Downloaded 50 times




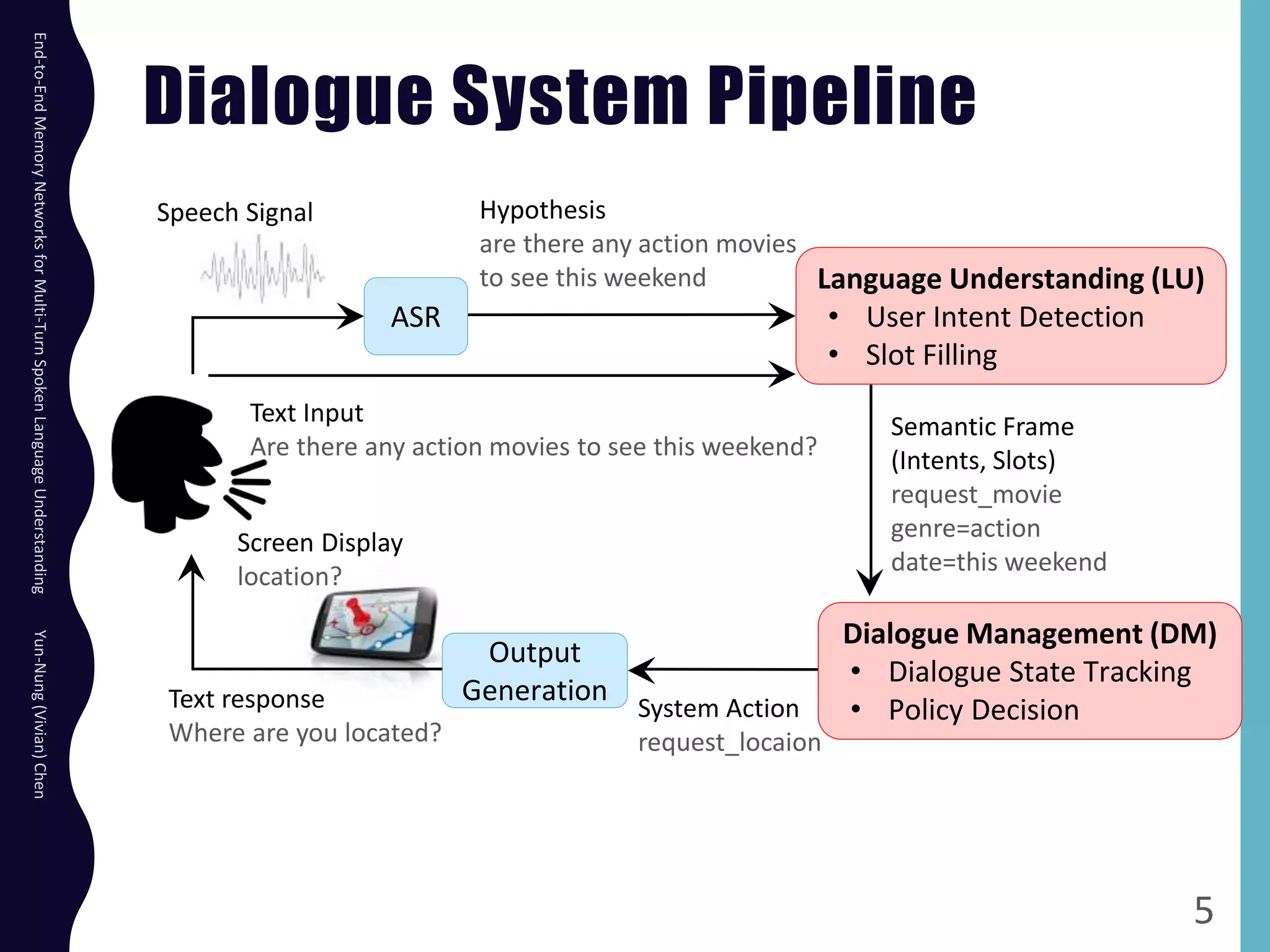
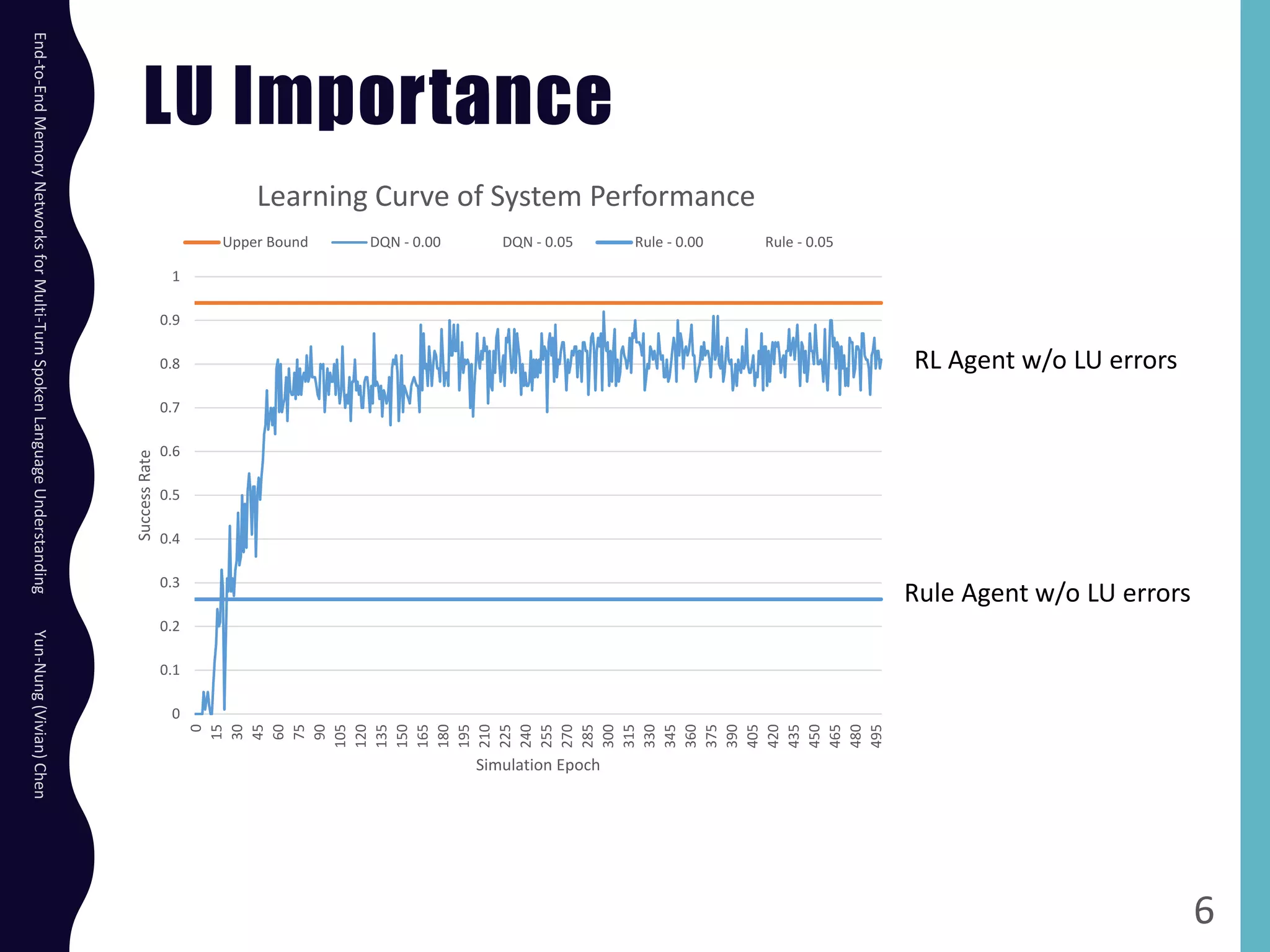
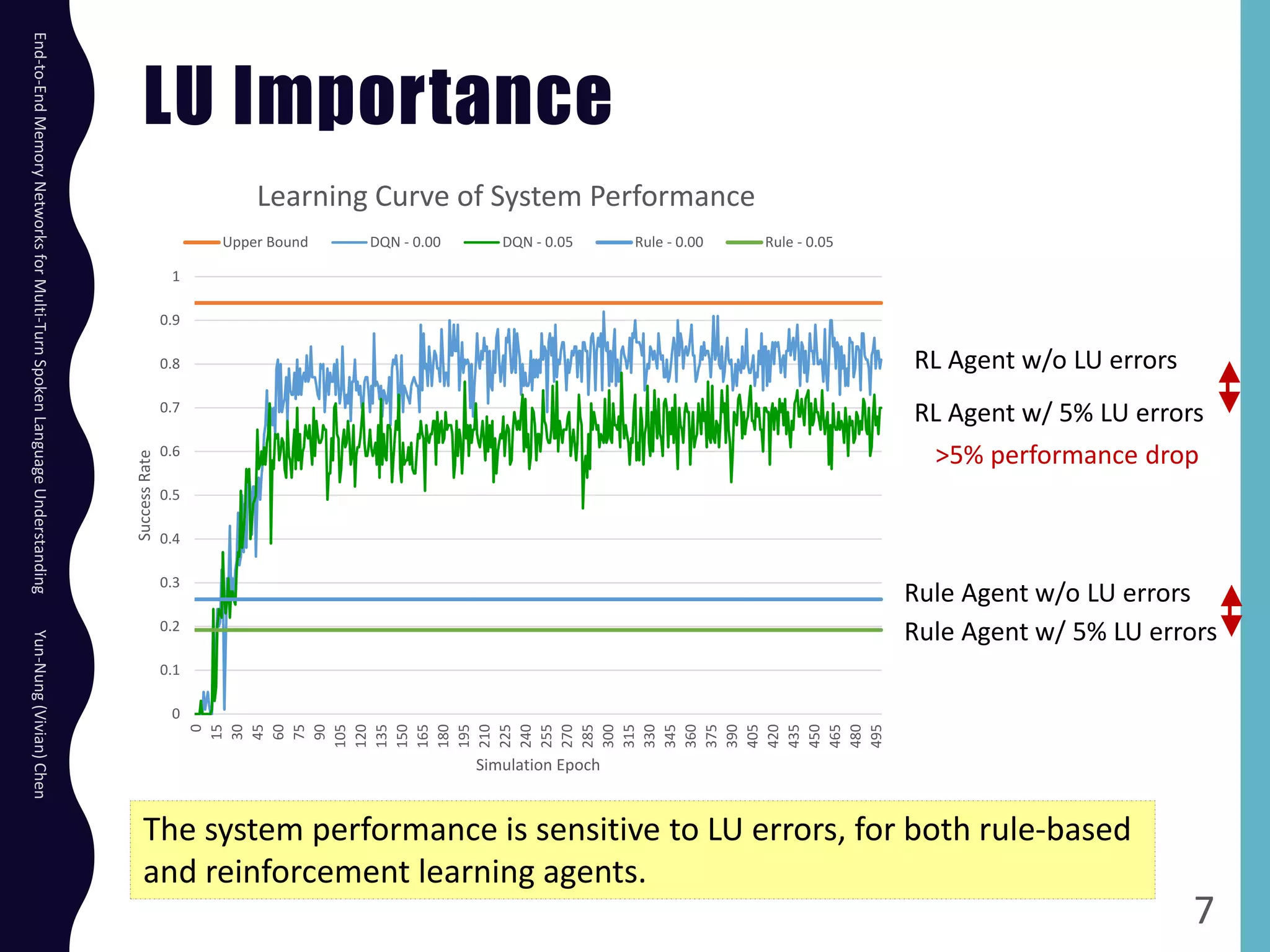
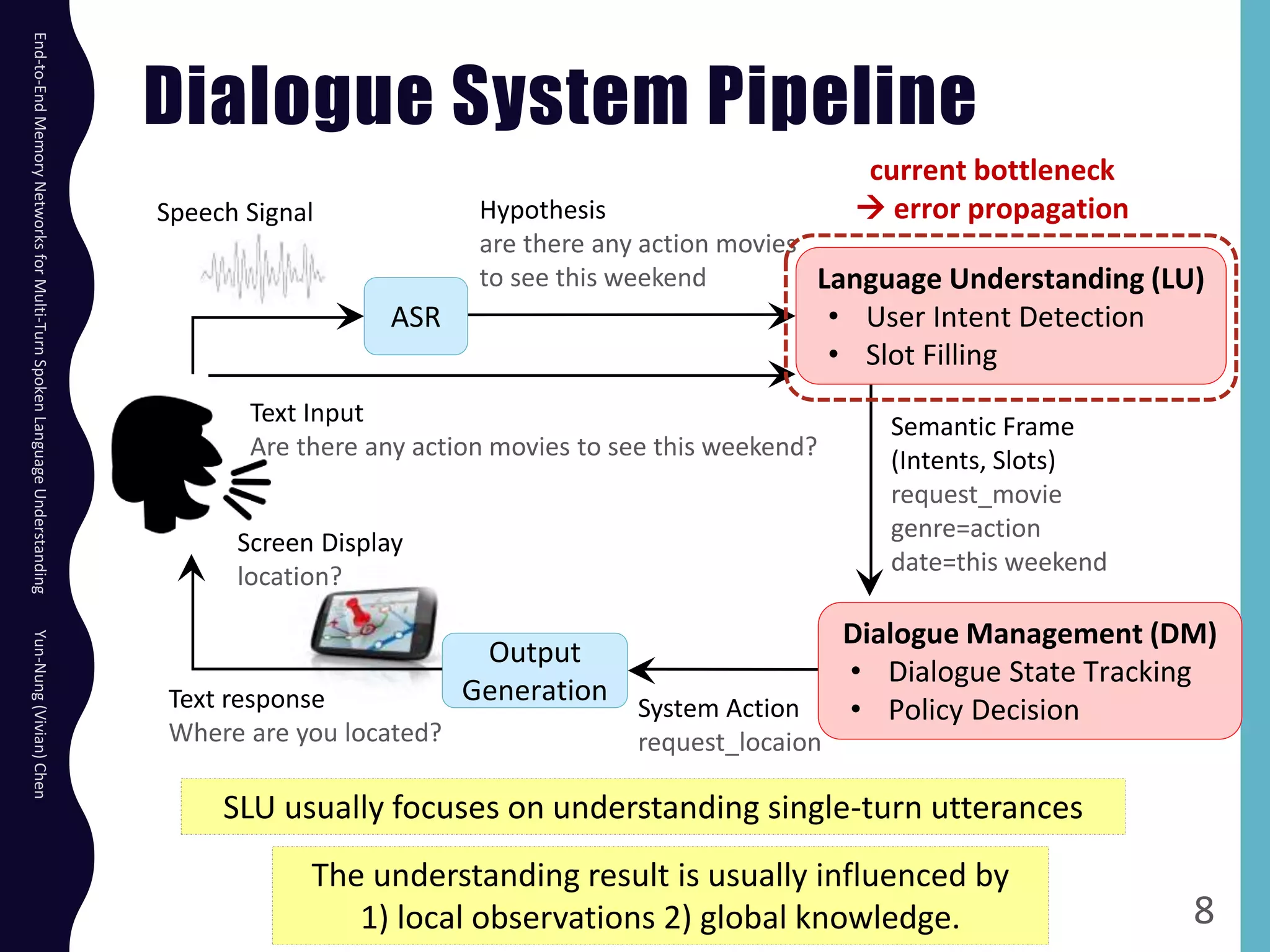
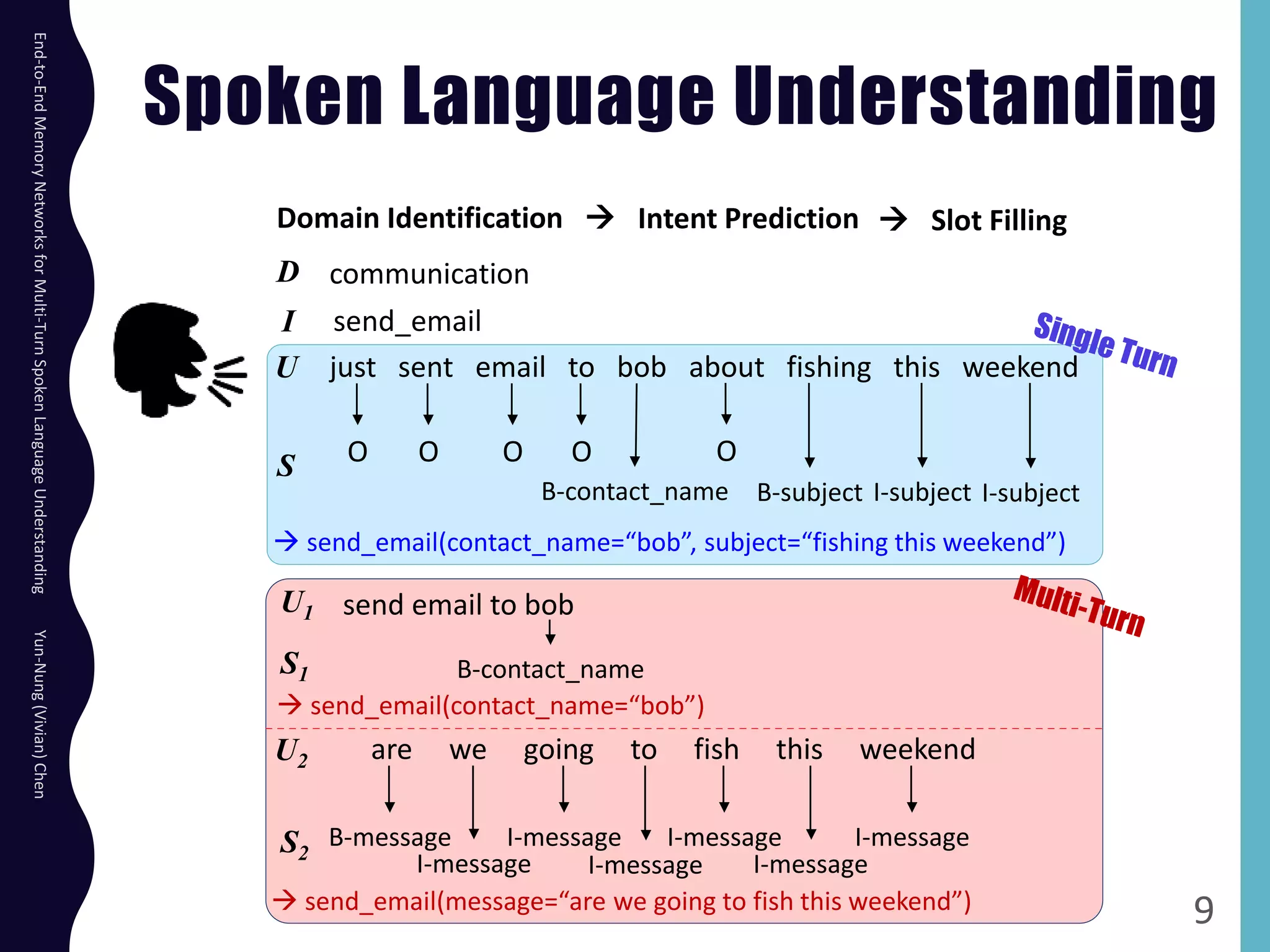

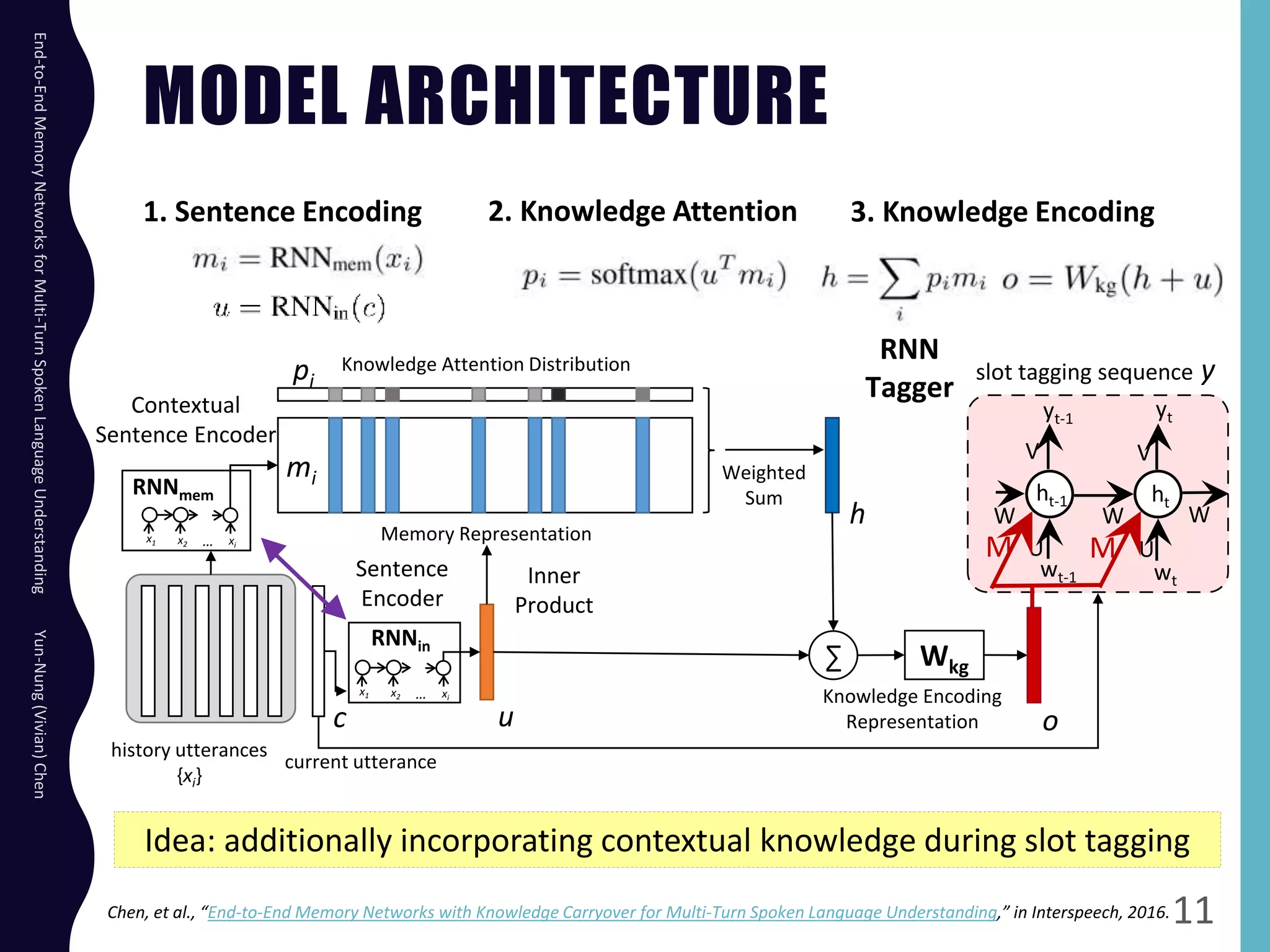
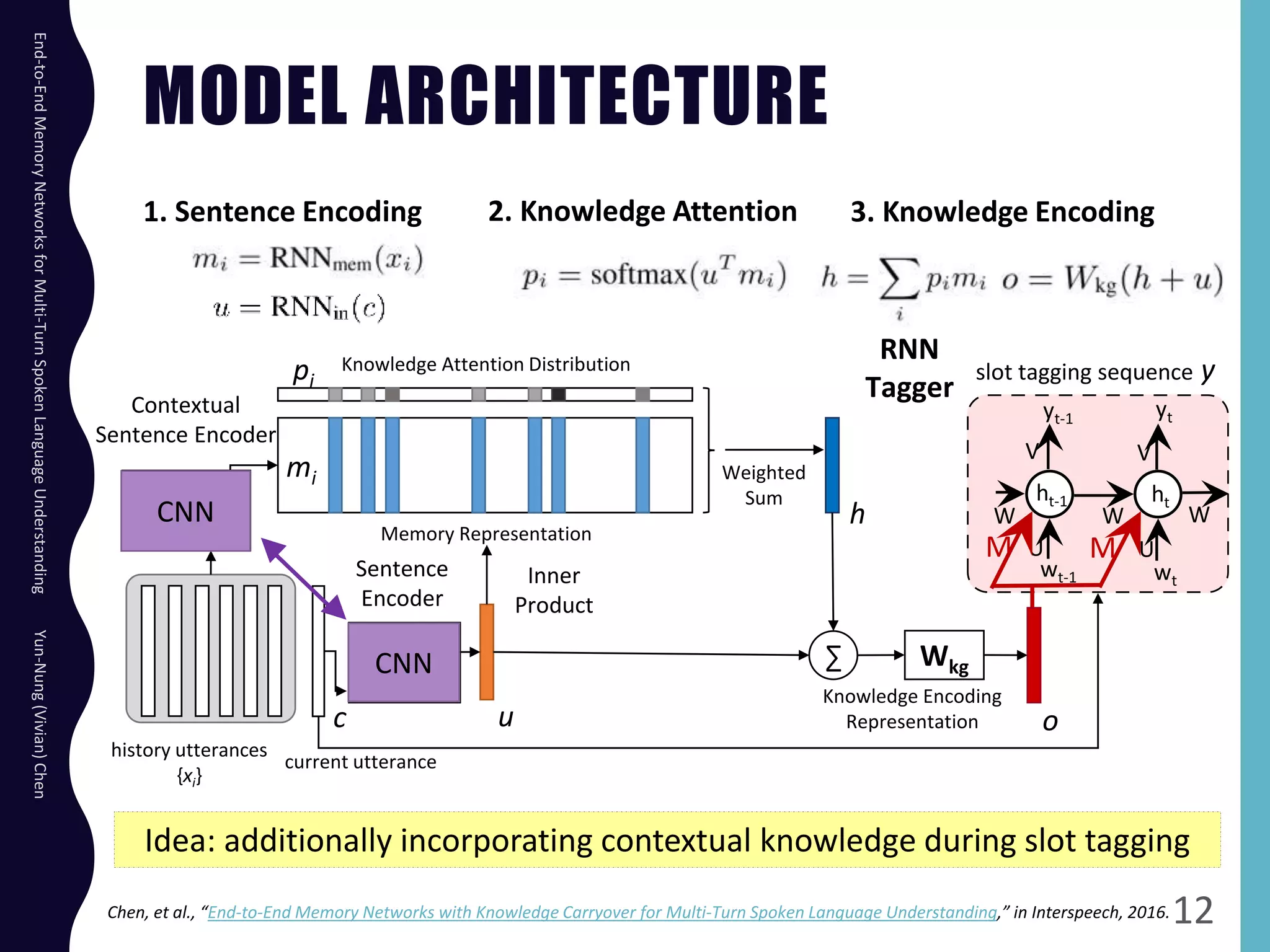


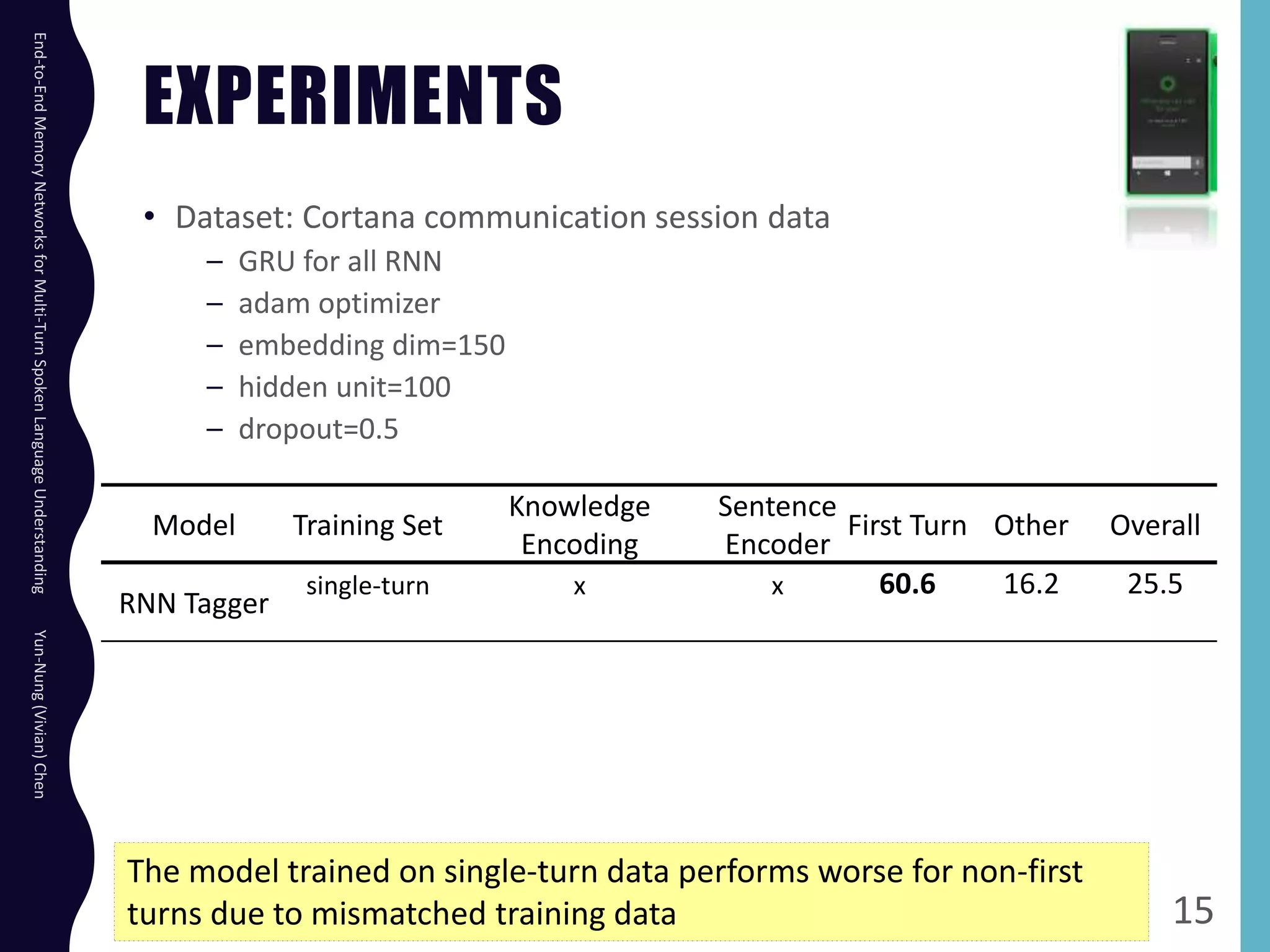
