Download to read offline


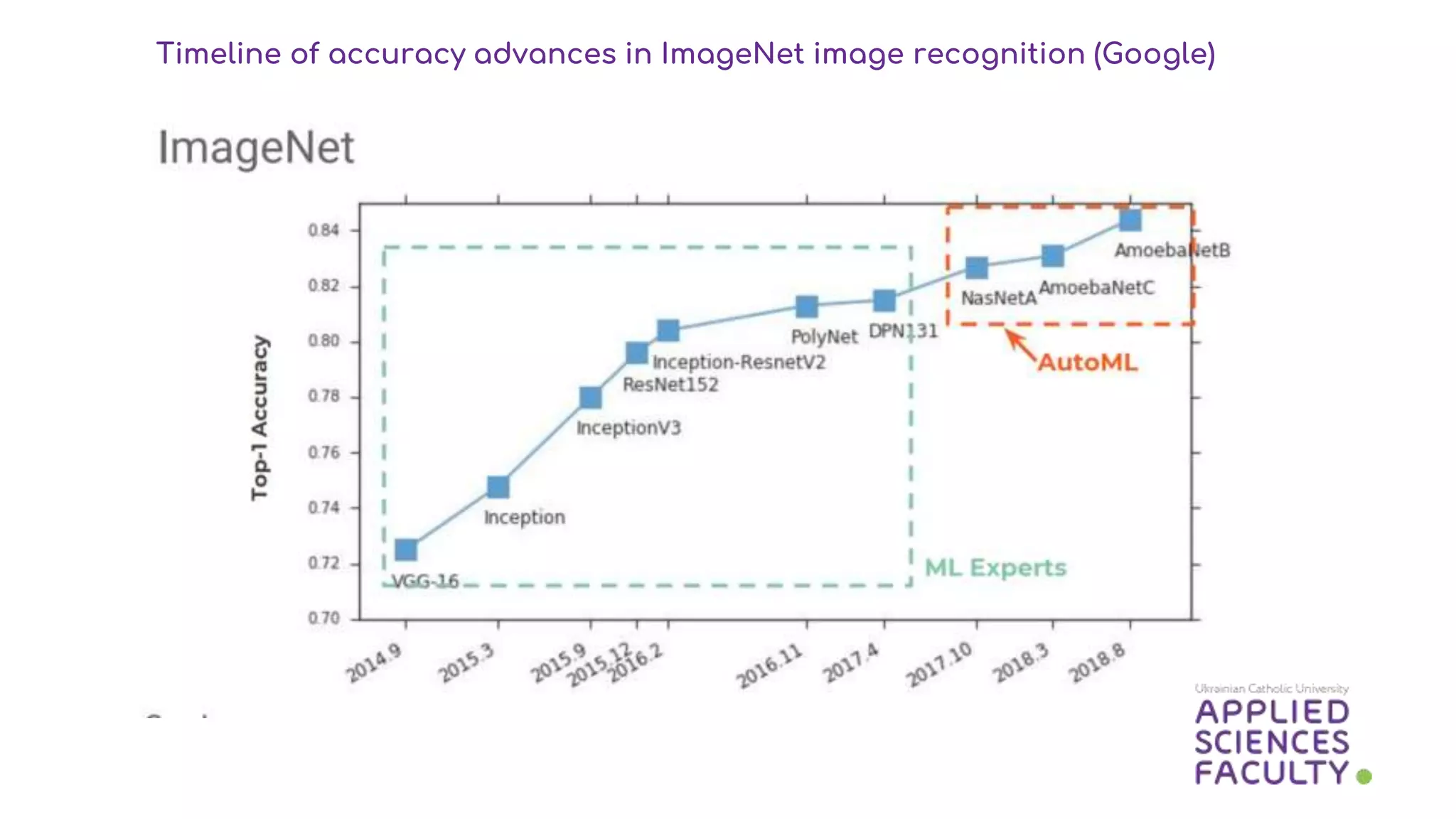



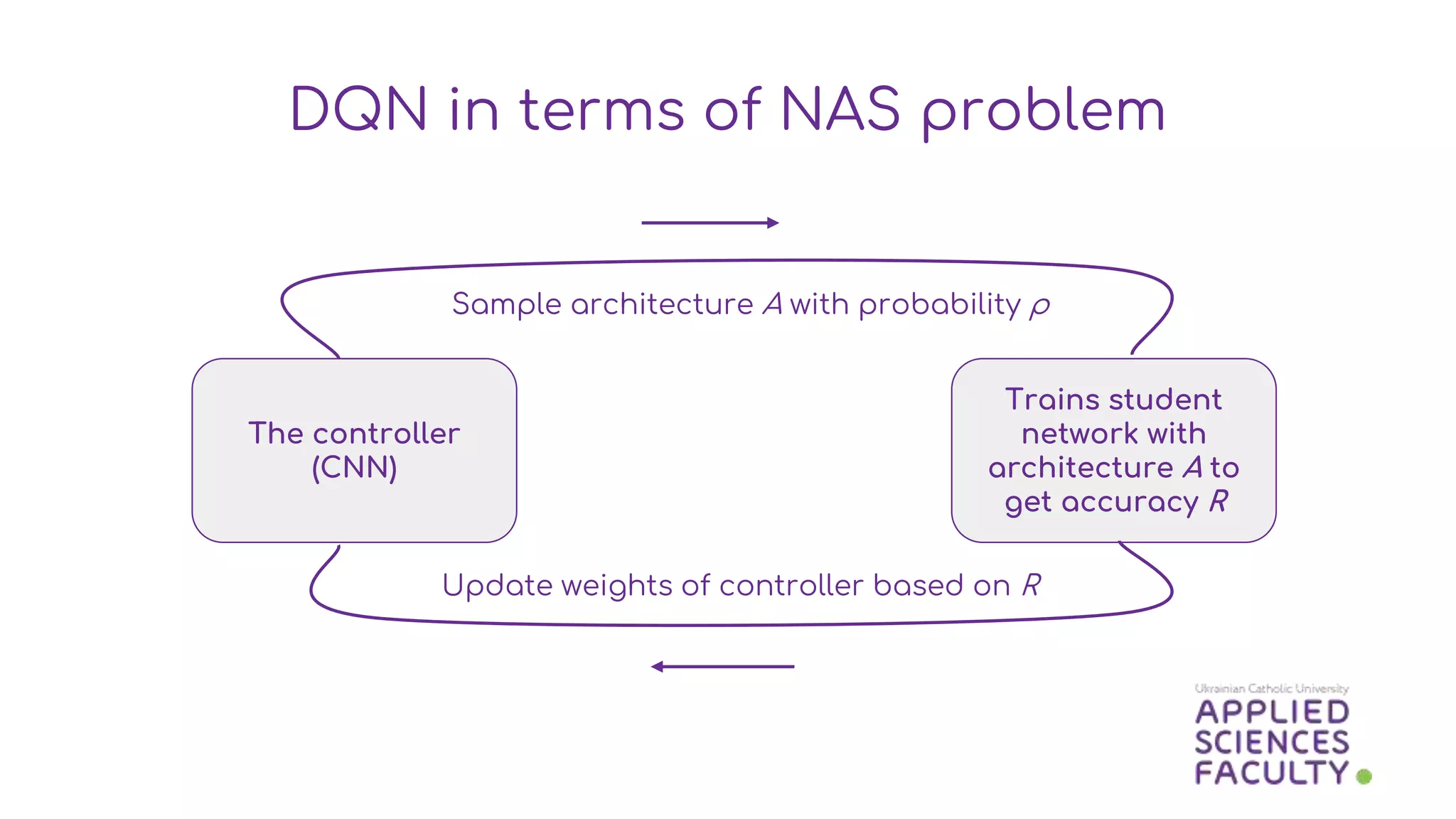



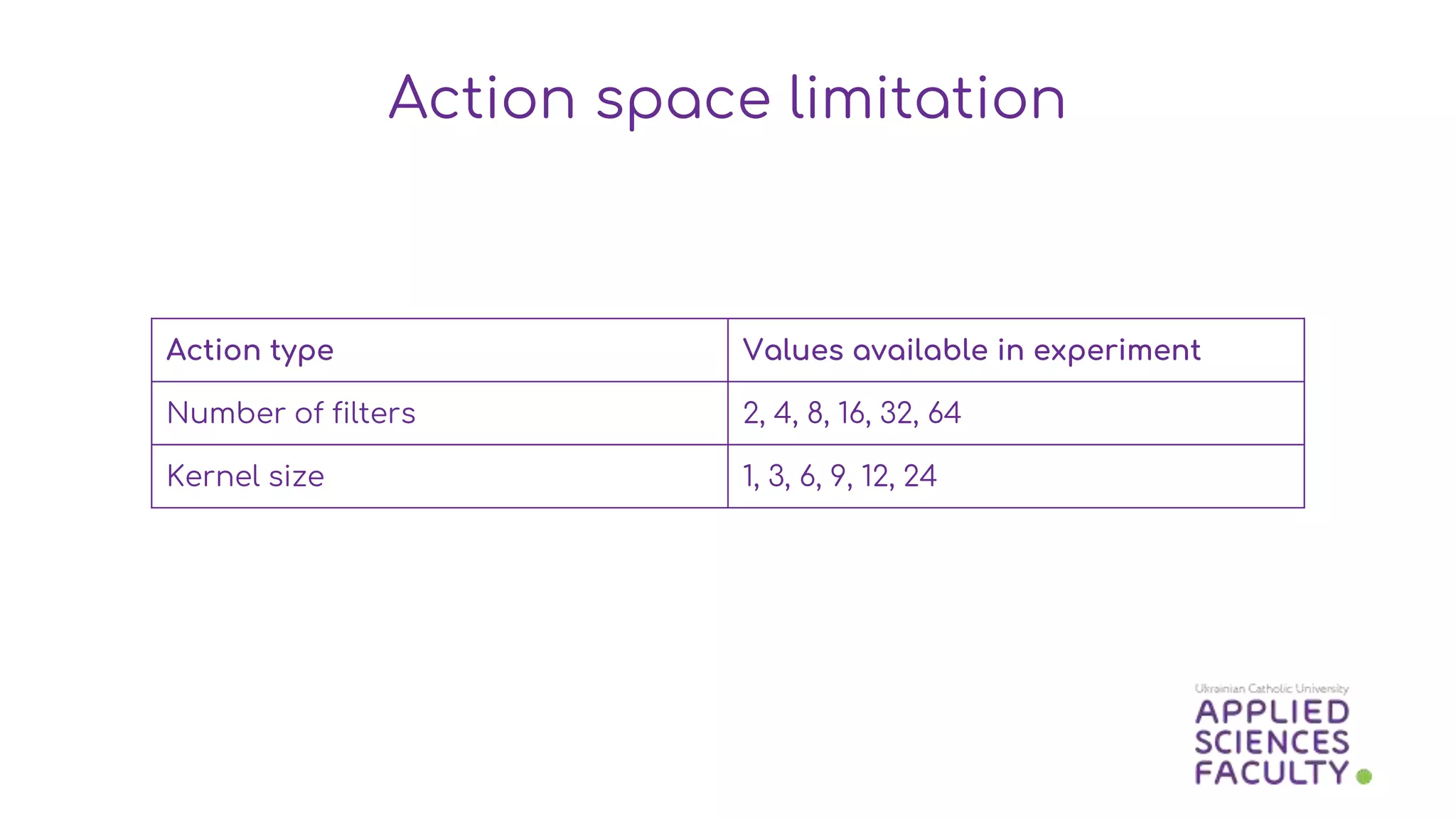
