Download as PDF, PPTX


![Introduction
Contributions of Eyeriss
A novel energy-efficient CNN dataflow that has been verified in
a fabricated chip
A taxonomy of CNN dataflows that classifies previous work into
three categories (WS, OS, NLR)
Figure: Eyeriss Die Photo (35 fps @ 278 mW running AlexNet[10])
4000µm
4000µm
168 PE
GlobalBuffer
Michael Lee (NTU) Introduction to Eyeriss October 24, 2017 3 / 37](https://image.slidesharecdn.com/eyeriss-200609234334/75/Eyeriss-Introduction-3-2048.jpg)


![Introduction
Recap on CNN
Forward computation in CONV layers
Given ofmap O, ifmap I, bias B, weight W, stride size U
O[z][u][x][y] =ReLU B[u] +
C−1
k=0
R−1
i=0
S−1
j=0
I[z][k][Ux + i][Uy + j] × W[u][k][i][j]
partial sum
(1)
where 0 ≤ z < N, 0 ≤ u < M, 0 ≤ y < E, 0 ≤ x < F
E = (H − R + U)/U (2)
F = (W − S + U)/U (3)
Michael Lee (NTU) Introduction to Eyeriss October 24, 2017 6 / 37](https://image.slidesharecdn.com/eyeriss-200609234334/75/Eyeriss-Introduction-6-2048.jpg)