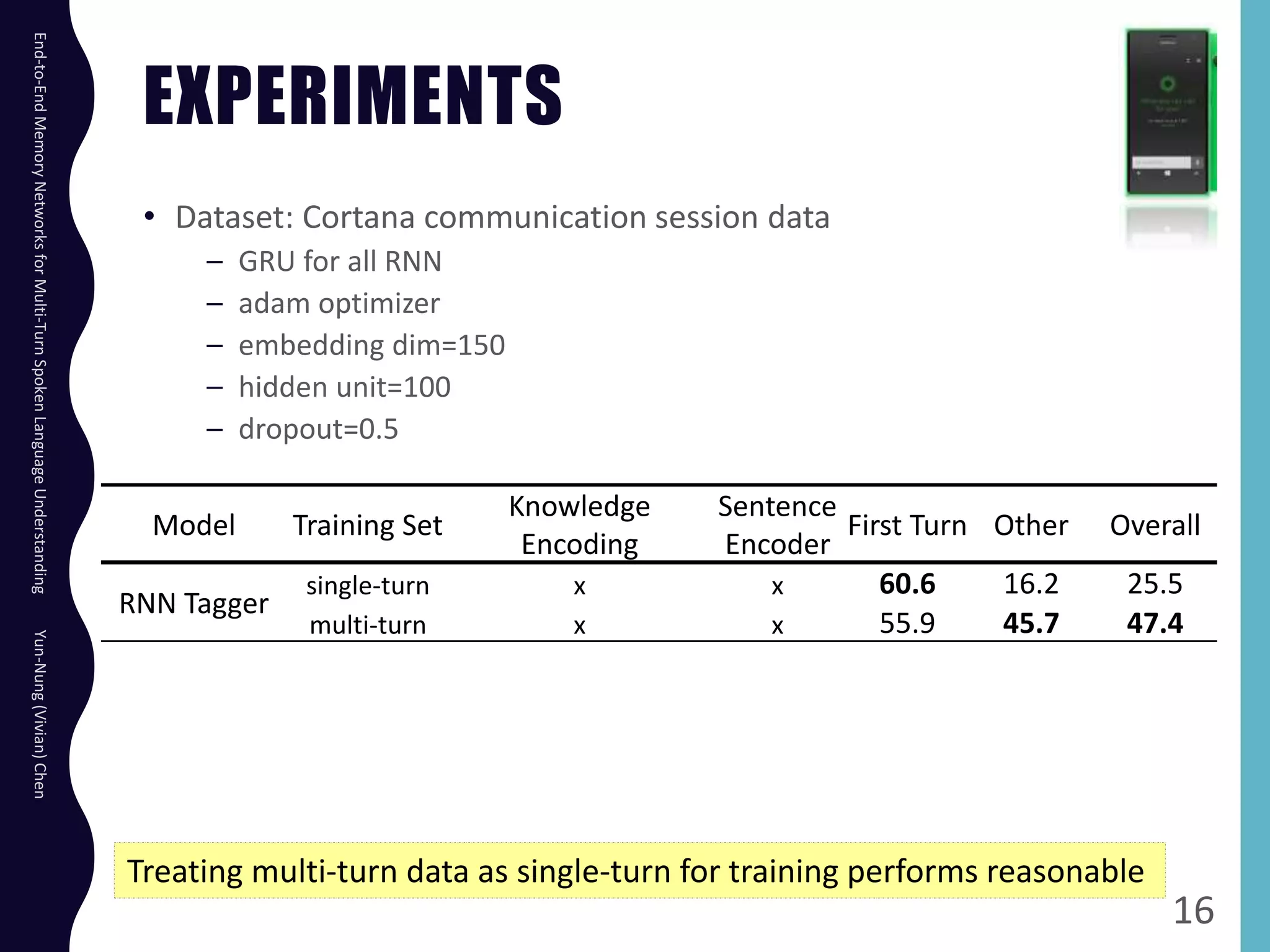
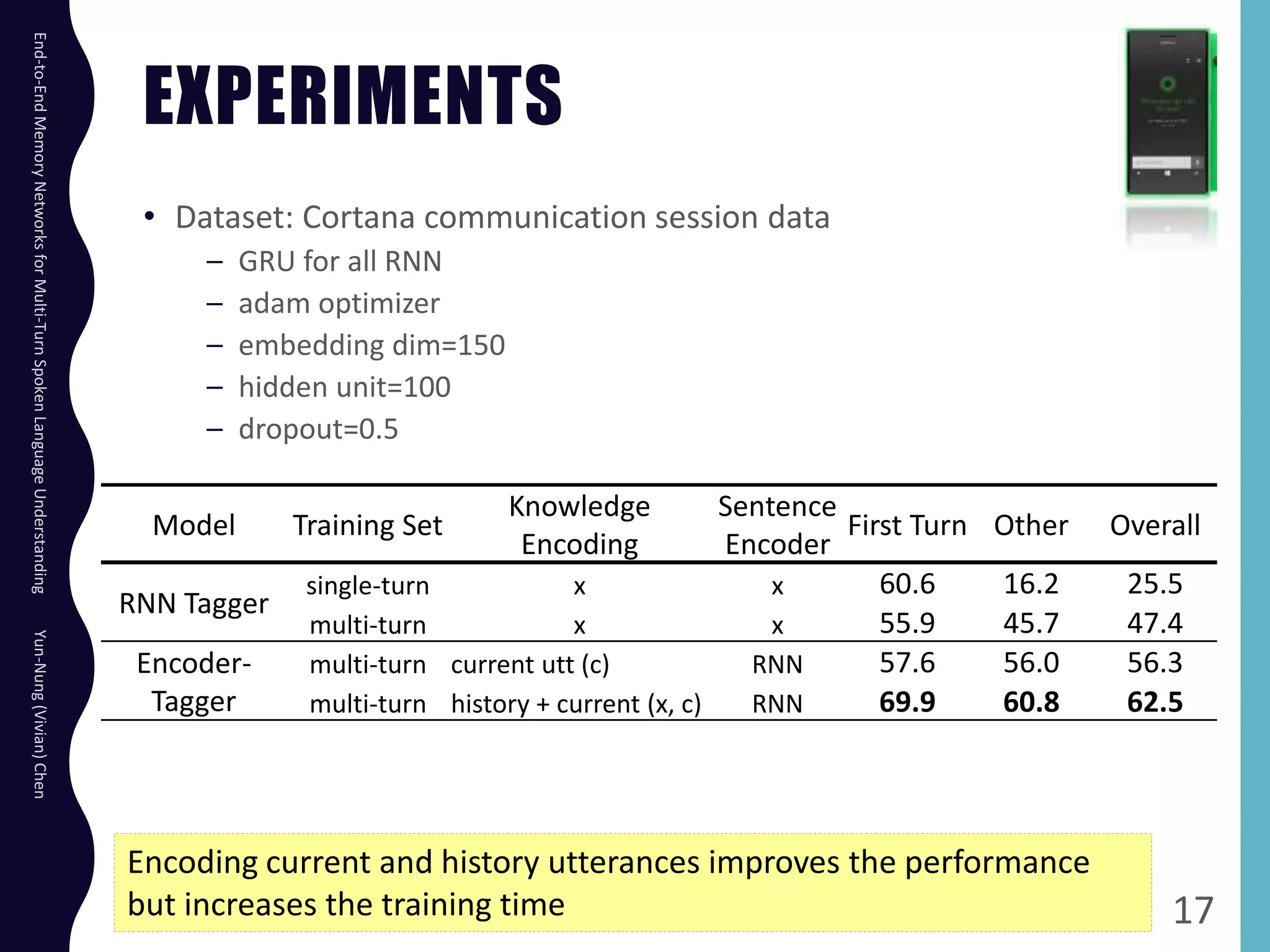
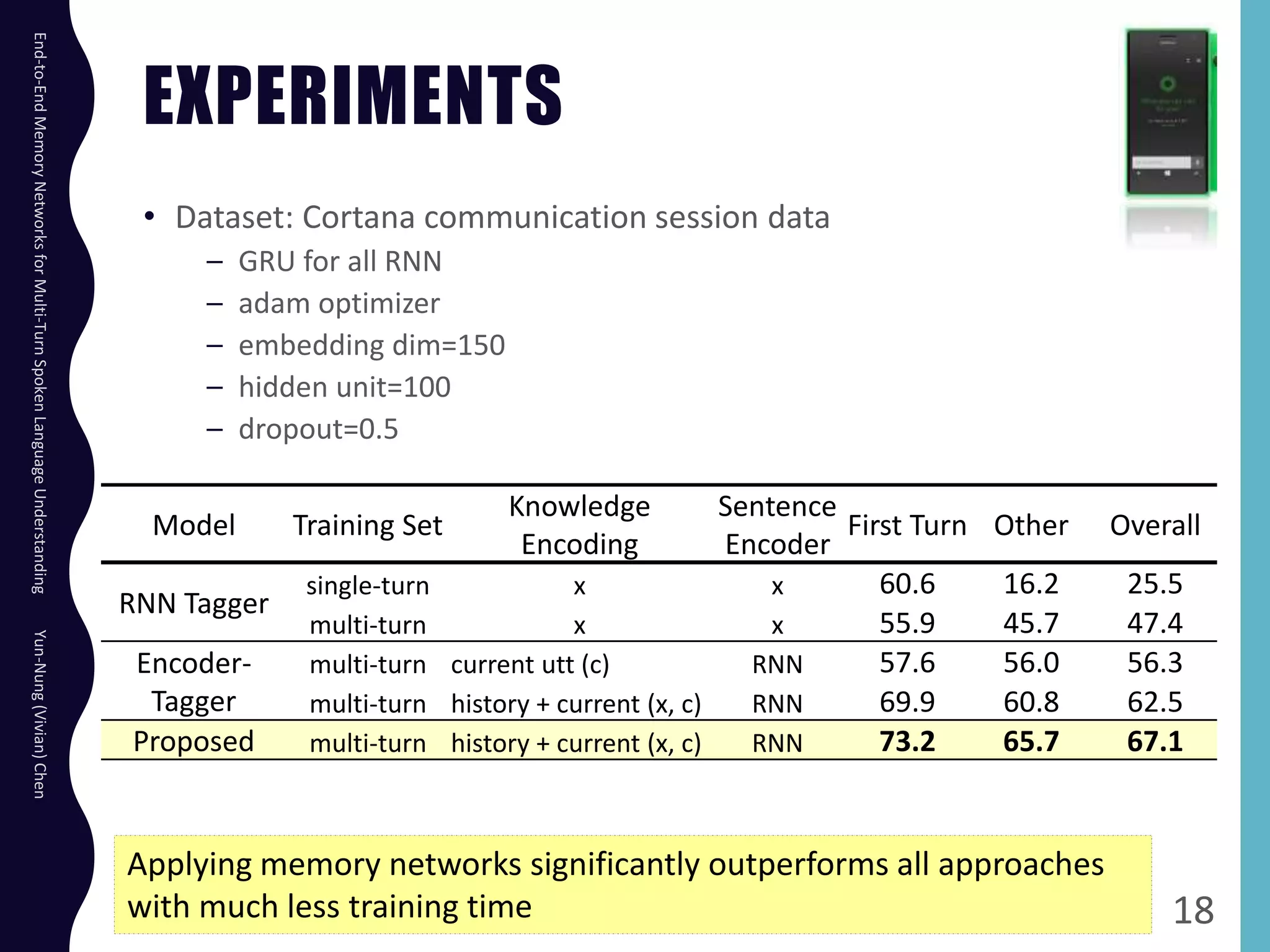
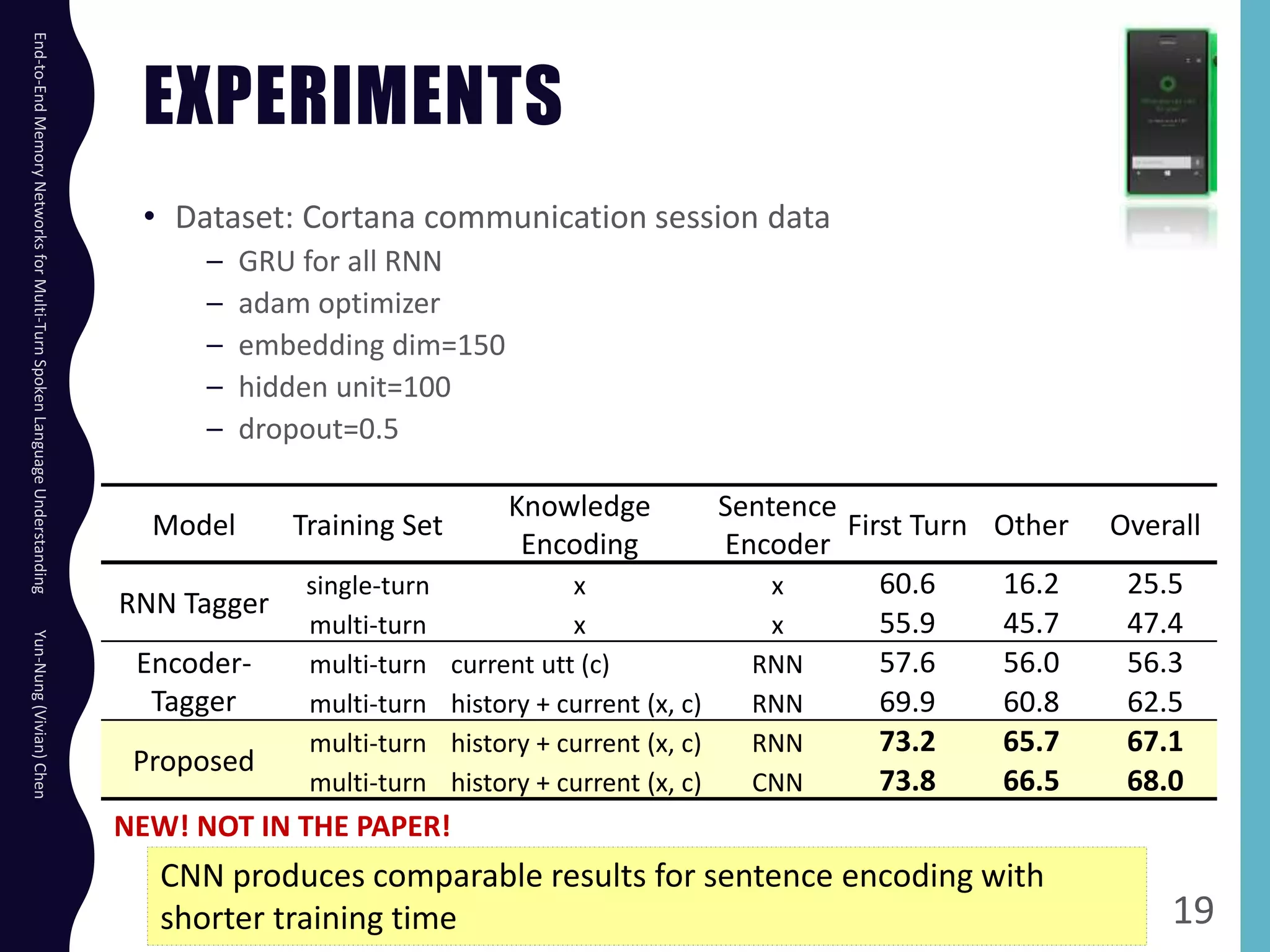





The document describes an end-to-end memory network model for multi-turn spoken language understanding. The model encodes context from previous utterances using an attention mechanism over