Downloaded 46 times



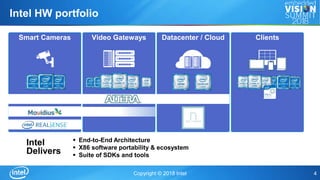

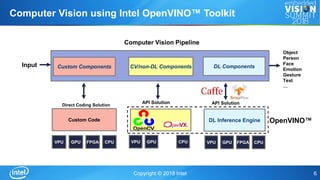
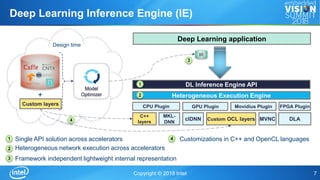









The document discusses Intel's OpenVINOTM toolkit, which enables cross-platform deep learning applications. The toolkit provides a development environment for high performance computer vision and deep learning inference. It allows applications to run on multiple Intel accelerators with a single application binary and without retraining models. This allows for faster time to market, cross-platform portability, and future-proofing of applications.



































