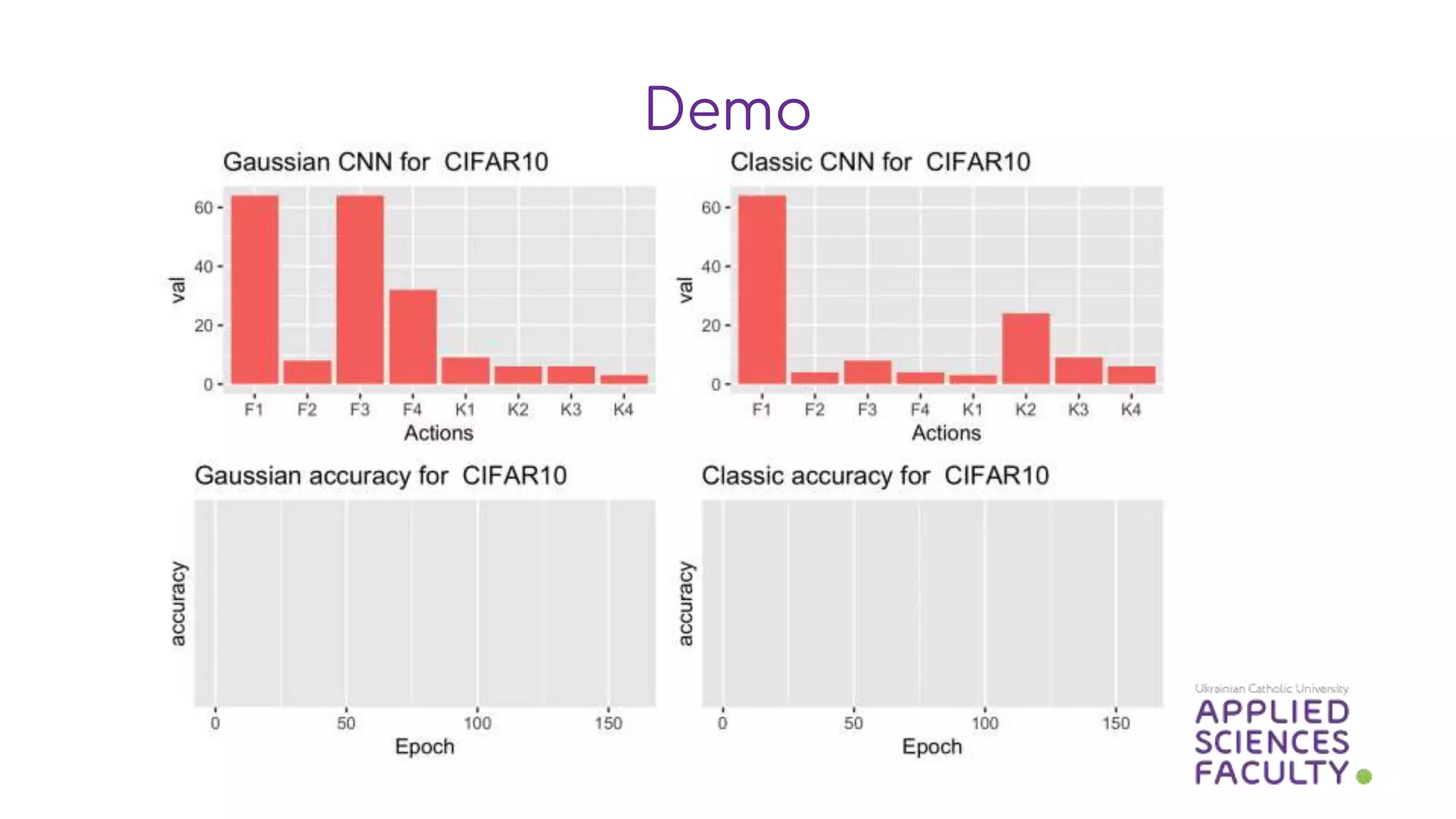
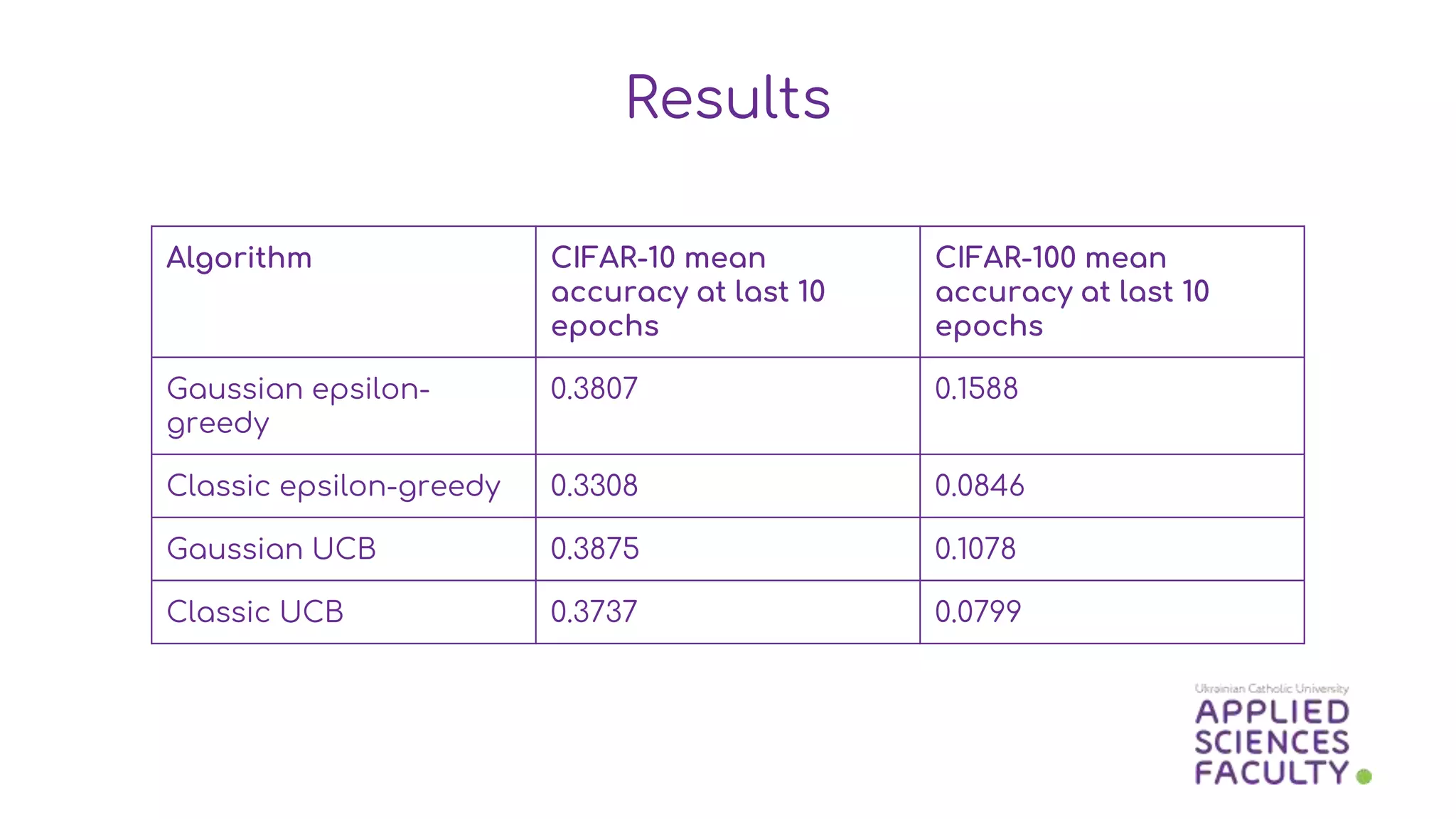


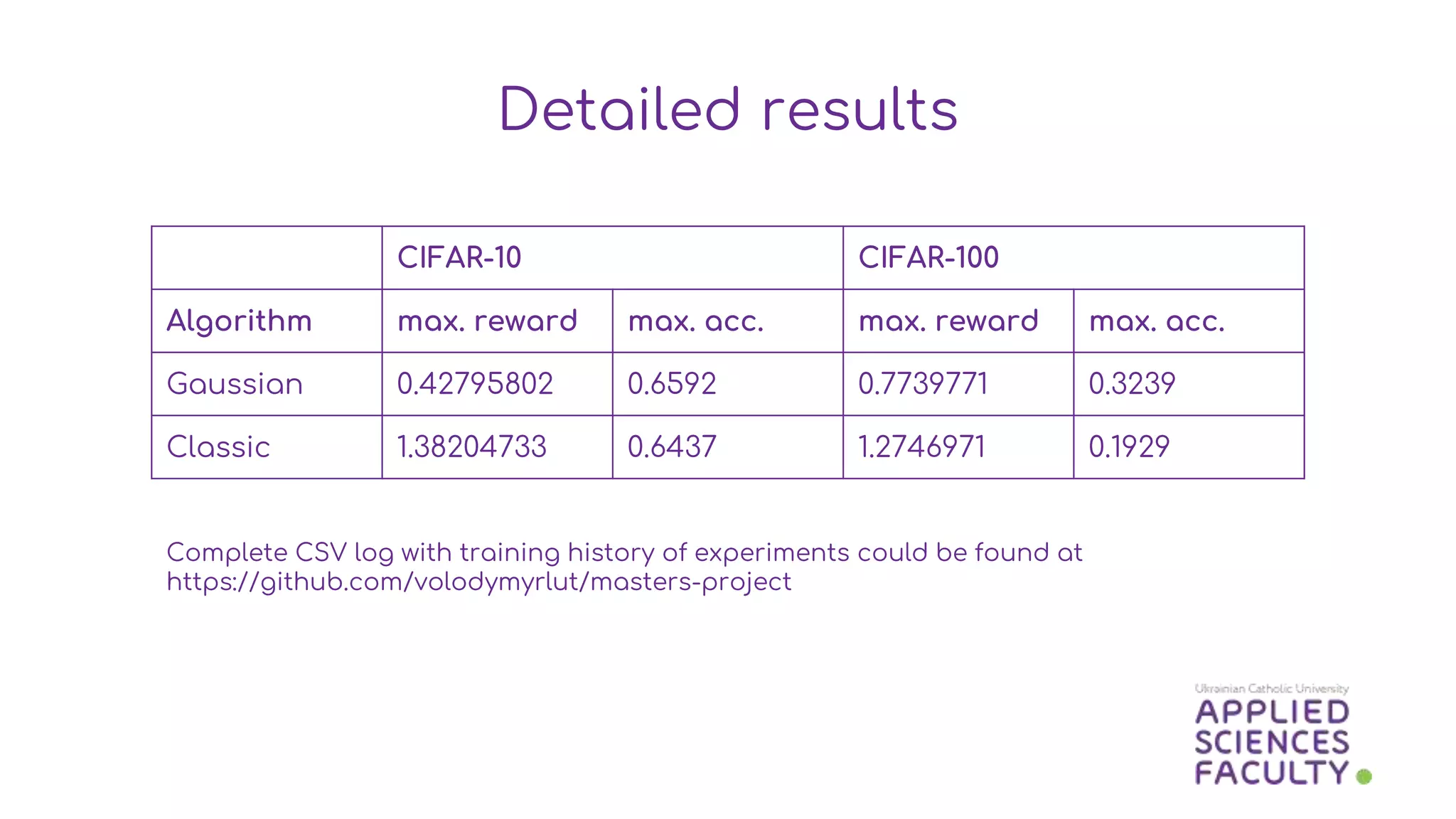

This document discusses a probabilistic approach to neural architecture search (NAS) using reinforcement learning methods to optimize model architectures. It details the methodology, including the use of Gaussian distributions for uncertainty measurement and the results of various algorithms on CIFAR datasets, highlighting the effectiveness of Gaussian modifications. The findings indicate that while the approach yields better architectures, it suffers from overfitting in small action spaces, necessitating consideration of additional methods.























































































