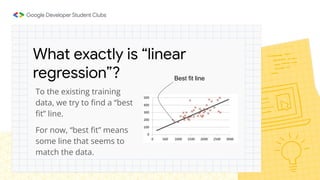
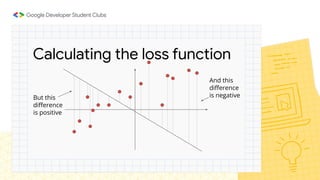
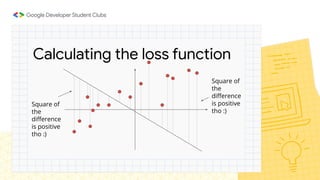
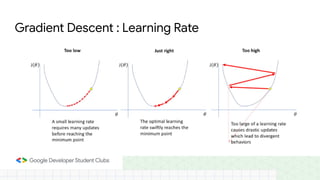
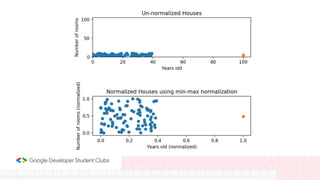
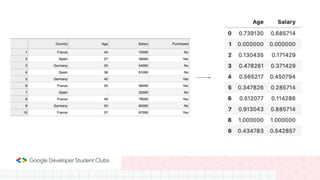
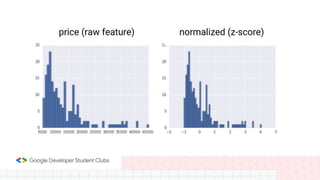
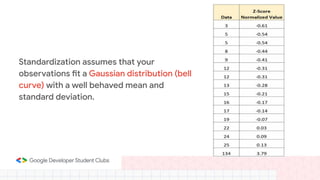
This document provides an overview of linear regression and logistic regression concepts. It begins with an introduction to linear regression, discussing finding the best fit line to training data. It then covers the loss function and gradient descent optimization algorithm used to minimize loss and fit the model parameters. Next, it discusses logistic regression for classification problems, covering the sigmoid function for hypothesis representation and interpreting probabilities. It concludes by discussing feature scaling techniques like normalization and standardization to prepare data for modeling.