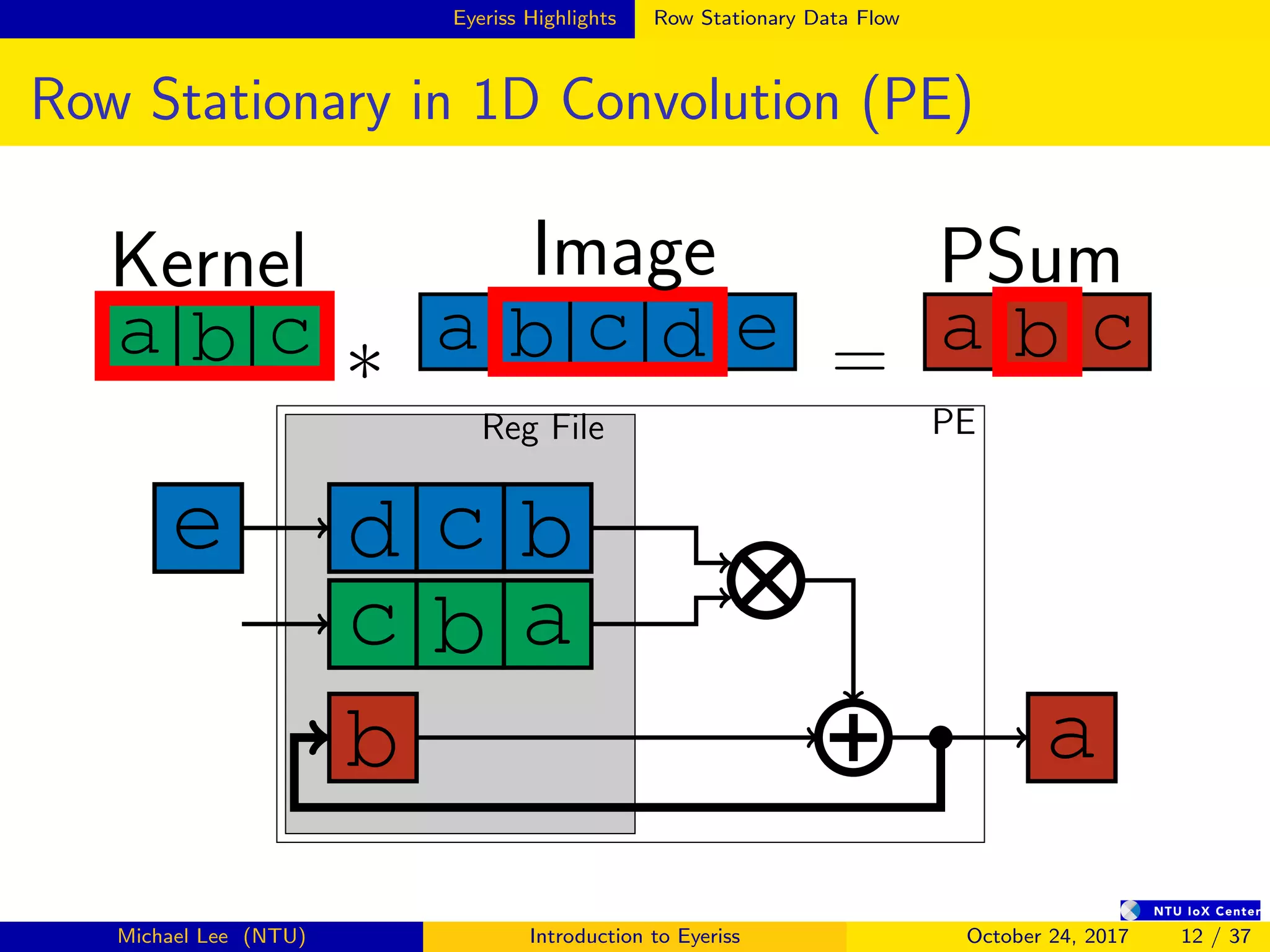
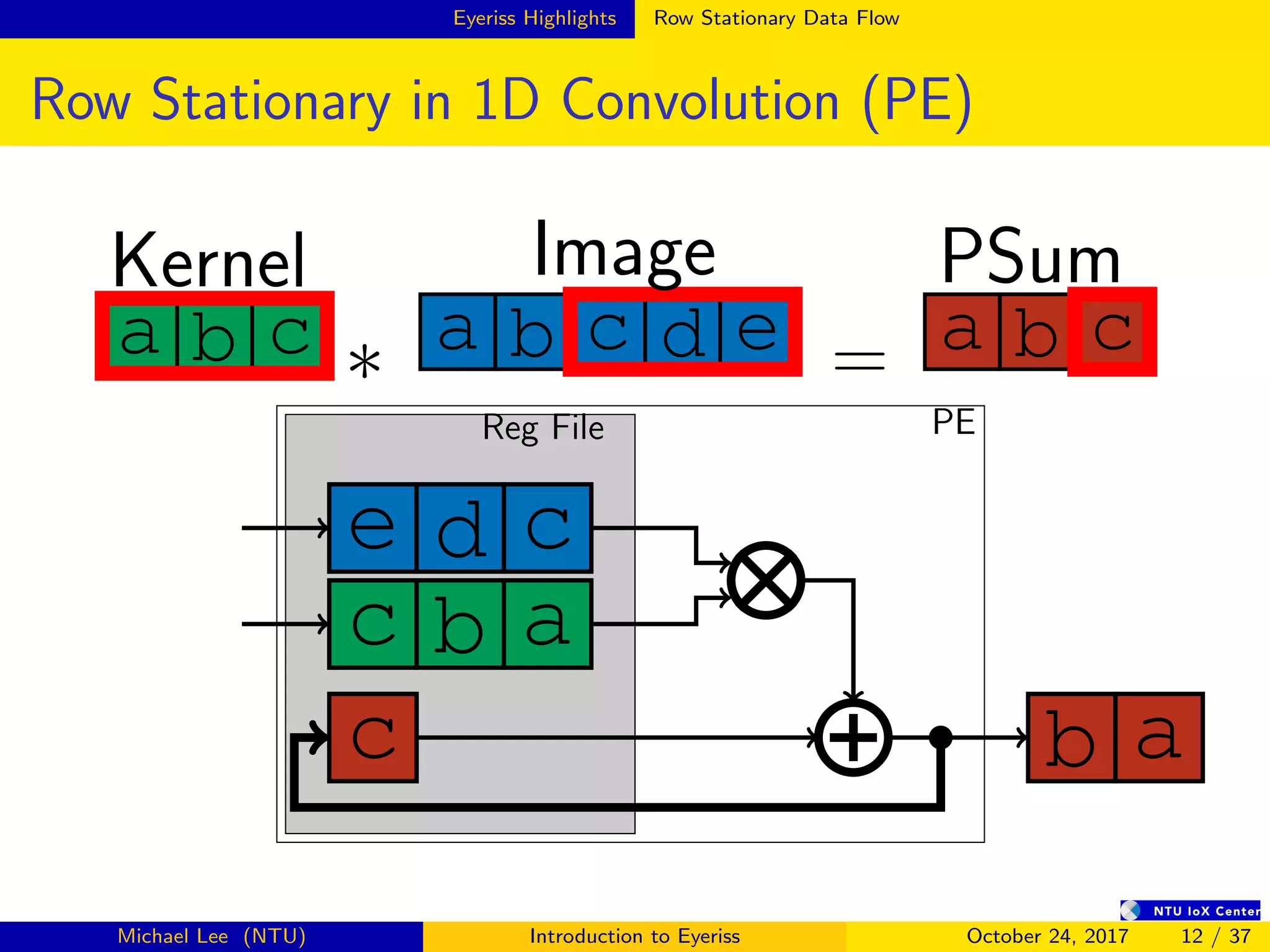



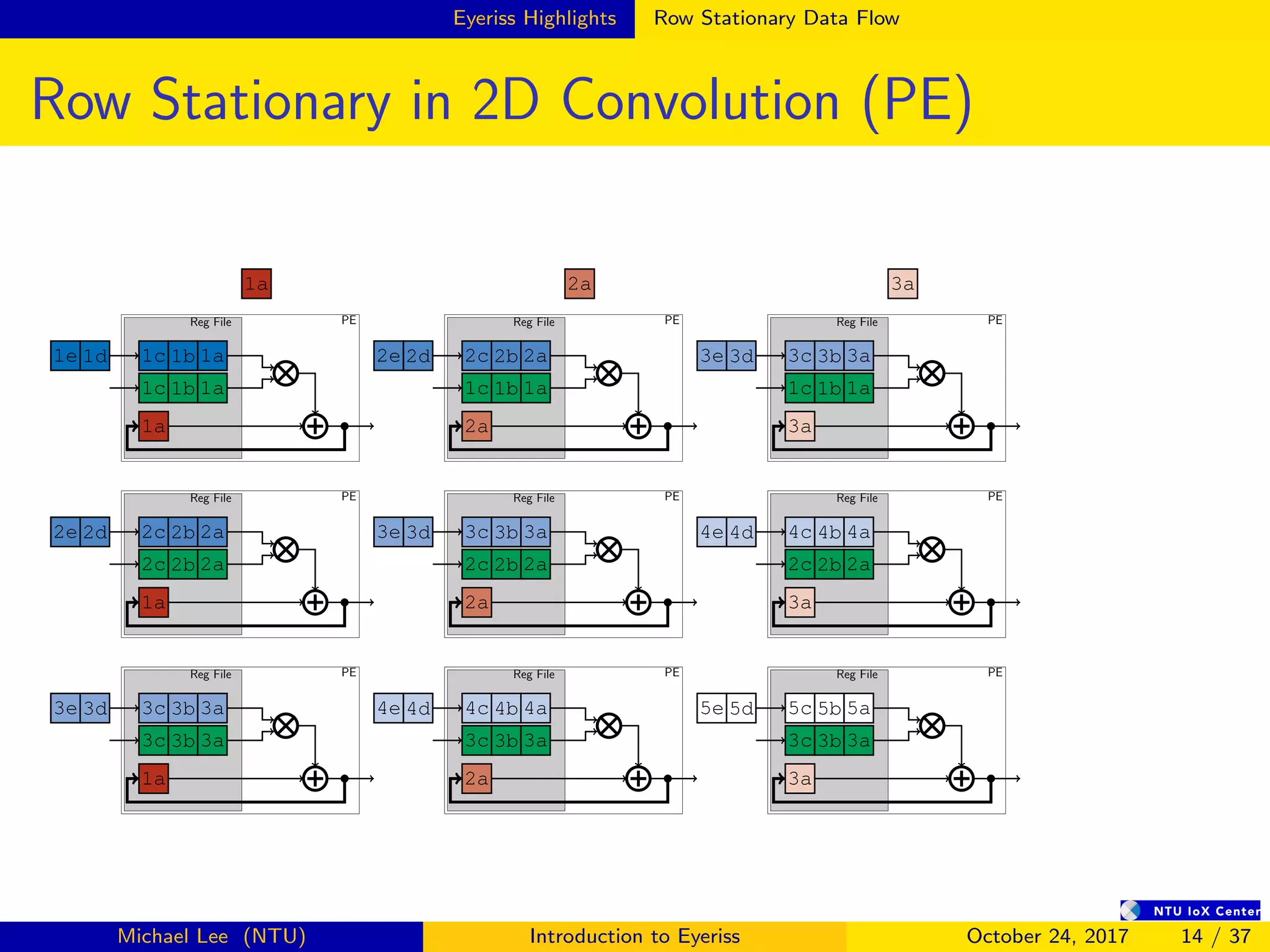






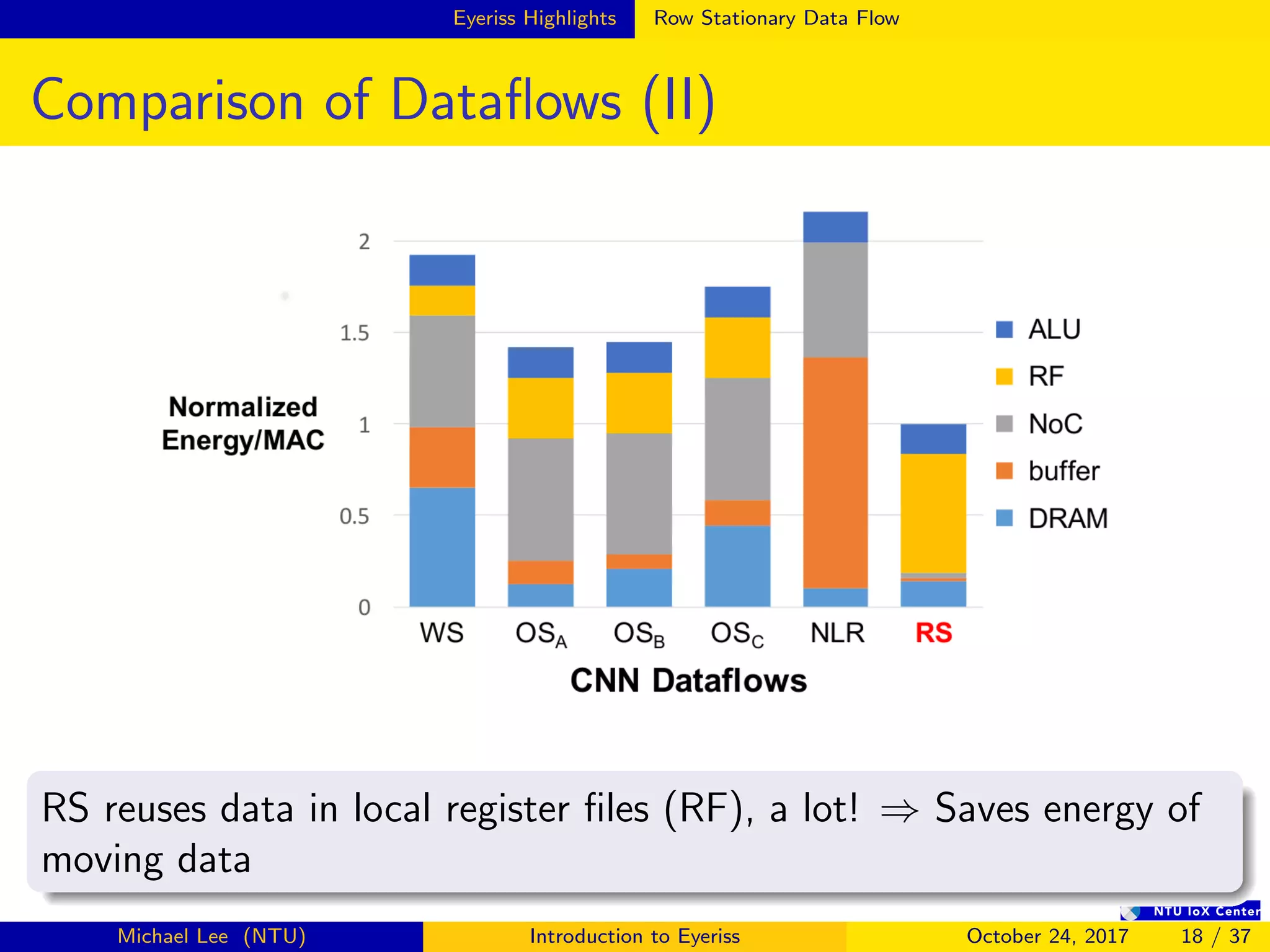







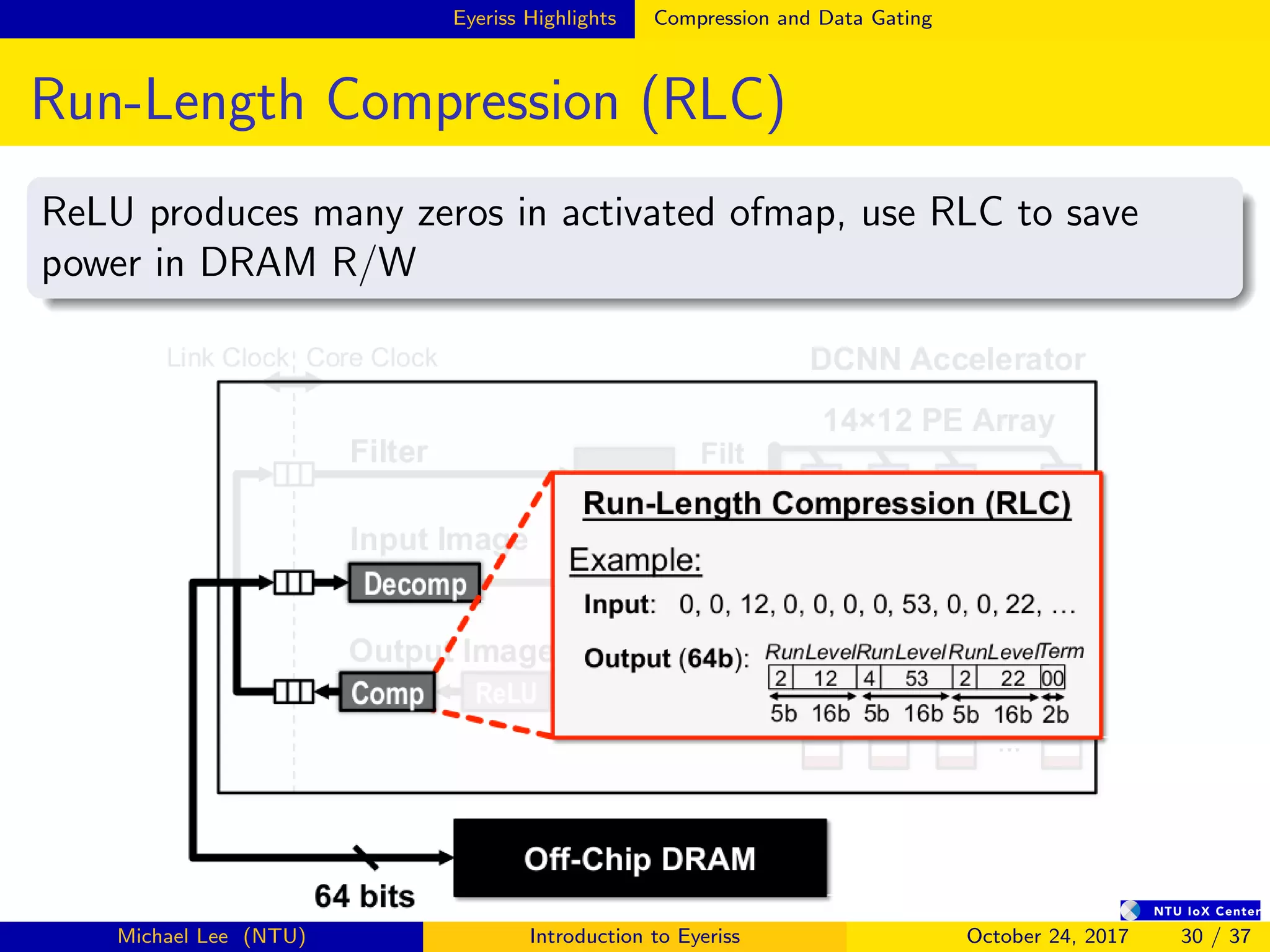
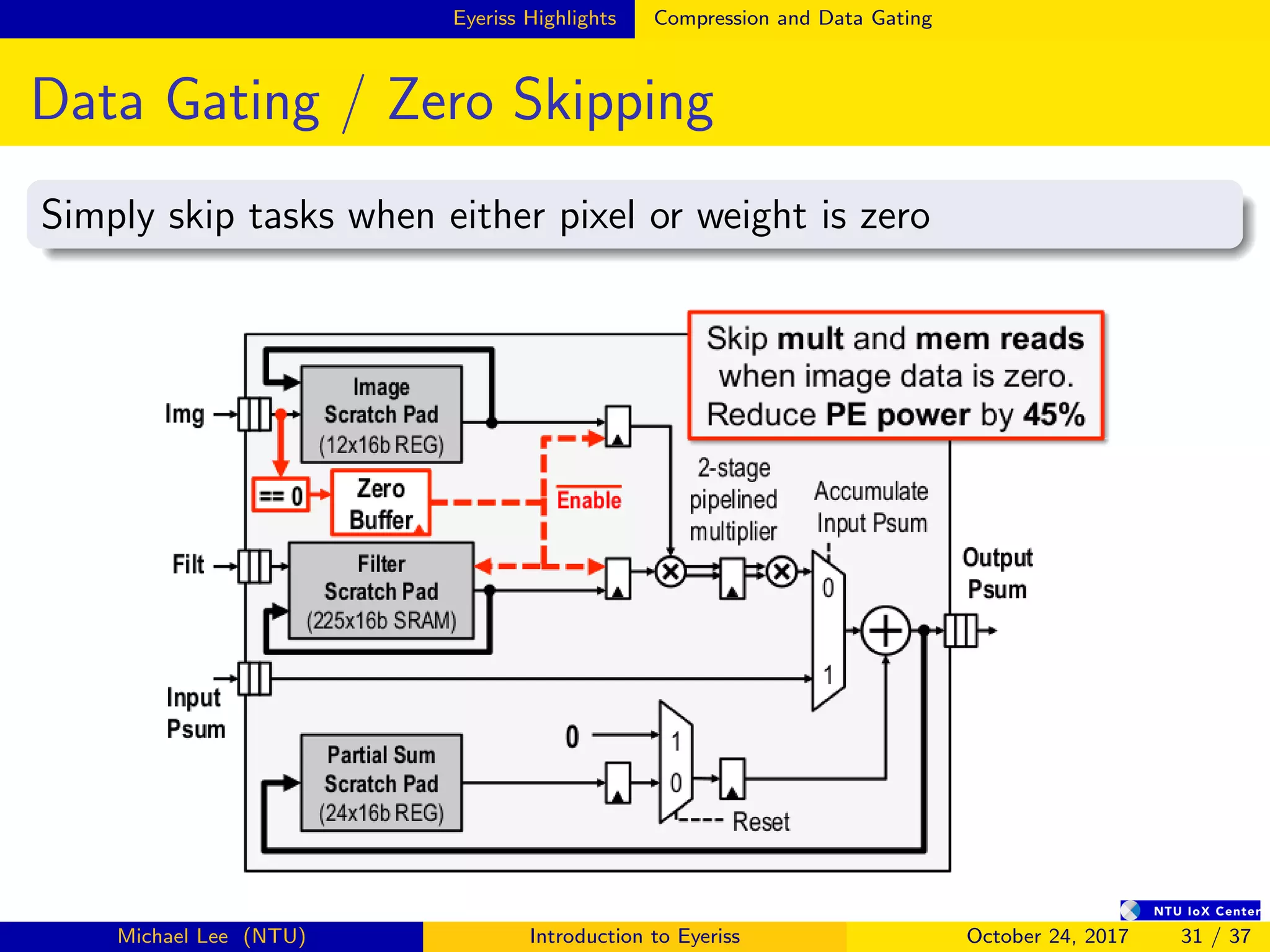

![Summary
Performance Summary and Comparison
Eyeriss[5] NVIDIA TK1
Technology 65nm 1P9M 28nm
Chip Size 4.0×4.0 N/A
Core Area 3.5×3.5 N/A
Gate Count 1176k N/A
Word Bit-Width 16b Fixed 32b Float
Core Clock(MHz) 200 852
