Downloaded 72 times


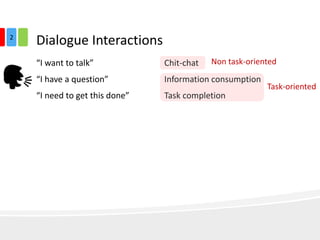


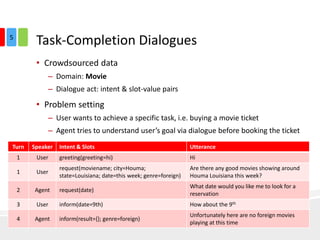



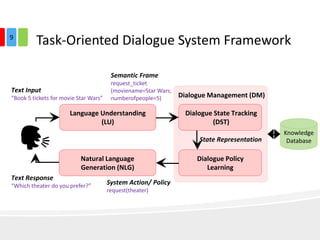
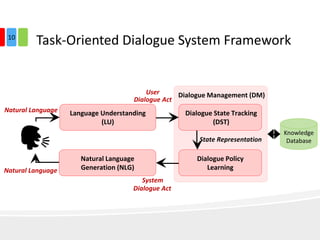
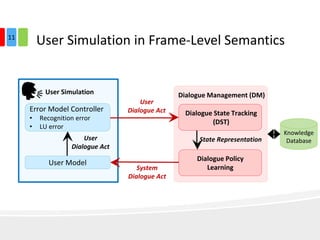
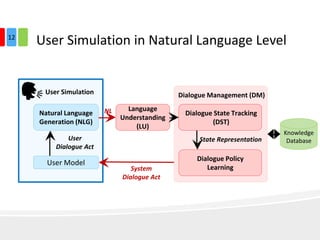

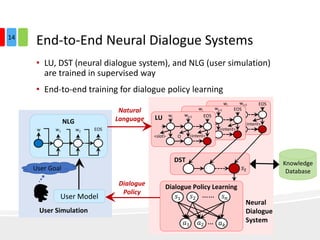


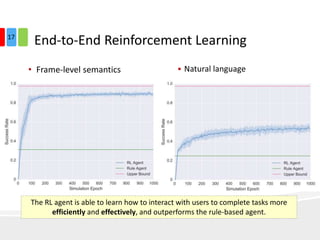

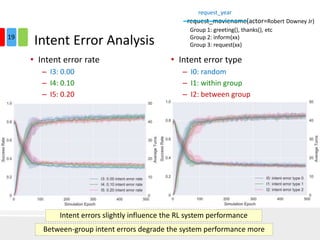
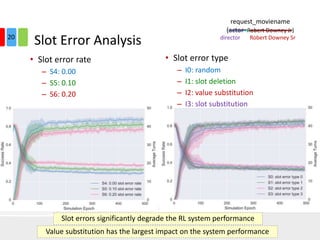
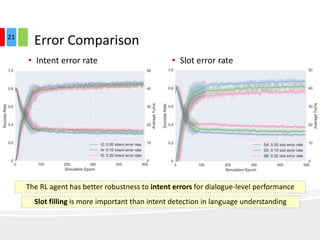
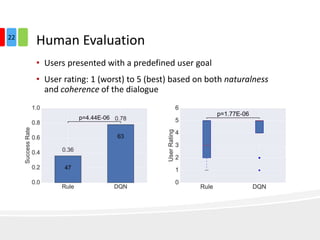





The document discusses end-to-end task-completion neural dialogue systems, highlighting their ability to manage dialogue interactions for various user intents, such as completing tasks or providing information. It compares rule-based agents with reinforcement learning agents, noting that the latter exhibits improved efficiency and robustness in handling user requests and errors. The authors emphasize the importance of addressing slot-level errors over intent errors and propose a systematic approach to evaluate dialogue agents using crowdsourced data.







































![The future of_conver_ai[6933]](https://cdn.slidesharecdn.com/ss_thumbnails/thefutureofconverai6933-220122073748-thumbnail.jpg?width=640&height=640&fit=bounds)





































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)




