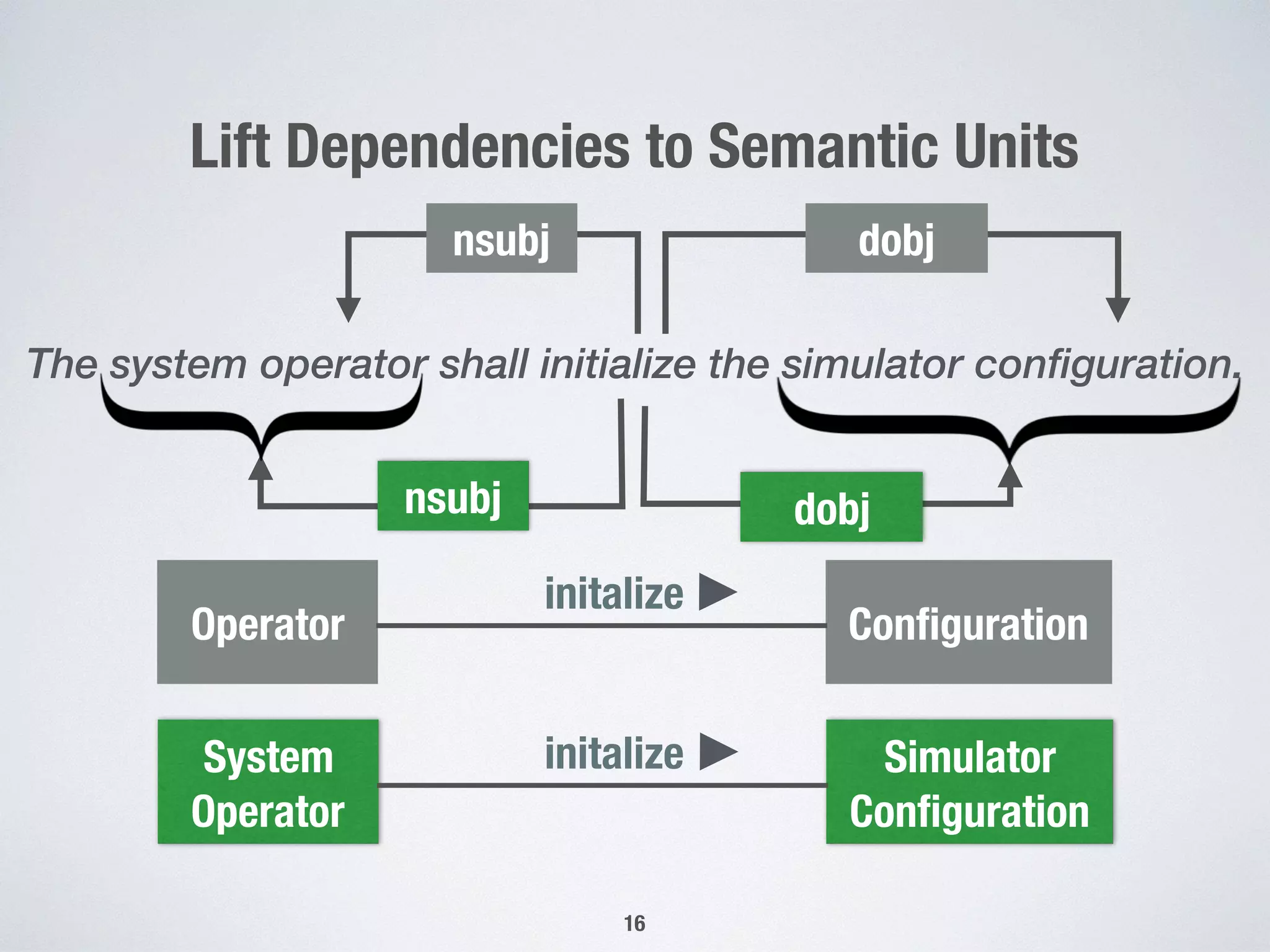
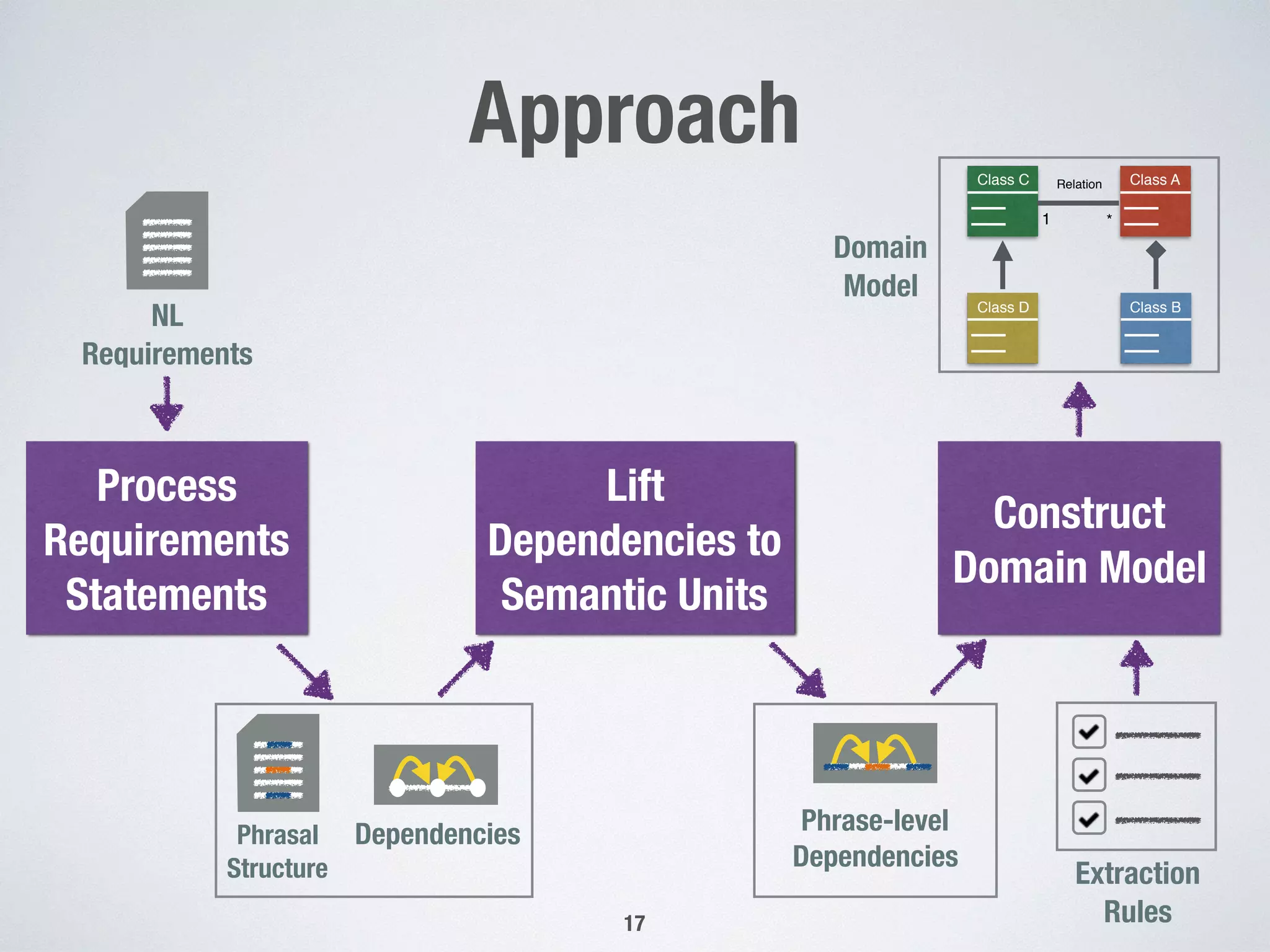

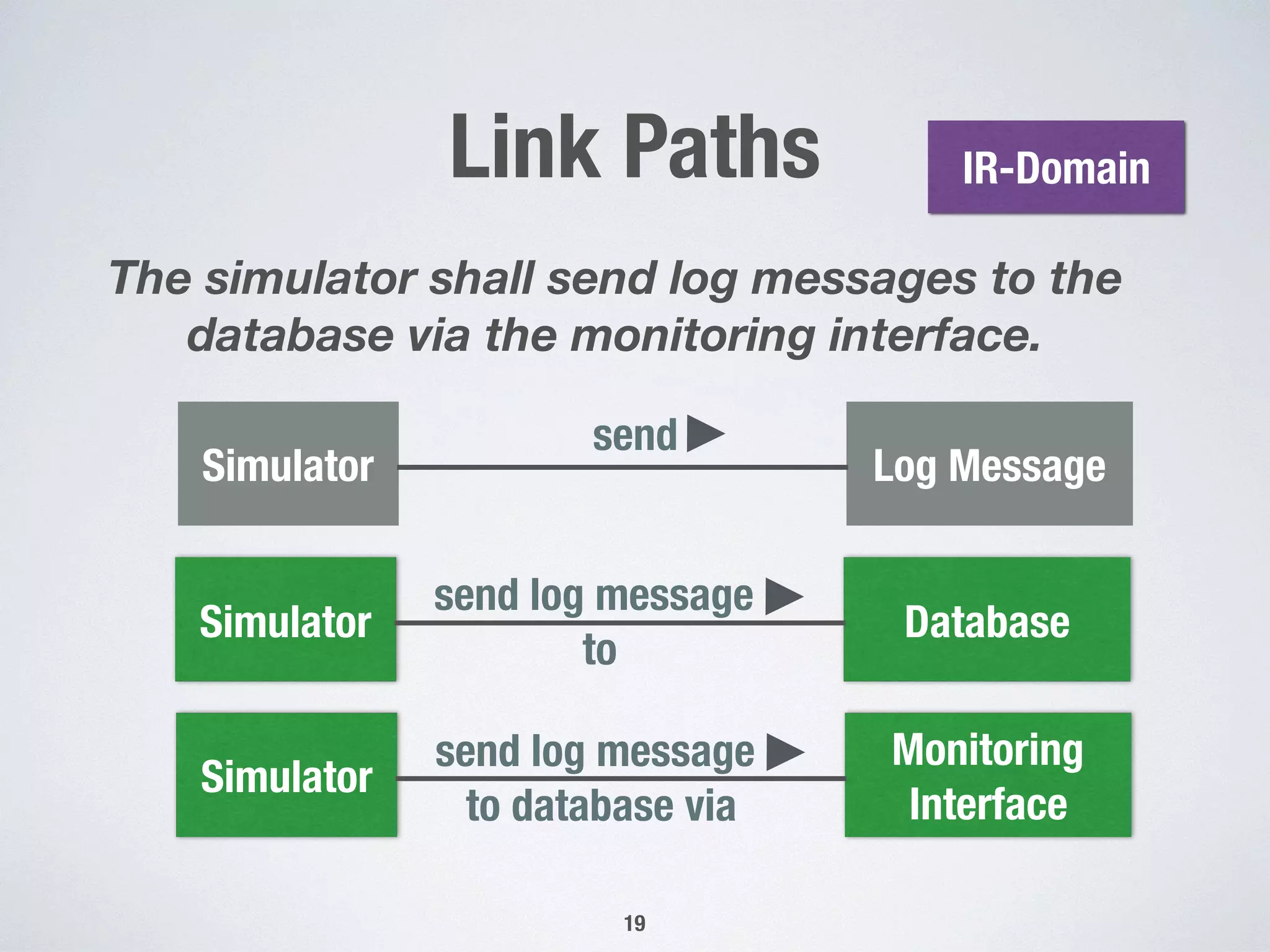






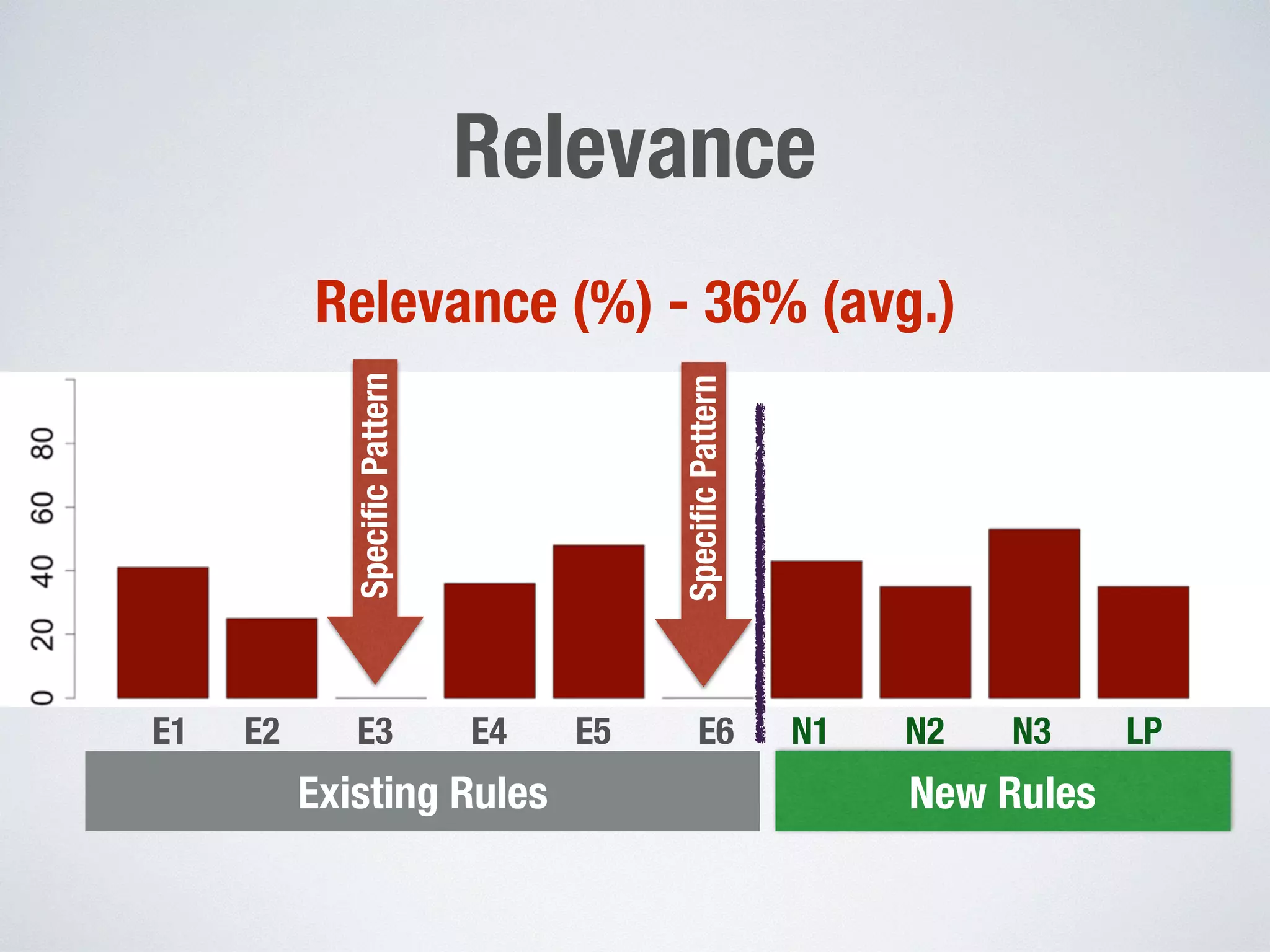




1) The document presents an approach for automatically extracting domain models from natural language requirements documents. It uses grammatical dependencies and novel extraction rules to construct domain models from requirement statements. 2) An empirical evaluation of the approach on three case studies found that generic extraction rules were triggered most frequently, while pattern-based rules were seldom triggered. Interviews on one case study found the extracted relations to be highly correct on average but only moderately relevant. 3) The conclusions indicate that the novel extraction rules hold practical significance but room remains to improve the relevance of automatically extracted domain models, such as by addressing common knowledge and natural language processing mistakes.