On-Chip Buffer Size (kB) 108 64
Total Register Size (kB) 75.3 256
#MAC 168 192
Throughput(fps) 34.7 68
Measured Power Idle (mW) 3700
Measured Power Active (mW) 278 10002
Michael Lee (NTU) Introduction to Eyeriss October 24, 2017 33 / 37](https://image.slidesharecdn.com/eyeriss-200609234334/75/Eyeriss-Introduction-42-2048.jpg)





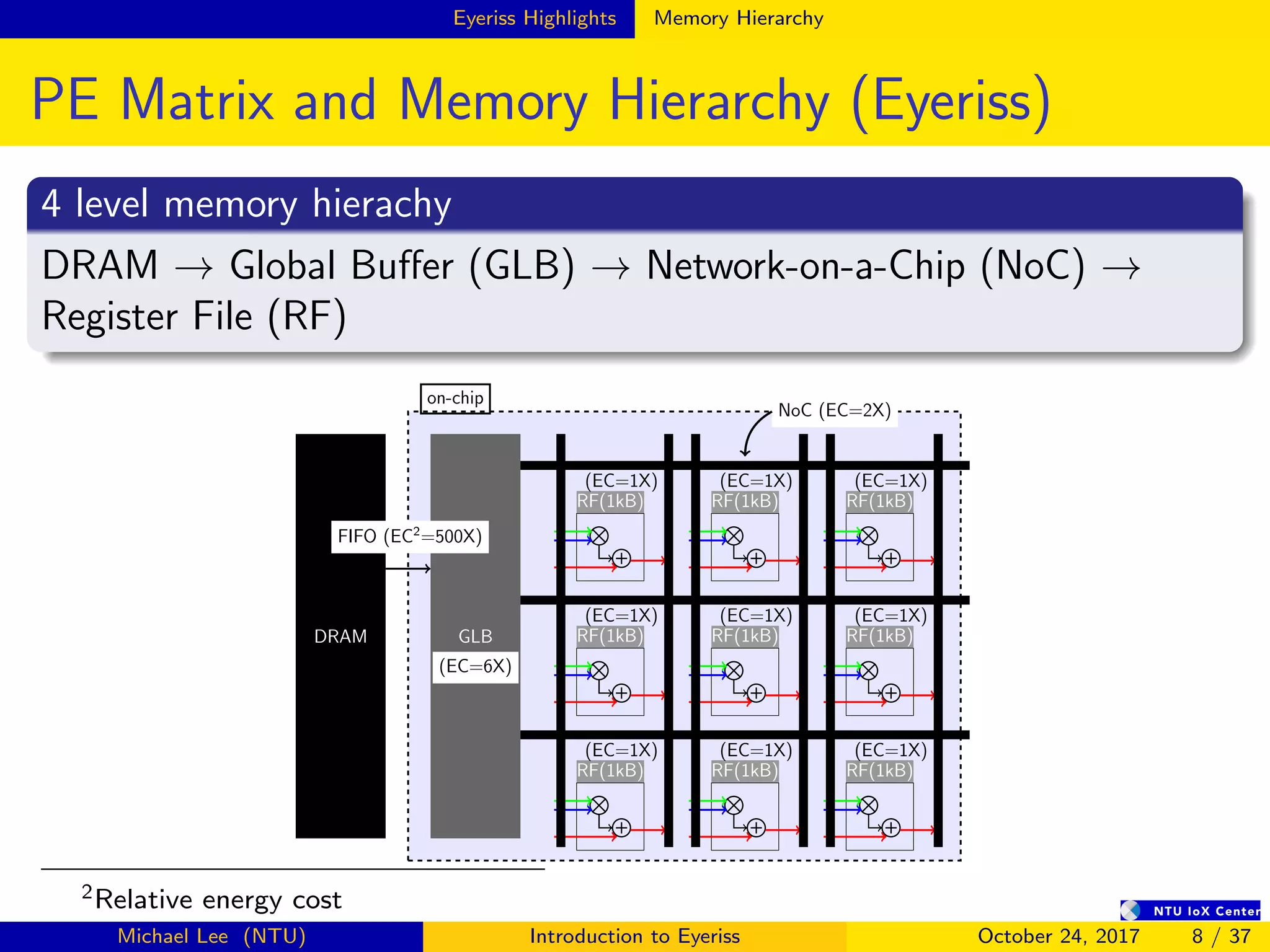
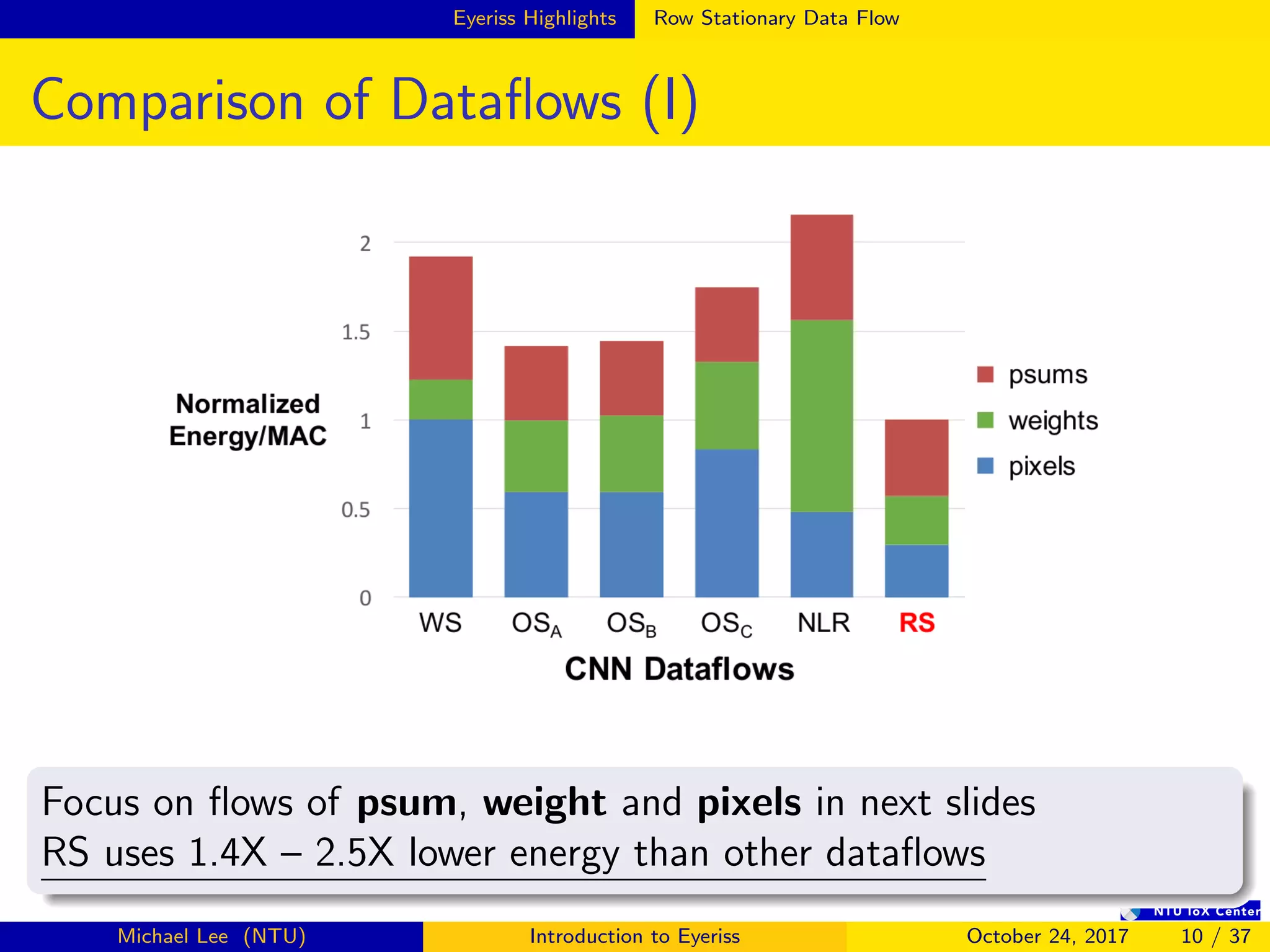
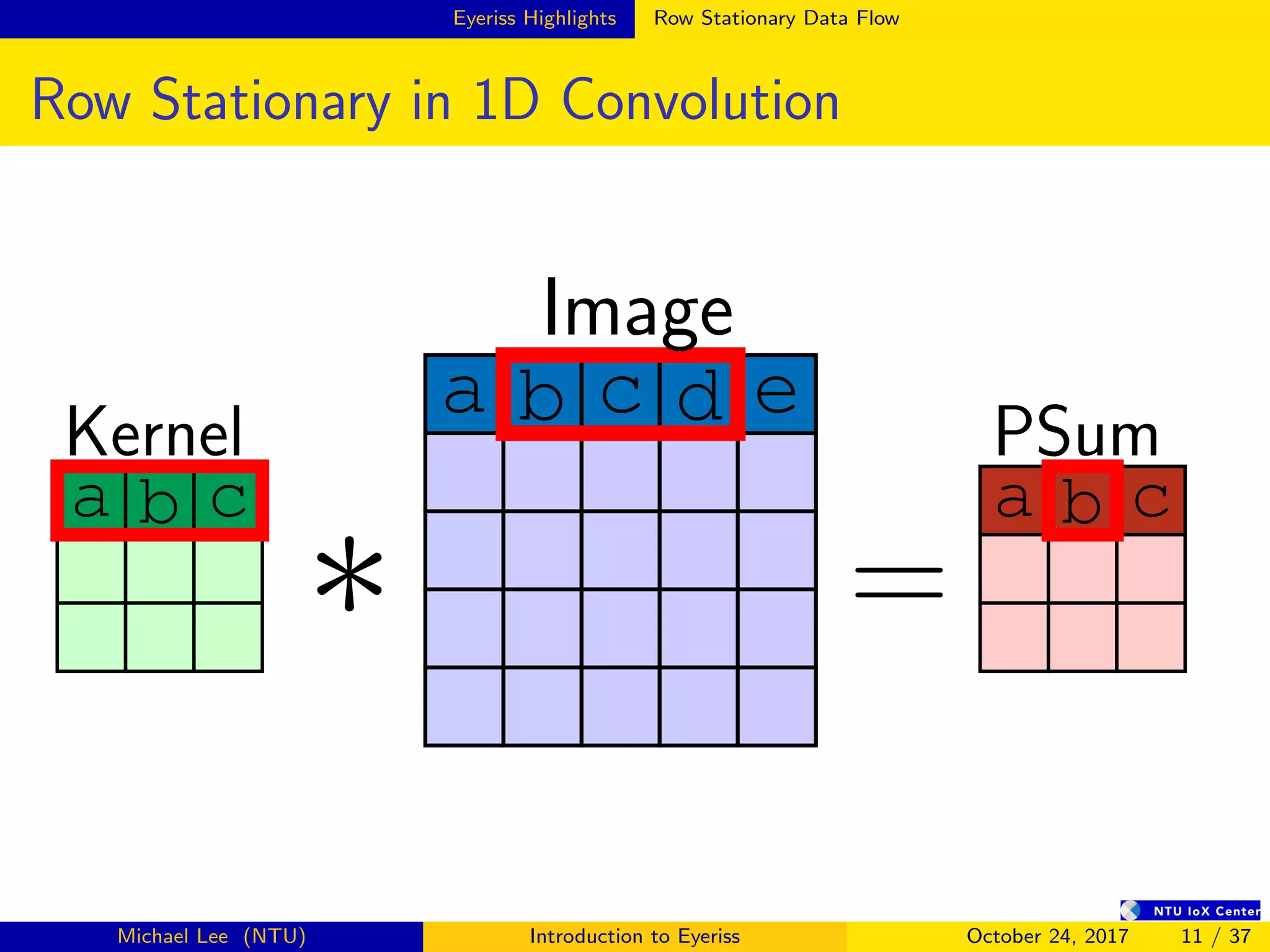
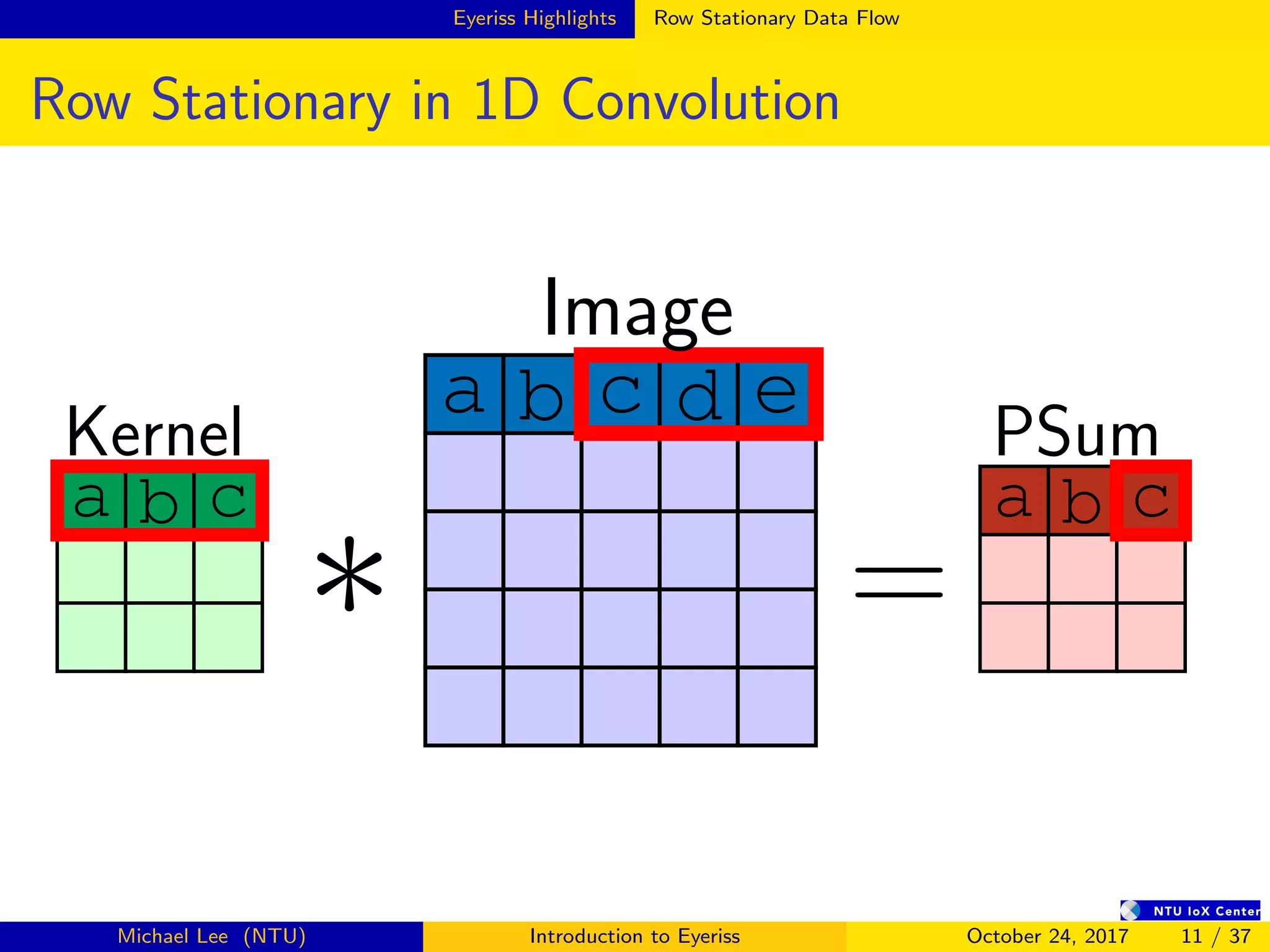