the memory of past utterances. It then performs slot tagging on the current utterance incorporating the contextual knowledge. Experiments on a Cortana dataset show the model outperforms alternatives, achieving 67.1% accuracy by encoding both history and current utterances with the memory network.

































![[D2CAMPUS] Algorithm tips - ALGOS](https://cdn.slidesharecdn.com/ss_thumbnails/algospart1-d2-170223060957-thumbnail.jpg?width=640&height=640&fit=bounds)

![[D2 CAMPUS] 분야별 모임 '보안' 발표자료](https://cdn.slidesharecdn.com/ss_thumbnails/random-170117071928-thumbnail.jpg?width=640&height=640&fit=bounds)





![[222]대화 시스템 서비스 동향 및 개발 방법](https://cdn.slidesharecdn.com/ss_thumbnails/222-150915011307-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[系列活動] 文字探勘者的入門心法](https://cdn.slidesharecdn.com/ss_thumbnails/textmininghandout-170320140215-170327095320-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D2 CAMPUS] 숭실대 SCCC 프로그래밍 경시대회 문제 풀이](https://cdn.slidesharecdn.com/ss_thumbnails/random-161228045531-thumbnail.jpg?width=640&height=640&fit=bounds)






















![[BDD 2025 - Full-Stack Development] The Modern Stack: Building Web & AI Appli...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-themodernstackbuildingwebaiapplicationswithserverless-251124030844-388cf04f-thumbnail.jpg?width=640&height=640&fit=bounds)

![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)










![[BDD 2025 - Mobile Development] Mobile Engineer and Software Engineer: Are we...](https://cdn.slidesharecdn.com/ss_thumbnails/md-mobileengineerandsoftwareengineerarewestillrelevantsidiqpermana-251127010650-55224ef1-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Artificial Intelligence] Building AI Systems That Users (and Comp...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingaisystemsthatusersandcompanieslove-251124030845-038f7732-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DevFest Strasbourg 2025] - NodeJs Can do that !!](https://cdn.slidesharecdn.com/ss_thumbnails/devfeststrasbourg2025-nodejscandothat-251127142731-da65b6fd-thumbnail.jpg?width=640&height=640&fit=bounds)