The document provides an introduction to Eyeriss, an energy-efficient reconfigurable accelerator for deep convolutional neural networks (CNNs). Some key points: - Eyeriss uses a row stationary dataflow that reduces energy costs compared to other dataflows like weight stationary and output stationary. - It has a 4-level memory hierarchy from DRAM to register files to minimize data movement costs. - A network-on-chip and multicast/point-to-point delivery allows single-cycle data delivery between components. - Compression techniques like run-length compression are used to further reduce data movement costs.

![[DL輪読会]Learning to Simulate Complex Physics with Graph Networks](https://cdn.slidesharecdn.com/ss_thumbnails/learningtosimulatecomplexphysicswithgraphnetworks-200508054213-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]SlowFast Networks for Video Recognition](https://cdn.slidesharecdn.com/ss_thumbnails/20191206slowfastnetworkkuboshizuma-191206010601-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]ICLR2020の分布外検知速報](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2020ood-190927011524-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Reward Augmented Maximum Likelihood for Neural Structured Prediction](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks0804-170803075139-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Neural Ordinary Differential Equations](https://cdn.slidesharecdn.com/ss_thumbnails/nnasode1-190111001755-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]When Does Label Smoothing Help?](https://cdn.slidesharecdn.com/ss_thumbnails/yokota20191227dl-191227001522-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]DropBlock: A regularization method for convolutional networks](https://cdn.slidesharecdn.com/ss_thumbnails/dlyokota20190222-190222002832-thumbnail.jpg?width=640&height=640&fit=bounds)





















































